Embeddings
O que é Embedding?
Embedding é a técnica de transformar dados (como textos, imagens ou áudios) em vetores numéricos — ou seja, listas de números que representam o significado daquele conteúdo.
Na prática, isso permite que sistemas consigam:
- Entender contexto (não só palavras exatas)
- Comparar conteúdos semanticamente
- Usar dados em modelos de Inteligência Artificial
Pense em como traduzir texto para uma “linguagem matemática” que a máquina consegue interpretar.
Quando usar Embeddings?
Use embeddings quando você precisar:
- Busca semântica: Encontrar conteúdos similares pelo significado, não apenas por palavras iguais.
- Comparação de conteúdo: Identificar similaridade entre textos diferentes (ex: recomendações, clustering).
- Aplicações de IA:
- Alimentar: Chatbots, Sistemas de recomendação ou Classificações inteligentes.
Porque tantos modelos de embeddings?
Nem todo dado é igual — e por isso existem diferentes modelos de embedding.
Cada modelo é treinado para capturar tipos específicos de informação e contexto, garantindo melhores resultados dependendo do seu caso de uso. A escolha do modelo impacta diretamente a qualidade da busca, comparação e respostas da IA
tipos de modelos:
1 - Multi-modal Modelo capaz de entender texto e imagem no mesmo espaço semântico.
Principais pontos:
- Permite comparar imagem ↔ texto diretamente
- Possibilita busca de imagens por descrição textual
- Trabalha com múltiplos formatos de dados
Quando usar:
- Catálogos de produtos com imagens
- Busca visual
- Aplicações que combinam imagem e texto
2 - Multi-language Modelo que entende múltiplos idiomas dentro do mesmo contexto semântico.
Principais pontos:
- Palavras com mesmo significado ficam próximas, mesmo em idiomas diferentes
- Permite busca e comparação entre línguas
- Elimina necessidade de tradução prévia
Quando usar:
- Sistemas globais
- Produtos com usuários internacionais
- Busca em múltiplos idiomas
3 - Text Embeddings (padrão) Modelo focado em interpretação e comparação de texto.
Principais pontos:
- Identifica similaridade semântica (não apenas palavras iguais)
- Base para busca semântica e RAG
- Mais utilizado na maioria dos casos
Quando usar:
- Chat com documentos
- Busca inteligente
- Sistemas de recomendação
- Análise de texto
Como criar Embeddings na Plataforma Carol
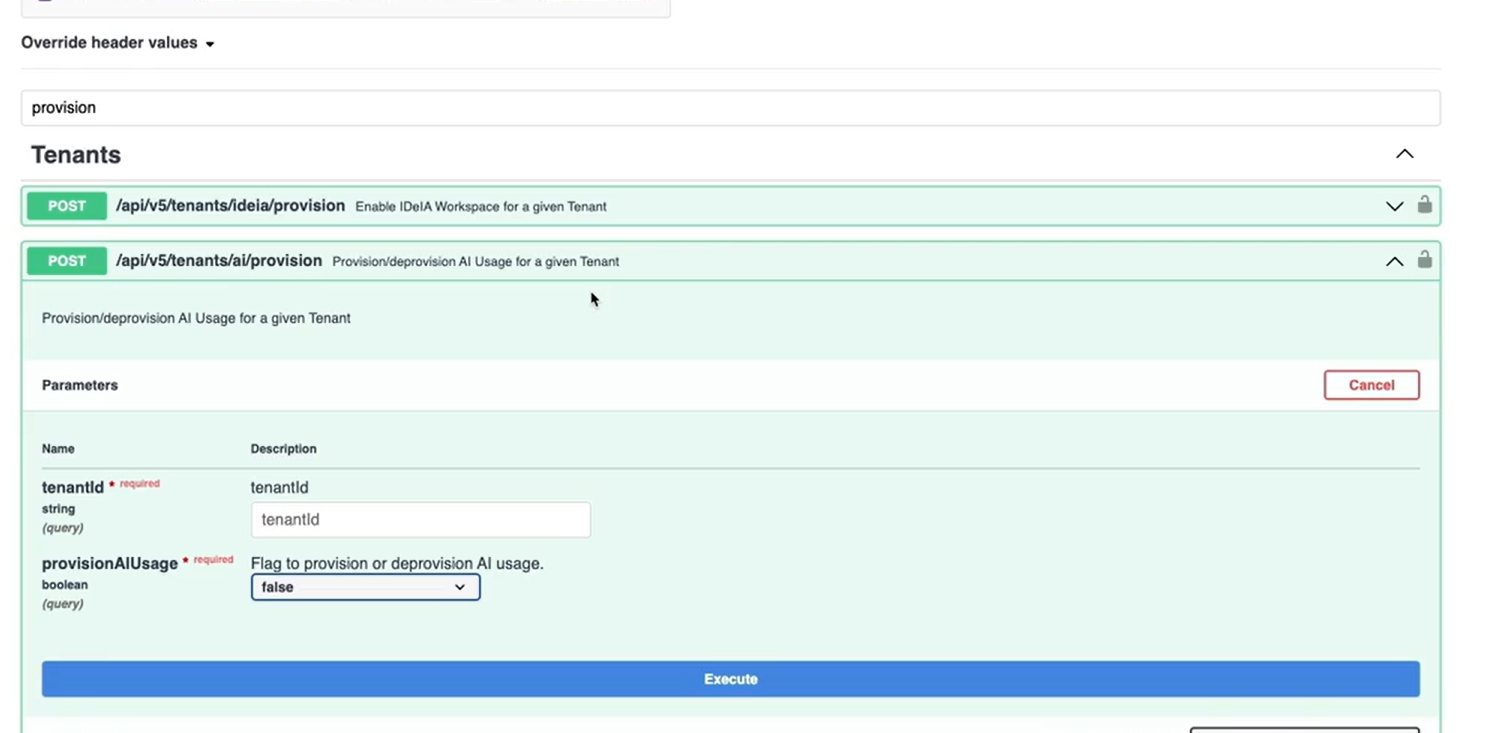
1. Ativar o AI Provisioning Antes de tudo, é necessário habilitar o uso de IA na sua tenant.
Pré-requisito Você precisa ter a role: Org Admin Caso não tenha, solicite a ativação via issue em nosso projeto do Jira
Como fazer Via Swagger, execute o endpoint:

POST /v1/tenant/{mdmTenantID}/ai/provision
Parâmetros:
- mdmTenantID: ID da sua tenant
- provision AI usage: true
Resultado
- Será criada uma task de provisionamento
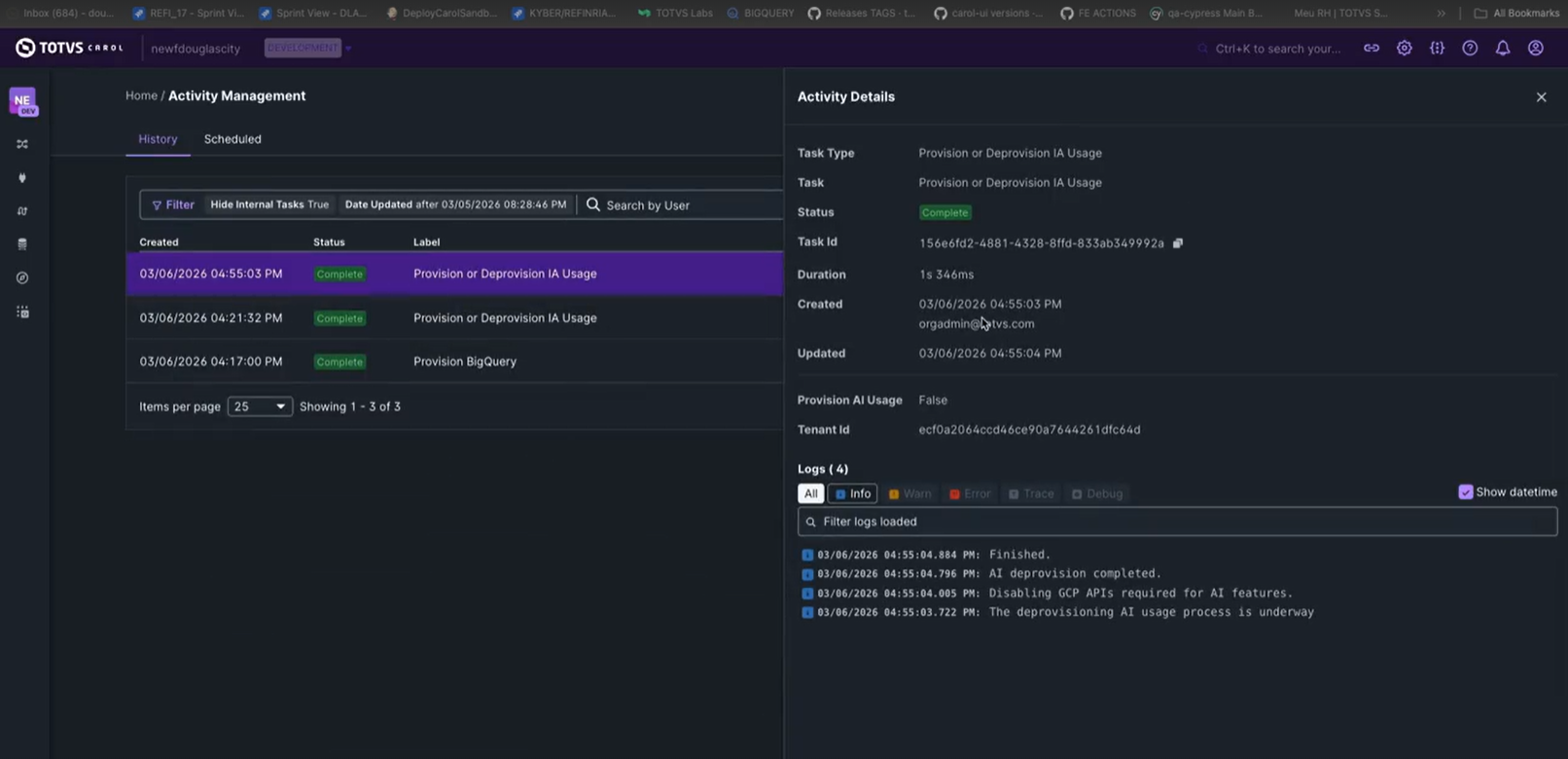
- Sua tenant ficará habilitada para uso de modelos de IA
2. Entendendo o Endpoint Remoto
Após o provisionamento, entra o conceito de Remote Endpoint.
O que é isso?
É o mecanismo que permite ao BigQuery chamar modelos de IA externos (Google) diretamente,ou seja:
- O processamento continua no seu ambiente Big Query, mas o modelo de IA é executado remotamente na Google.
- A sua tenant será responsável financeira pelo uso de recursos de AI
O que ele faz na prática?
O Remote Endpoint permite:
- Gerar embeddings diretamente via SQL
- Chamar modelos do Vertex AI sem sair do BigQuery
- Escolher diferentes modelos conforme o seu caso de uso
Como criar os modelos:
Para utilizar embeddings, você precisa primeiro criar um modelo remoto no BigQuery, que será responsável por apontar para o modelo do Vertex AI.
- recomendamos que esse modelo seja criado dentro de um dataset custom_data
Estrutura do comando:
CREATE OR REPLACE MODEL
`{PROJECT_ID}.{TENANT_ID}.embedding_model`
REMOTE WITH CONNECTION
`{PROJECT_ID}.us.conn_carol_cloud_resource`
OPTIONS (
ENDPOINT = '{MODELO_ESCOLHIDO}'
);
O que cada parte faz?
- MODEL: Nome do modelo que será criado no BigQuery
- REMOTE WITH CONNECTION: Define a conexão com o Vertex AI (pré-configurada)
- ENDPOINT Define qual modelo de embedding será utilizado
Exemplo real:
CREATE OR REPLACE MODEL
`carol-6f77a449debc4270ac8b.custom_data.embedding_model`
REMOTE WITH CONNECTION
`carol-6f77a449debc4270ac8b.us.vertex_remote_conn`
OPTIONS (
ENDPOINT = 'text-embedding-004'
);
O que esse comando cria?
Essa ação cria um modelo remoto dentro do BigQuery, esse modelo funciona como uma ponte para o Vertex AI e permite que você use funções como: ML.GENERATE_EMBEDDING ,ou seja, você passa a conseguir gerar embeddings diretamente via SQL.
Escolha do modelo (muito importante)
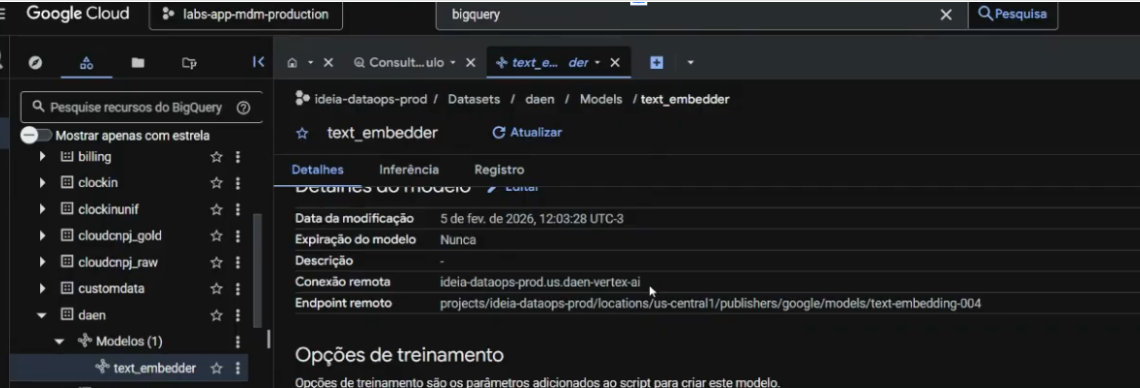
No exemplo acima, utilizamos:
text-embedding-004
Esse modelo é: indicado para texto
Muito utilizado em: busca semântica, similaridade de documentos e chatbots
Documentação oficial de modelos
Você pode consultar os modelos disponíveis e suas indicações aqui: link
Como os modelos de embedding funcionam na Carol
Na plataforma Carol, esse processo já é abstraído após os passos anteriores,no exemplo da imagem acima, ele ficou disponível como: ideia-dataops-prod.daen.text_embedder.
Gerando Embeddings em Pipelines ou Carol apps
Após a habilitação dos modelos em sua tenant, é possível criar os embedding em sua pipeline e em seus Carol apps.
O que precisa ser feito?
- Escolher a coluna de texto que contém os dados a serem vetorizados. (ex: content)
- Criar uma nova coluna com o embedding
- Chamar a função de ML
exemplo no git de chamada de modelo em pipelines:
exemplo no git de chamada de modelo em Carol apps:
Exemplo Bloco de geração de embeddings:
embeddedData AS (
SELECT
pd.*,
emb.ml_generate_embedding_result AS embedded_content
FROM ML.GENERATE_EMBEDDING(
MODEL `ideia-dataops-prod.daen.text_embedder`,
(SELECT content FROM processedData),
STRUCT(TRUE AS flatten_json_output, 'RETRIEVAL_DOCUMENT' AS task_type)
) AS emb
Exemplo explicado
-
Função principal: ML.GENERATE_EMBEDDING
Essa função:
- Recebe um texto
- Aplica um modelo de IA
- Retorna um vetor numérico
1. Modelo utilizado
MODEL `ideia-dataops-prod.daen.text_embedder`
Define qual modelo será usado para gerar os embeddings.
2. Dados de entrada
(SELECT content FROM processedData)
Indica qual coluna será transformada em embedding, neste caso: content
3. Configurações STRUCT( TRUE AS flatten_json_output, 'RETRIEVAL_DOCUMENT' AS task_type ) flatten_json_output: organiza a saída task_type: define o contexto do embedding 'RETRIEVAL_DOCUMENT' = otimizado para busca semântica
4. Resultado
emb.ml_generate_embedding_result AS embedded_content
Cria uma nova coluna: embedded_content
Tipo: vetor (array numérico)
5. Junção com dados originais
INNER JOIN processedData pd
ON pd.content = emb.content
Isso garante que o embedding volte junto com os dados originais e que nenhuma informação seja perdida.
Query completa com exemplo de embedding (exemplo)
WITH carol_documentation_contents_carolembbededdocumentations AS (
SELECT
content,
link,
*--metadata--*
FROM (
SELECT *
FROM `carol-625aa8edd1264e34b7fe.625aa8edd1264e34b7fe2aec00f322a6.stg_carol_docs_carol_documentation_contents`
*--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))*
QUALIFY ROW_NUMBER() OVER (PARTITION BY mdmId ORDER BY _ingestionDatetime DESC, mdmCounterForEntity DESC) = 1
) AS stg
),
processedData AS (
SELECT *
FROM carol_documentation_contents_carolembbededdocumentations
),
embeddedData AS (
SELECT
pd.*,
emb.ml_generate_embedding_result AS embedded_content
FROM ML.GENERATE_EMBEDDING(
MODEL `ideia-dataops-prod.daen.text_embedder`,
(SELECT content FROM processedData),
STRUCT(TRUE AS flatten_json_output, 'RETRIEVAL_DOCUMENT' AS task_type)
) AS emb
INNER JOIN processedData pd
ON pd.content = emb.content
)
SELECT
content AS content_1,
link,
embedded_content,
__mdmId,
__mdmTenantId,
__mdmCounterForEntity,
__mdmStagingRecordIds,
__mdmSourceEntityNames,
__mdmTaskId,
__mdmSourceOperationTaskId
FROM embeddedData AS stg
Com a coluna vetorizada já é possível utilizá-la e explorar o potencial, salvando seu dado em em Datamodel com o baixa latência ativada.
Em breve
- Como usar seu campo vetorizado: tools, data service, mcp server.