Campos customizados
Objetivo
O desenvolvimento possui como objetivo integrar atributos específicos para o aplicativo na tenant unificada, permitindo assim que pipelines que exploram atributos específicos para o Carol App (e na instalação do Protheus) consigam carregar atributos específicos durante a execução da pipeline de processamento de dados (SQL Processing).
Essa característica é utilizada para o aplicativo da Gesplan, que utiliza pipelines de processamento de dados que lê atributos customizados da instalação do Protheus e para o Carol App.
Esse característica ocorre porque o Carol App integra os dados para a tenant unificada especificados no schema do dado na tenant DEV. Com isso, apenas atributos conhecidos para o Carol App são disponibilizados na tenant unificada.
Esse desenvolvimento vai disponibilizar um mapa (chave/valor) de atributos específicos para o Carol App na tenant unificada, permitindo à pipeline a leitura desses dados diretamente na tenant unificada.
Inicialização das tenants
Unified Tenant
A habilitação da funcionalidade ocorre através da tenant unificada para que apenas Carol Apps com essa necessidade integrem dados adicionais para a Tenant Unificada.
Habilitar flag custom fields
O primeiro passo é habilitar a configuração no documento tenant da tenant unificada habilitando a integração de atributos customizados.
curl 'https://masteringcarol.carol.ai/api/v1/tenants/662bfc9ef69e4a3387f361506113d9c3' \
-X 'PUT' \
-H 'accept: application/json' \
-H 'authorization: TOKEN_HERE' \
-H 'content-type: application/json' \
--data-raw '{"mdmEnableCustomFieldsOnStaging": true}'
{"success":true}
Gerar arquivo avro
Após habilitar a flag para cópia dos atributos custom, devemos gerar o avro schema da tenant unificada para forçar a criação dos novos atributos. O comando abaixo vai gerar o avro schema da tenant como um todo, incluindo staging tables e data models.
curl "https://api.carol.ai/api/v1/admin/avroschemas/generation?forceCreate=true&forceDelete=true" -H "accept: application/json" -H "content-type: application/json" -H "authorization: TOKEN" --data-binary "[""662bfc9ef69e4a3387f361506113d9c3""]" --compressed
{"success":true}
O código 662bfc9ef69e4a3387f361506113d9c3 indica a tenant que terá o avro schema gerado. O comando acima deve ser executado com um usuário com a role Carol Admin.
Apenas staging tables terão o schema alterado, e vamos notar tasks como a abaixo na tenant unificada:
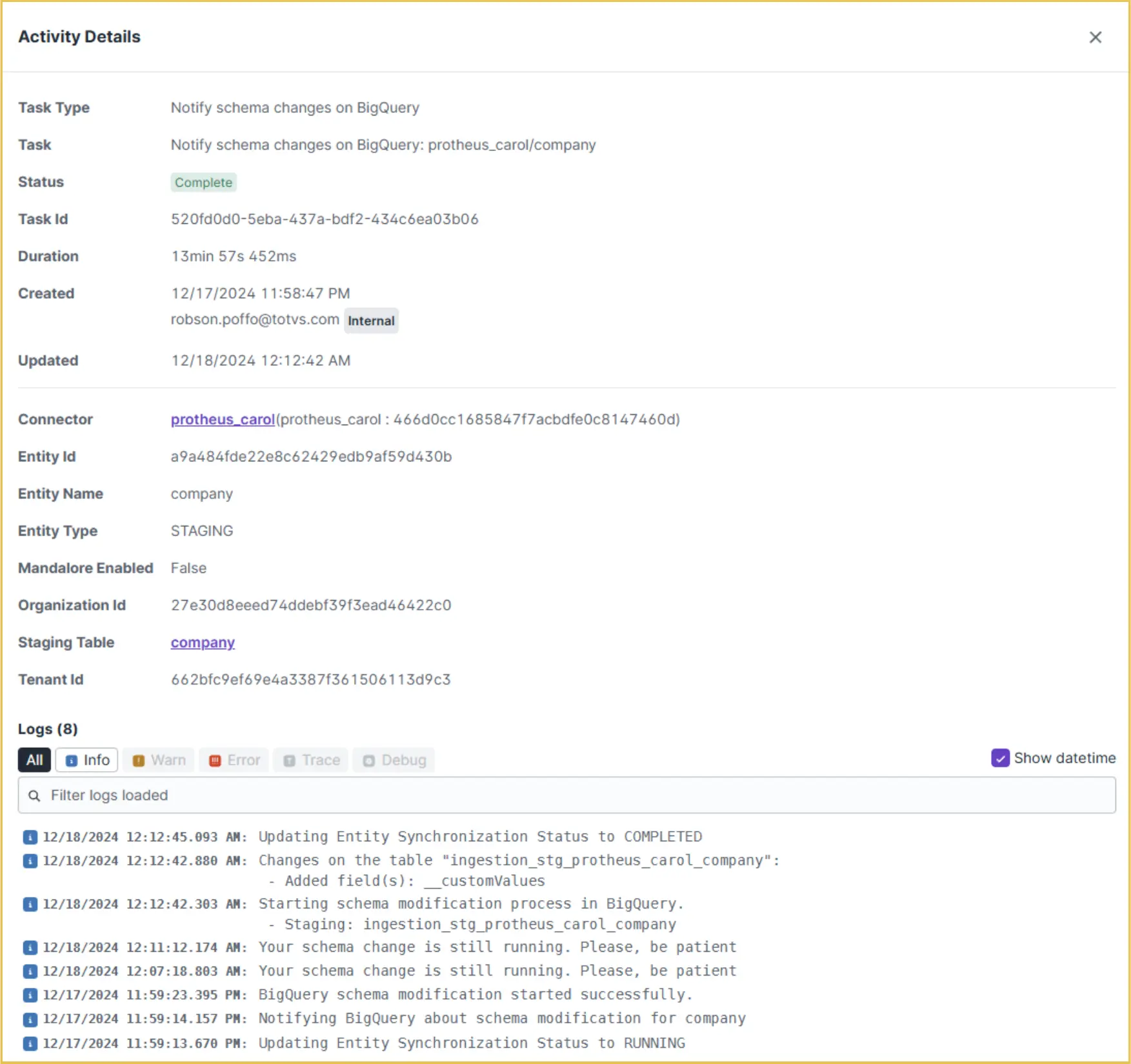
Destaque para a criação do atributo __customValues.
Cópia de dados tenant unificada
Após a habilitação do atributo para integrar atributos específicos para a tenant unificada e da geração do avro, devemos proceder com a cópia dos dados das tenants clientes para a tenant unificada, com o objetivo de alimentar o novo atributo (__customValues) com as colunas customizadas da tenant.
A cópia dos dados pode ser executada através da tenant DEV, no fluxo abaixo:
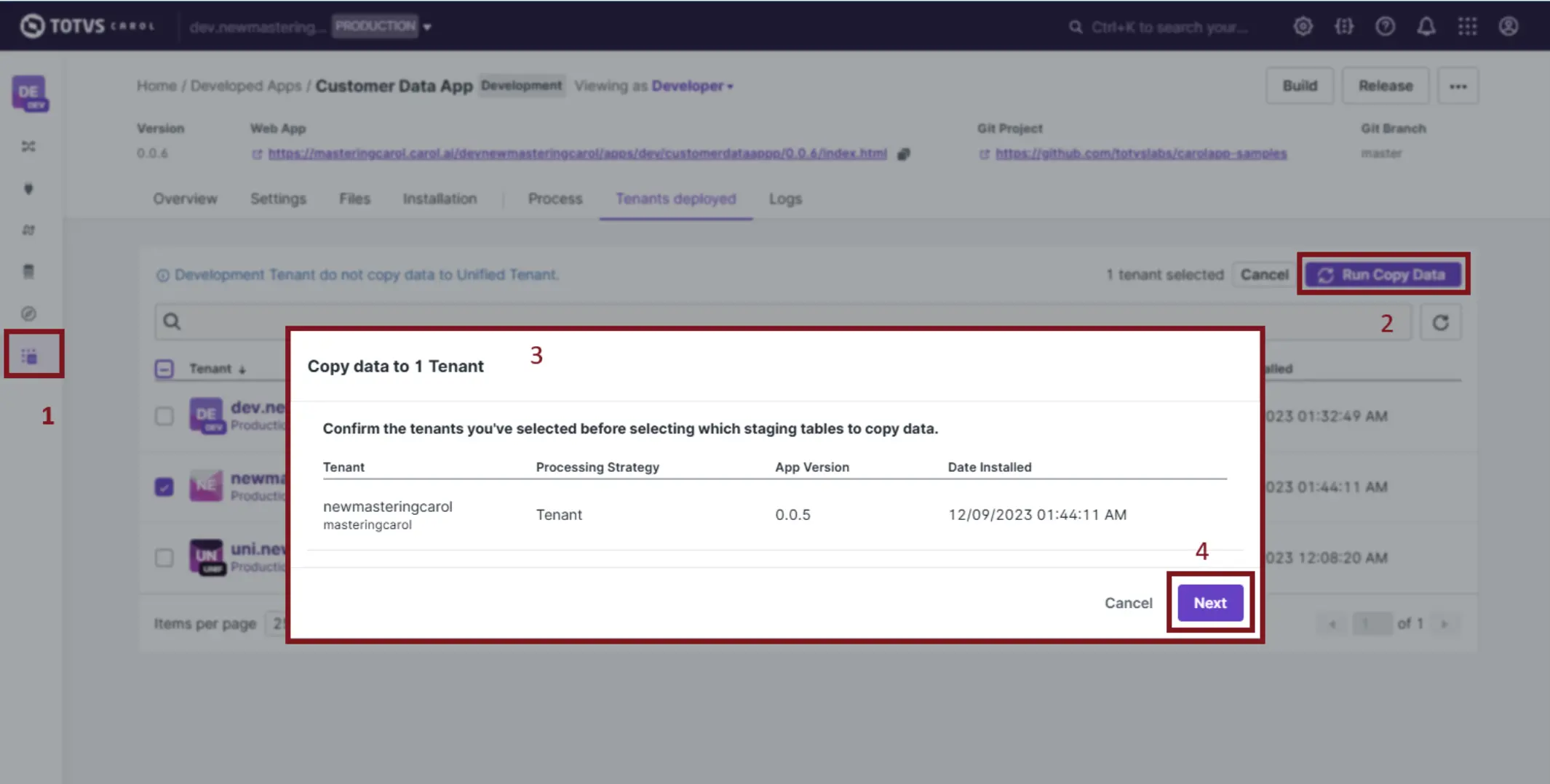
- Acesso o Carol App pelo menu lateral. Você pode iniciar a cópia dos dados apenas para tenants que a tenant DEV é desenvolvedora do Carol App.
- Clicar em Run Copy Data para abrir a caixa do processo de cópia de dados.
- Na tela que abriu, será exibido às tentantes que foram selecionadas na tela anterior.
- Deve ser clicado em Next para seguir para a tela de confirmação, visualizada abaixo.
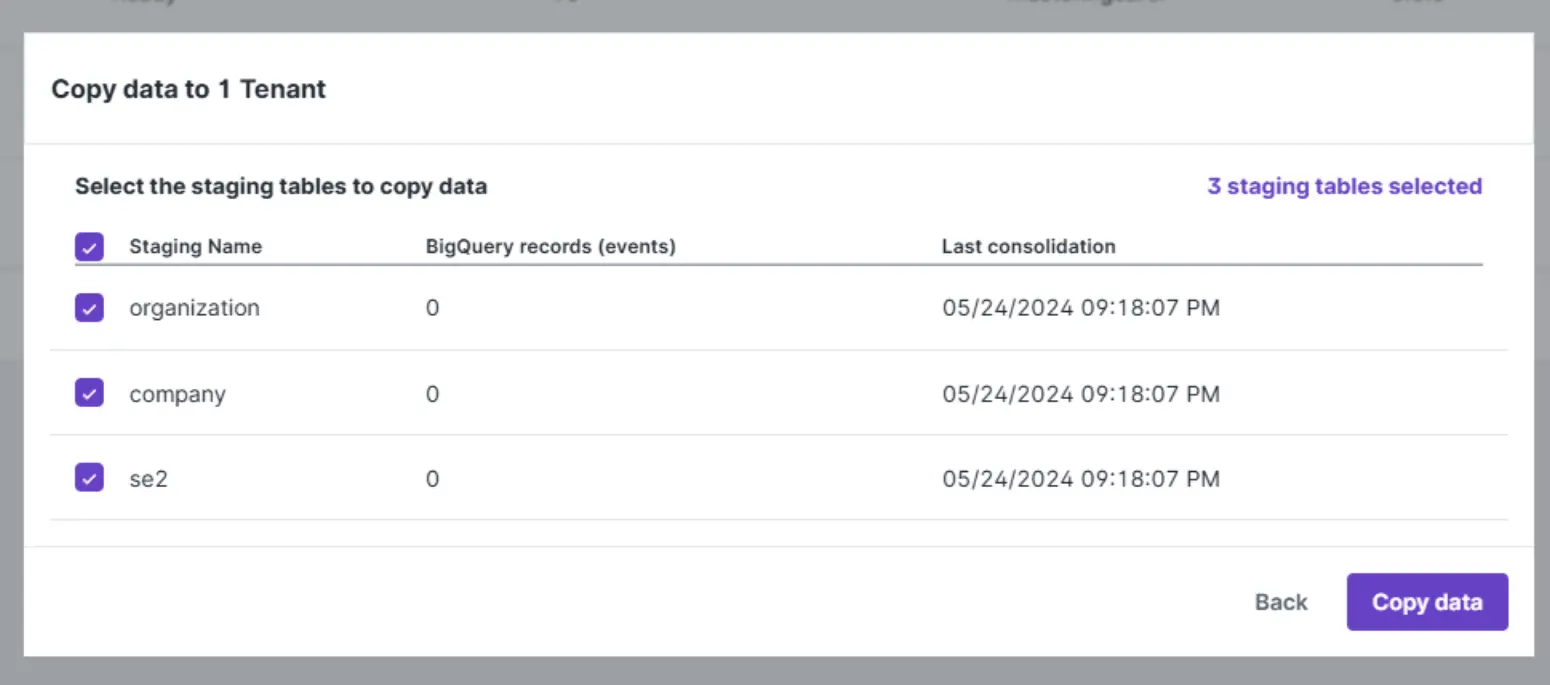
Nessa tela é possível selecionar e confirmar as entidades que serão copiadas para a tenant unificada.
Customer Tenant
Nenhuma inicialização em especial é necessária. Ao enviar os dados, automaticamente os dados serão copiados para a tenant unificada após a inicialização acima descrita.
Dados podem ser enviados normalmente, neste procedimento vamos simular com o comando abaixo:
curl -X 'POST' \
'https://api.carol.ai/api/v3/staging/tables/sa2?connectorId=b69624639ffe49c0b3303698d575adfb&returnData=false' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: TOKEN_HERE' \
-d '[{"a2_cod": "codeA", "a2_nome":"Cliente A", "customFieldA": "valor custom field A", "customFieldB": "valor custom field B"}]'
{"data":null,"message":null,"success":true}
Após a carga dos dados na tenant cliente, podemos observar a tenant unificada com as colunas específicas dentro do atributo __customValues:
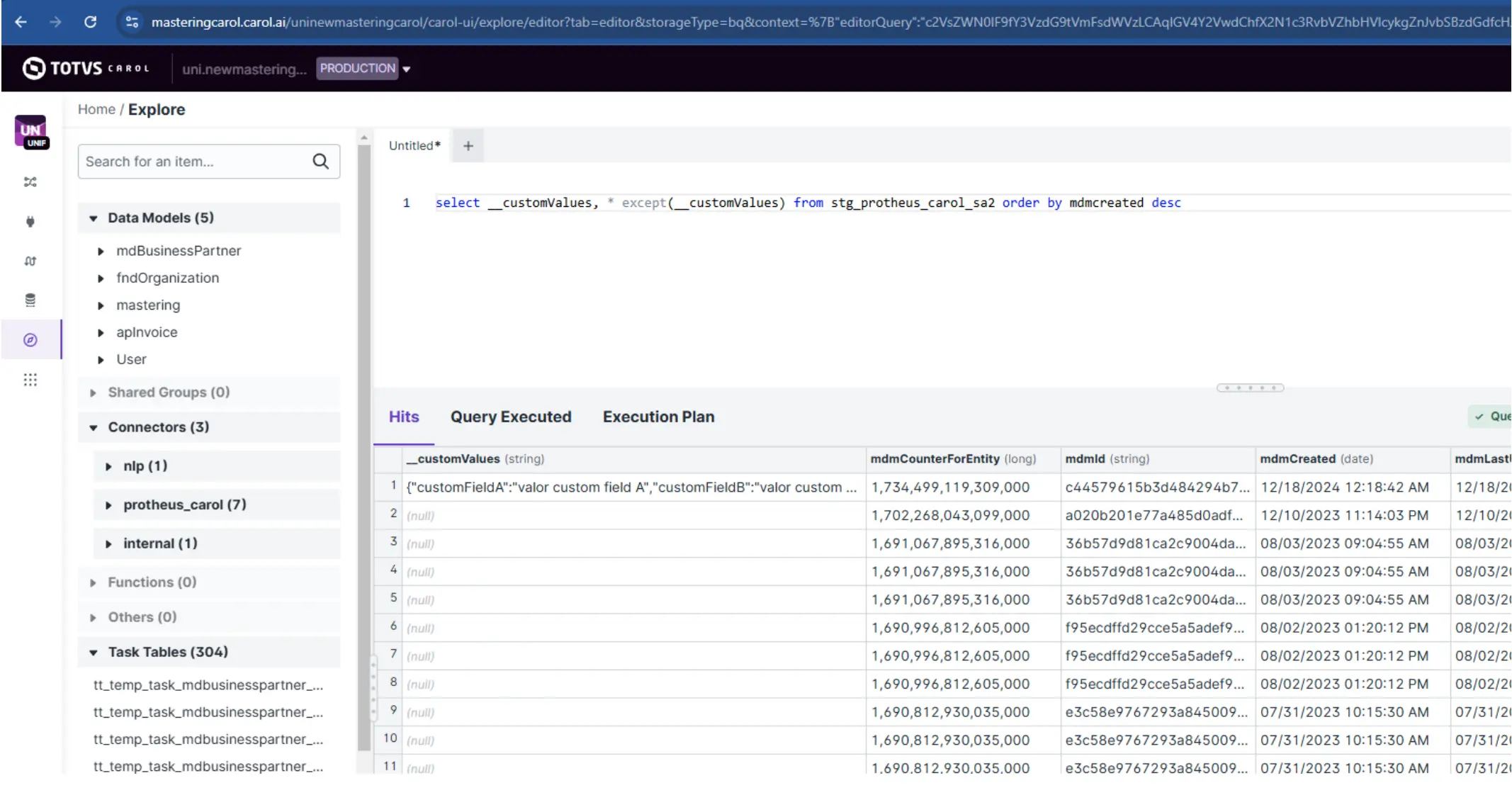
Processamento de dados com leitura de atributos específicos
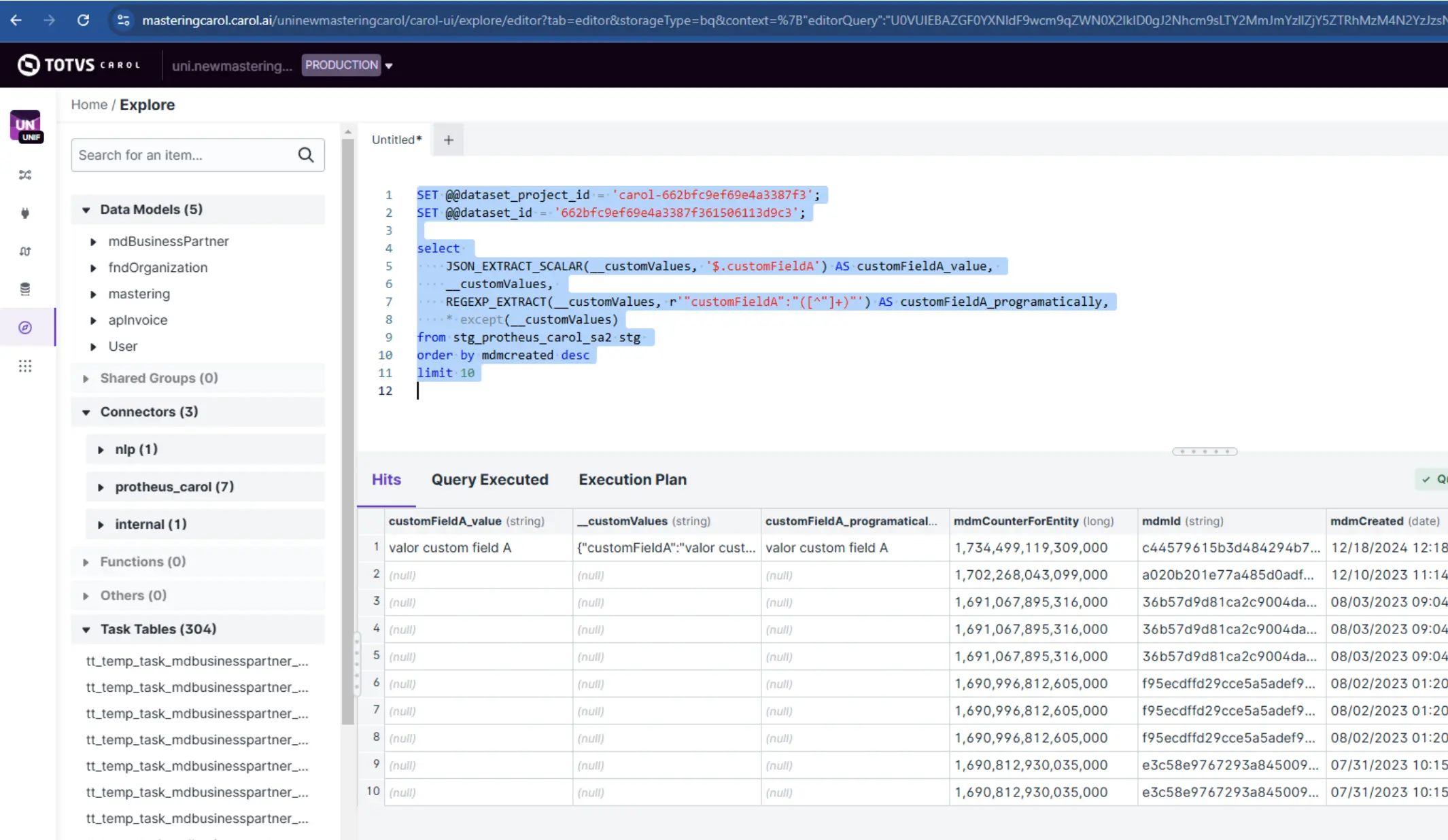
A pipeline de processamento de dados pode efetuar a carga de atributos de __customValues de forma programática, usando string, que é o mesmo processo que teremos lendo atributos dos settings de um Carol App:
SET @@dataset_project_id = 'carol-662bfc9ef69e4a3387f3';
SET @@dataset_id = '662bfc9ef69e4a3387f361506113d9c3';
select
JSON_EXTRACT_SCALAR(__customValues, '$.customFieldA') AS customFieldA_value,
__customValues,
REGEXP_EXTRACT(__customValues, r'"customFieldA":"([^"]+)"') AS customFieldA_programatically,
* except(__customValues)
from stg_protheus_carol_sa2 stg
order by mdmcreated desc
limit 10
Próximos passos
Já temos mapeado em roadmap a habilitação automática das tenants, fazendo com que os passos abaixo sejam executados de forma automática após habilitar a integração de atributos customizados na tenant unificada:
- Geração avro schema (criar atributos
__customValuesna tenant unificada) - Cópia de dados das tenants clientes para tenant unificada
Comparando performance pipelines
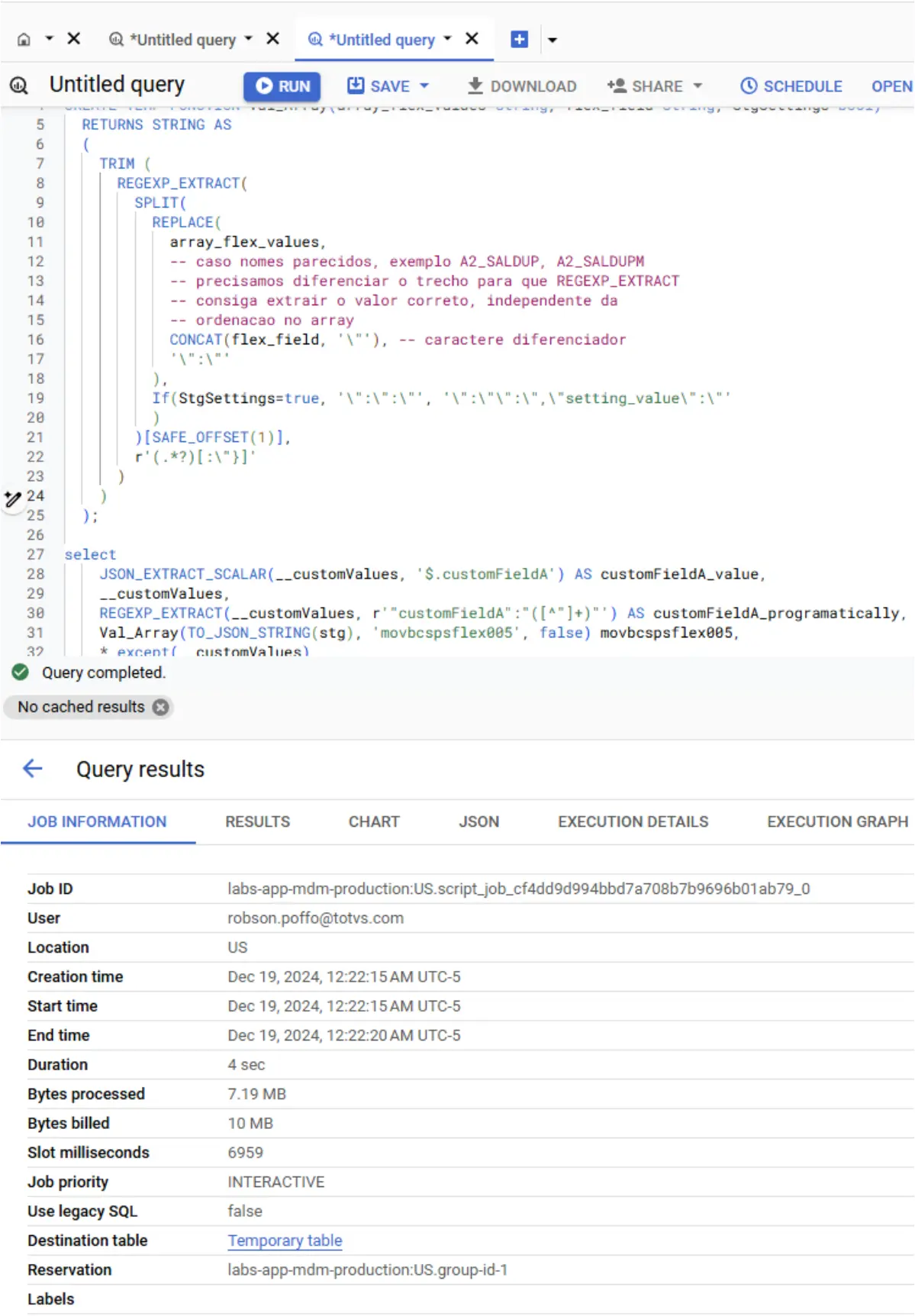
A pipeline atual da Gesplan utiliza duas funções para a leitura dos atributos específicos (encapsulado em uma função):
- Parse do registro para Json
- Regex na string:
SET @@dataset_project_id = 'carol-662bfc9ef69e4a3387f3';
SET @@dataset_id = '662bfc9ef69e4a3387f361506113d9c3';
CREATE TEMP FUNCTION Val_Array(array_flex_values string, flex_field string, StgSettings bool)
RETURNS STRING AS
(
TRIM (
REGEXP_EXTRACT(
SPLIT(
REPLACE(
array_flex_values,
-- caso nomes parecidos, exemplo A2_SALDUP, A2_SALDUPM
-- precisamos diferenciar o trecho para que REGEXP_EXTRACT
-- consiga extrair o valor correto, independente da
-- ordenacao no array
CONCAT(flex_field, '\"'), -- caractere diferenciador
'\":\"'
),
If(StgSettings=true, '\":\":\"', '\":\"\":\",\"setting_value\":\"'
)
)[SAFE_OFFSET(1)],
r'(.*?)[:\"}]'
)
)
);
select
JSON_EXTRACT_SCALAR(__customValues, '$.customFieldA') AS customFieldA_value,
__customValues,
REGEXP_EXTRACT(__customValues, r'"customFieldA":"([^"]+)"') AS customFieldA_programatically,
Val_Array(TO_JSON_STRING(stg), 'movbcspsflex005', false) movbcspsflex005,
* except(__customValues)
from stg_protheus_carol_sa2 stg
order by mdmcreated desc
A nova estratégia da tenant unificada para atributos customizados vai permitir aplicar diretamente a leitura via regex nos atributos específicos __customValues:
SET @@dataset_project_id = 'carol-662bfc9ef69e4a3387f3';
SET @@dataset_id = '662bfc9ef69e4a3387f361506113d9c3';
select
JSON_EXTRACT_SCALAR(__customValues, '$.customFieldA') AS customFieldA_value,
__customValues,
REGEXP_EXTRACT(__customValues, r'"customFieldA":"([^"]+)"') AS customFieldA_programatically,
* except(__customValues)
from stg_protheus_carol_sa2 stg
order by mdmcreated desc
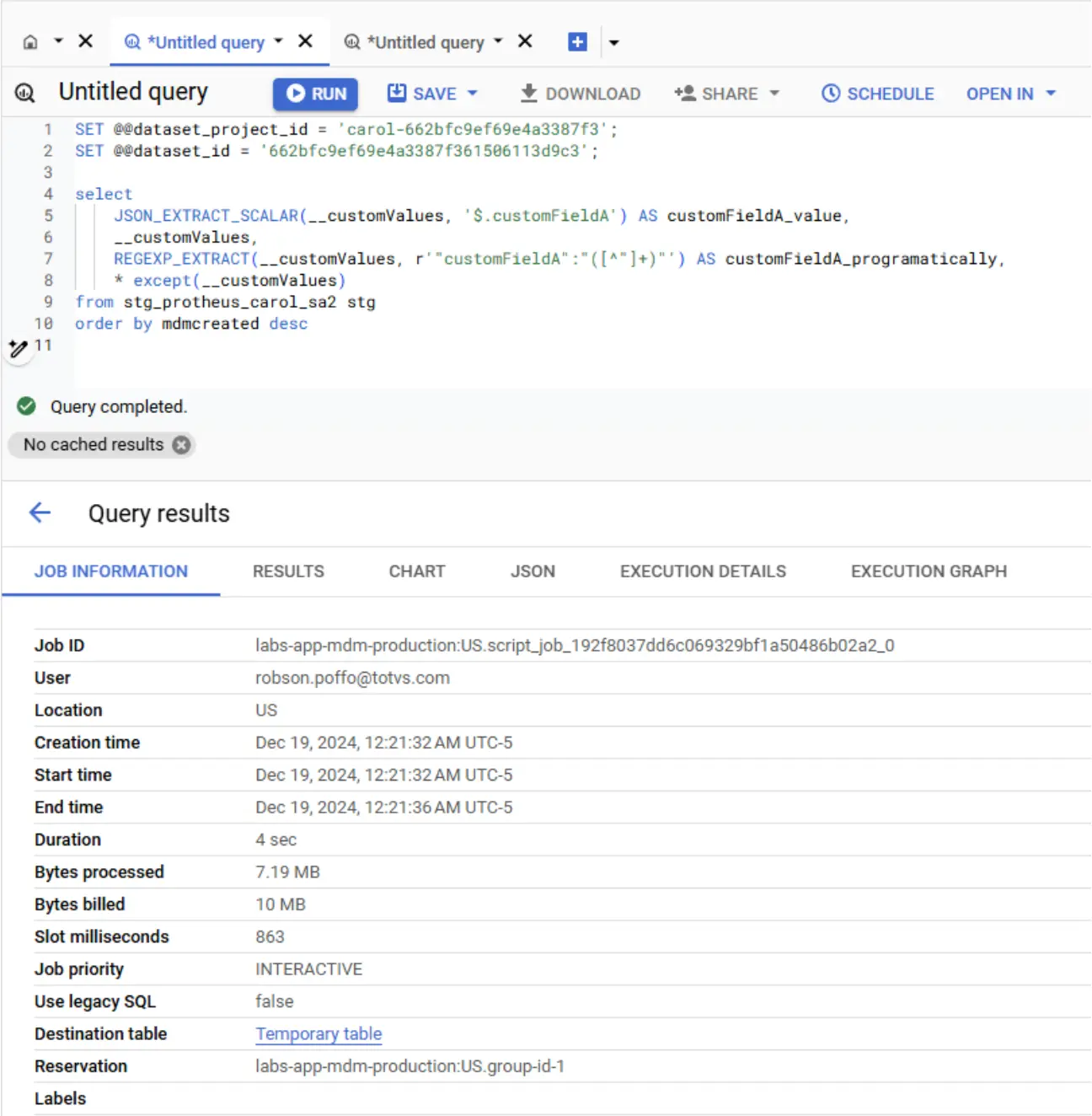
No exemplo acima, notamos que a query usando a regra anterior levou aproximadamente 6.900 milissegundos, enquanto a nova query levou aproximadamente 1.000 milisegundos.