Conceitos
TOTVS Carol
TOTVS Carol é a plataforma de dados e inteligência artificial da TOTVS. Desde 2015 ela vem sendo desenvolvida e aprimorada por nossos cientistas de dados, desenvolvedores e demais profissionais nos nossos Labs, no Brasil e nos Estados Unidos.
A plataforma é uma solução avançada de gestão de dados, capaz de se conectar à todas as suas fontes de dados, como ERPs, e reuni-las em um só lugar para analisar informações e apresentar resultados altamente fiéis que apoiem de forma veloz gestores na tomada de decisão.
Desta forma, TOTVS Carol viabiliza estratégias de rastreabilidade de informações, desenvolvimento e deploy de algoritmos de machine learning, ajudando em suas previsões e também projetos de visão computacional e processamento de linguagem natural.
Confira na imagem abaixo detalhes das etapas de ingestão, processamento e consumo de dados na Carol:
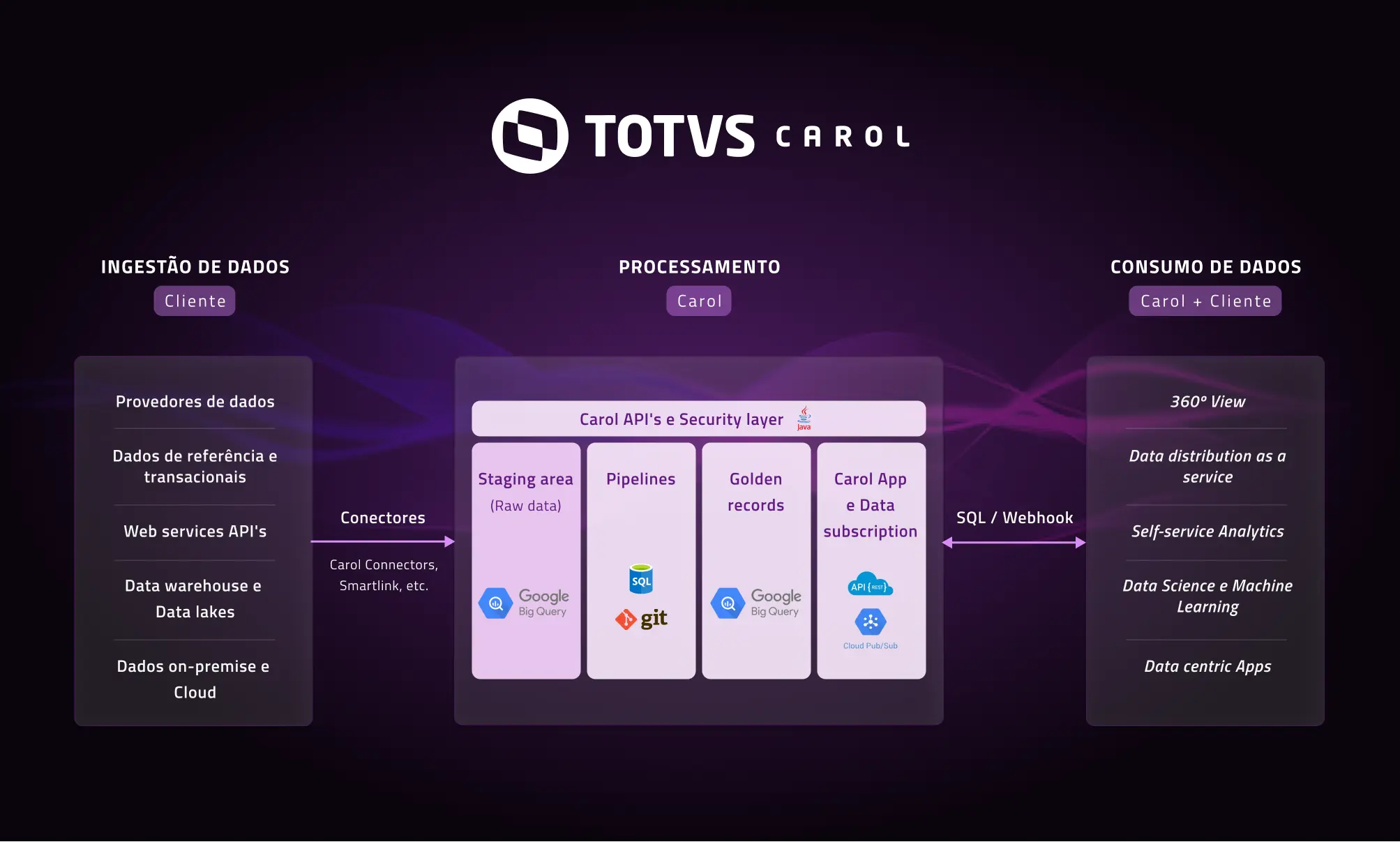
Com TOTVS Carol sua empresa atingirá uma qualidade de dados que permitirá o desenvolvimento de aplicações e modelos de machine learning por meio das habilidades abaixo:
- Forecast e Previsão: Utilizando seus
algoritmos, TOTVS Carol se conecta ao seu ERP, ou qualquer outra aplicação para extrair dados. Com isso, ela é capaz de analisar o passado para prever o futuro e se torna uma aliada poderosa para tema como vendas, churn rate, quebra de estoque e previsão de desempenho financeiro, por exemplo. - Recomendações: Por meio de uma combinação de algoritmos estatísticos de
machine learning, ela é capaz de entender os padrões de ações já adotados em processos feitos por humanos, e assim fazer recomendações de como agir em processos similares. Com isso, ela pode recomendar sugestões de preço, prospecção de clientes, e até mesmo sugerir pacotes de serviços e produtos baseados no histórico de comportamento de seus clientes. - Otimização: Mais performance e padronização. Entre as técnicas utilizadas por TOTVS Carol está a de
Deep Neural Network. Ela é capaz de analisar o comportamento de modelos de processos utilizados para agir de acordo com completa independência. Essa habilidade funciona muito bem em processos de auditoria, por exemplo. - Visão computacional: Câmeras trabalhando com dados real time. Essa habilidade é o processo de modelagem e replicação da visão humana usando software e hardware. Com TOTVS Carol, as câmeras do seu negócio deixarão de ser utilizadas apenas para segurança e passarão a possibilitar experiências por meio de
reconhecimento facialou até mesmorealidade aumentada. - Experiência de conversação: Web ou mobile, informação a um clique de distância. Utilizando o
processamento de linguagem natural(ou NLP) torna-se possível criar estruturas de conversação inteiras, considerando não só os que a TOTVS Carol consegue coletar, mas também dados consumíveis de outras origens por meio de integrações via APIs.
Organization
Organization é o ambiente principal, onde o Administrador faz o gerenciamento das Tenants e recursos relacionados.
Na URL, representa o domínio, por exemplo: totvs.carol.ai.
→ Veja mais informações em Organization Admin.
Tenant
As Tenants armazenam os Data Models, Connectors, Pipelines e todos os recursos fornecidos pela Plataforma Carol. Elas podem ser categorizadas de 3 formas:
Customer Tenant: ambiente no qual os dados brutos são recepcionados em stagings por meio de um conector e os dados para consumo (golden records) são recepcionados em data models por meio de um Carol App instalado para um eventual processo de subscrição posterior (opcional).
O Carol App fica disponível para instalação no cliente, somente após a sua instalação no ambiente unificado.
Development Tenant: ambiente no qual os Carol Apps são desenvolvidos, validados e lançados ao mercado.Carol App Tenant (Unified): ambiente unificado no qual os Carol Apps lançados são aprovados e instalados. É neste ambiente onde é centralizada a recepção e o processamento dos dados de clientes que posteriormente são retornados (golden records) para suas respectivas Tenants.
Na URL, é a informação logo após a URL base, por exemplo: totvs.carol.ai/rh.
Dúvidas sobre como provisionar?
→ Veja mais informações em Provsioning
Dúvidas sobre como administrar?
→ Veja mais informações em Tenant Admin.
Storage Type
A Plataforma Carol permite o armazenamento de dados em diferentes tipos de armazenamentos. Cada estratégia de armazenamento possui características específica que poderão beneficiar o armazenamento dos dados:
-
Carol Data Storage (CDS): armazenamento de dados em arquivos parquet, deve ser utilizado para soluções que poderão explorar beneficios dessa estratégia de armazenamento. Normalmente essa estratégia de armazenamento implica em problemas de escalabilidade nos aplicativos que utilizam desta estratégia por questões de escala horizontal dos ambiente Carol App.
-
Real-time (RT): essa estratégia de armazenamento utiliza o ElasticSearch como banco de dados, e é indicada para aplicativos que precisam de baixa latência. Essa estratégia esta sendo descontinuada da plataforma Carol por questões de estabilidade e custo relacionado à esta solução.
-
Big Query (BQ): estratégia de armazenamento de dados para larga escala de dados. Essa estratégia utiliza slots (unidade computacional) para consultar dados armazenados. O Big Query é um banco de alta latência, que deve ser utilizado em projetos com larga quantidade de dados, e a quantidade de consultar seja controlada (em função do uso de slots). Essa estratégia de armazenamento é padrão na plataforma Carol, e ela é utilizada pelo motor de processamento de dados
SQL Processing.
Uma estratégia utilizada por alguns projetos é utilizar o Data Subscription para sincronizar dados com outras estratégias de armazenamento, como banco de dados relacional (Postgres). Com isso, o aplicativo pode obter outra estratégia de armazenamento de baixa latência.
Connector
Connectors são a porta de entrada dos dados na Carol, e é através do Connector ID que os serviços disponíveis fazem a validação e integração com a plataforma.
Staging Table
Staging Table (Tabelas de Preparação) são tabelas utilizadas dentro dos Connectors com a funcionalidade principal de receber os dados que são enviados para a plataforma,
elas podem ser criadas previamente com a instalação de um Carol App com a sua estrutura pré-definida, uma outra possibilidade é realizar a criação das mesmas no momento do envio dos dados, porém sem pre-definições e modelagens já feitas, sendo necessário posteriormente realizar essas configurações que sejam viáveis de acordo com o objetivo definido para os registros.
→ Veja mais informações na seção Staging Tables.
Data Model
Data Models (Modelos de Dados) são modelos que definem a estrutura dos dados que são transformados das Staging tables através das Pipelines em SQL.
Similar à uma tabela de bancos de dados relacionais, um Data Model suporta colunas com tipos de dados específicos (String, Boolean, Date, etc.) e armazena todos os dados relacionados.
→ Veja mais informações em Data Models.
Veja as diferenças entre as camadas de dados Staging e Data Model:
-
Staging Tables
Nesta camada são armazenados os registros brutos vindos do ERP por meio de um processo de carga de dados desempenhados por conectores como o TOTVS SmartLink e o Carol Connector, conhecido como 2C. Os registros ficam armazenados em tabelas intermediárias denominadasStaging tables, que pertencem aosConnectors.
Os dados da staging area são armazenados na camada Carol Data Storage (CDS) e BigQuery. -
Data Models
Nesta camada são armazenados osGolden records, que são os registros do resultado final da transformação realizada na Plataforma Carol, por meio do processamento dePipelines. Nas Pipelines, acontece a manipulação e o tratamento dos dados brutos vindos da camadaStaging area, que são transformados em dados que ficam armazenados nas tabela doData modelpara consumo pelo cliente através das seguintes formas:- Visualização 360º na própria Plataforma Carol
- Distribuição de dados como serviço (Ex: Named Queries)
- Ferramenta Analítica (Ex: Metabase, PowerBI, Tableau, etc)
- Ciência de dados e Aprendizagem de Máquina (Ex: Bibliotecas Python/R, Google Cloud, Microsoft Azure, Amazon AWS, Jupyter, Knime, etc)
- Aplicativos centrados em dados by Carol Apps
SQL Processing
A Plataforma Carol permite o processamento de dados enviados para a Carol, e armazenados na Staging Area através de pipelines escritas em SQL (SQL Pipelines). As pipelines SQL são consultas em SQL com o objetivo de transformar os dados armazenados na Staging Area preparando os dados para que sejam armazenados na camada de dados definida em Data Model.
As pipelines em SQL permitem processar dados em escala em frações de segundos. Além disso, permite o debug, correções e deploy rapidamente das pipelines SQL.
Confira a documentação relacionada ao VS Code para verificar como acelerar a criação de pipelines através de templates.
User and User Roles
Temos usuários específicos de acordo com as características da Carol, como usuário para administração da Organização, que é um usuário mais global. Um outro tipo de usuário é o usuário da Tenant, que tem um acesso limitado a Tenant em que o mesmo está associado.
E qualquer usuário que seja administrador da Tenant consegue convidar outros usuários para o ambiente e fornecer aos mesmos uma User Role, que podem ser:
Business User: Usuário que somente pode acessar aos aplicativos (CarolApp) dentro da Tenant ao qual ele se encontra;App Admin: Usuário que somente pode acessar, configurar e executar aplicativos (CarolApp) instalados na Tenant ao qual ele se encontra;- Tenant Admin: Administrador da Tenant com permissão para visualizar os dados da Tenant, além de convidar e excluir usuários;
- Organization Admin: Administrador da Organização com permissão para criar novas Tenants, além de convidar, excluir e incluir Organization Users em Tenants (que farão a criação do TenantUser).
Data Subscription
A assinatura ou subscrição de dados fornece aos assinantes alimentação (feeds) de dados em massa aos quais eles têm direito de acesso. A assinatura de dados é basicamente uma exportação contínua em grande escala de dados do tipo golden oriundos dos data models da Carol em um formato que facilita o desenvolvimento de aplicativos personalizados. O formato de dados se presta à integração com dados e análises de outras fontes, tornando-o escalável e ingerível para seus aplicativos personalizados.
Carol Apps
É o nome dado aos aplicativos inteligentes desenvolvidos e implantadaos no topo da plataforma Carol.
O ciclo de vida do desenvolvimento de uma pipeline passa pela criação, desenvolvimento e implantação de um Carol App representado conforme o fluxo abaixo.

Na etapa de desenvolvimento podemos utilizar de templates disponíveis no repositório do github da plataforma Carol com os seguintes tipos de Carol Apps:
OnlineCarol App: Este tipo de Carol App permite-nos prestar serviços no topo da Carol. Basicamente, desenvolveremos endpoints e a implantação acontecerá no topo da Carol. O modelo hoje fornecido está usando Flask e python como exemplo, mas você pode implantar qualquer tecnologia (em nosso repositório, você pode ver um exemplo usando o NodeJS) que pode ser incorporado em uma imagem do Docker.BatchCarol App: Esse tipo de aplicativo Carol nos permite criar aplicativos e agendar a recorrência para executá-lo. O modelo hoje fornecido está usando python, mas você pode escrever seu código em qualquer tecnologia incorporada em uma imagem do Docker.WebCarol App: esse tipo de aplicativo Carol permite implantar qualquer conteúdo HTML. Por padrão, nosso exemplo usa o framework PO UI como base, mas você pode implantar qualquer conteúdo HTML na Carol.SQLCarol App: esse tipo de aplicativo Carol permite que os dados brutos enviados para a Carol e armazenados naStaging Areasejam processados por meio de pipelines escritas em SQL (SQL Pipelines). Estas pipelines de processamento tem como objetivo final realizar a transformação dos dados brutos em dados golden (refinados), para que então sejam armazenados na camada de dados definida emData Model.
→ Veja mais informações em Carol Apps.
Imagem Docker
Imagem do Docker é um arquivo, composto por várias camadas, usado para executar o código em um contêiner do Docker. Essa abordagem nos permite criar ambientes muito personalizados e empacotá-lo em um arquivo para executar rapidamente um aplicativo específico.
A imagem do Docker é usada na Carol para a otimização e isolamento de processos. O desenvolvedor pode criar, validar e implantar a imagem do Docker, depois disso, executá-la sobre a Carol para fornecer o valor desejado que seu aplicativo precisa.
Se você precisar de mais informações sobre o Docker, consulte a documentação oficial: https://www.docker.io
Meta-informações nos dados (metadata)
A plataforma Carol possui diversas meta-informações nos dados para permitir um debug e tracking com maior eficácia dos dados.
As meta-informações estão distribuídas nos tipos de dados:
Staging Area
- mdmTenantId: Identificador interno da tenant proprietária do dado (tenant "dona" do registro).
- mdmCounterForEntity: Este atributo representa a data/hora em microsseconds de quando o dado foi recebido pela plataforma Carol. Registros enviados na mesma request vão receber o mesmo valor para este atributo.
- mdmId: Este atributo armazena o ID unico do registro, o ID é determinado pelos valores dos atributos definidos no crosswalk (primary key) da staging table.
- mdmCreated: Este atributo recebe a data/hora de atualização do registro, como a plataforma Carol trata os dados de forma imutável, este atributo recebe o mesmo valor que
mdmCounterForEntity. - mdmLastUpdated: Este atributo recebe a data/hora de atualização do registro, como a plataforma Carol trata os dados de forma imutável, este atributo recebe o mesmo valor que
mdmCounterForEntity. - mdmTenantId: Este atributo armazena o ID unico de tenant da plataforma Carol.
- mdmConnectorId: Este atributo armazena o ID do conector que este registro pertence.
- mdmEntityType: Este atributo é a concatenação de
connectorIdcom o nome da staging table. - mdmDeleted: Este atributo é a representação lógica se o registro esta eliminado (valor
true) ou não (valor null oufalse). - mdmAuditId: Este atributi armazena a chave de auditoria unica durante o recebimento de dados pela plataforma Carol. Este atributo permite resgatar detalhes / logs durante o recebimento dos dados.
- mdmBatchId: Este atributo armazena a informação de
Batchenviado pelo Smartlink. No primeiro momento apenas a linha de produto Protheus é compatível com este recurso (Release Outubro/2023). - mdmBatchIdSequence: Este atributo armazena a informação da sequência do
Batchenviado pelo Smartlink. No primeiro momento apenas a linha de produto Protheus é compatível com este recurso (Release Outubro/2023). - mdmCounterForEntity__DATETIME__: Este atributo representa o atributo
mdmCounterForEntityna representaçãodatetime. Recomenda-se utilizar o atributomdmCounterForEntitypara operações, sendo que o atributomdmCounterForEntity__DATETIME__era unicamente utilizado na versão do schema do Bigquery v2 para criação das partições. Atualmente a partição das staging tables é definida pelo atributo_ingestionDatetime. - _ingestionDatetime: Este atributo representa a data/hora que o registro foi efetivamente gravado no BigQuery. A diferença entre
mdmCounterForEntitye_ingestionDatetimerepresenta o tempo de viagem do dado entre o mecanismo de ingestão (intake) e o armazenamento do dado na camada de persistência (BigQuery). Este atributo é a partição padrão das staging tables, recomenda-se que as pipelines utilizem esse atributo para evitar a leitura de todas as partições pelas pipelines de processamento de dados SQL. - __customValues: Este atributo existe apenas em tenants unificadas, e caso a tenant esteja com o parâmetro
mdmEnableCustomFieldsOnStagingativado as colunas da tenant cliente não existentes na tenant unificada serão salvos neste atributo como chave/valor (objeto). - _extraAttributes: Atributo de uso interno da plataforma.
Golden Record
- mdmTenantId: Identificador interno da tenant proprietária do dado (tenant "dona" do registro).
- mdmCounterForEntity: Este é o registro que o golden record foi processado pelo motor de processamento SQL Processing.
- mdmStagingCounter: Este é o counter (data/hora em microseconds) que o registro foi recebido na plataforma Carol, na camada de recepção de dados (intake).
- mdmId: Este atributo armazena o ID unico do registro de golden record. Este valor é gerado através do ID (mdmID) do registro da staging area considerando também o nome do data model.
- mdmCreated: Este atributo recebe a data/hora de atualização do registro, como a plataforma Carol trata os dados de forma imutável, este atributo recebe o mesmo valor que
mdmCounterForEntity(referente ao golden record). - mdmLastUpdated: Este atributo recebe a data/hora de atualização do registro, como a plataforma Carol trata os dados de forma imutável, este atributo recebe o mesmo valor que
mdmCounterForEntity(referente ao golden record). - mdmEntityType: Este atributo possui o nome do data model com o sufixo
Golden. - mdmSourceEntityNames: Este atributo possui o connectorID e o nome da staging table referente à staging table referenciada como
stgna pipeline de processamento de dados. - mdmStagingRecord: Este atributo possui um array de ID dos registros da staging table. Este registro de staging record é referenciado a tabela com alias
stgna pipeline. - mdmDeleted: Este atributo é a representação lógica se o registro esta eliminado (valor
true) ou não (valor null oufalse). - mdmCounterForEntity__DATETIME__: Este atributo é a representação
datetimedo atributomdmCounterForEntity. Recomenda-se utilizar os atributosmdmCounterForEntitypara operações da pipelines, ou_ingestionDatetimeque é partição padrão dos data models. - _ingestionDatetime: Este atributo representa a data/hora que o registro foi efetivamente gravado no BigQuery, como golden record. Este atributo é a partição padrão dos data models.
- mdmStagingAuditId: Este atributo possui o valor de
auditIddo registro da staging table. Para que este atributi possua valor, a pipeline deve utilizar a tag--metadata-v2--. - mdmTaskId: Este atributo possui o ID da task que gerou o golden record. A task possui internamente a versão da pipeline que foi executada.
- mdmBatchId: Este atributo possui a informação de
batchproveniente do registro da staging table. Para que este atributo possua informação, a pipeline deve utilizar a tag--metadata-v2--. - mdmBatchIdSequence: Este atributo possui a informação de
batchproveniente do registro da staging table. Para que este atributo possua informação, a pipeline deve utilizar a tag--metadata-v2--. - mdmCrosswalk: Conteúdo utilizado no cálculo da chave interna do registro (mdmId). O preenchimento/manutenção deste atributo é de responsabilidade da pipeline SQL Processing.
- mdmPreviousIds: Atributo legado, sem uso funcional atual. Está em processo de depreciação.
- mdmApplicationIdMasterRecordId: Atributo legado, sem uso funcional atual. Está em processo de depreciação.
Observações:
- No golden record, os atributos
mdmStagingCounter,mdmStagingCountere_ingestionDatetimepermitem informar a data/hora que o registro foi recebido pela plataforma Carol, processado, e armazenado na camada de golden record (respectivamente).
As tabelas temporárias do SQL Processing também possui as metas-informações acima, seguindo a mesma regra descrito acima.