Pipelines e Manifesto
Dúvidas sobre o que é uma pipeline e um manifesto?
→ Veja mais informações na seção de conceitos.
Antes de começar
Para que os dados sejam processados por pipelines SQL, os seguintes requisitos devem ser atendidos:
- Ambiente deve estar com o Bigquery ativado. A ativação ocorre através do perfil Organization Admin, na Organization.
- Pipelines de processamento através do
Mapping and Cleanse Rulesdeve estar pausado ou devem ser removidos. O processamento de dados antigo deve estar desativado para evitar conflito dos dados gerados.
Os demais capítulos desta documentação irão apresentar os passos necessários para o desenvolvimento e deploy de pipelines SQL na Carol.
Manifesto de Pipelines
O plugin Carol no VSCode auxilia o processo de criação e edição do manifesto de pipelines.
Caso o seu aplicativo processe dados a partir do ambiente unificado, recomendamos o uso do manifesto de pipelines V2.
<span style={{color: "#B22222"}}>Para quem utiliza o orquestrador, esta ainda não é uma versão suportada, portanto siga utilizando a V1.
Para o deploy de pipelines SQL na plataforma Carol, é necessário a definição do manifesto de pipelines V2 conforme o exemplo abaixo.
Fique atento ao tipo do seu ambiente (development, unified ou customer), alguns atributos modificam seu comportamento conforme o tipo do ambiente.
{
"version": "V2",
"defaults": {
"cronExpressions": ["0 0 3 ? * MON-FRI *"],
"prepareScripts": ["prepare.sql"]
},
"pipelines": [
{
"pipelineName": "clockin_pipeline",
"pipelineDescription": "Pipeline to process clockin records - test",
"outputDataModelName": "clockinrecords",
"overlapDeltaMinutes": 3600,
"cronExpressions": ["0 0 3 ? * MON-FRI *"],
"timeZone": "America/Sao_Paulo",
"processScript": "clockinrecords.sql",
"sourceEntities": {
"dataModels": [
{
"dataModelName": "image"
}
],
"stagings": [
{
"connectorName": "clockinmobile",
"stagingName": "clockinrecords"
},
{
"connectorName": "clockinmobile",
"stagingName": "device"
},
{
"connectorName": "clockinmobile",
"stagingName": "employee"
}
]
},
"sendTo": {
"bigquery": {
"customer": true,
"unified": true
},
"subscriptions": {
"customer": false,
"unified": false
},
"realtime": false
},
"clear": {
"bigquery": {
"unified": false,
"customer": false
},
"subscriptions": {
"unified": false,
"customer": false
},
"realtime": false
},
"fanOut": true,
"useBatchObservability": true,
"useBatchSQLEfficiency": true,
"checkExistsDataToProcess": true,
"additionalParameters": {
"connectorGroup": ["totvsprotheus"]
"runOnlyForTenantIds": ["15ae924596f1422bbf525b075f11444f"],
"ignoreForTenantIds": ["1aa5a1e6805a4cd5bea22fcbb12a0761"]
}
}
]
}
Linha 2(version) é definida a versão do manifesto que está sendo utilizada. Para que a plataforma Carol interprete o manifesto como V2, é necessário que esse elemento esteja logo no início do manifesto, conforme exemplo.Linha 4(cronExpressions) é definido a regra de agendamento padrão para todas as pipelines. As pipelines podem sobrescrever essa definição com um agendamento especifico. A definição CRON segue o padrão Quartz, que pode ser conferida neste link: https://www.freeformatter.com/cron-expression-generator-quartz.html.Linha 5(prepareScripts) é definido o script que será executado no ambiente Unif (ambiente responsável em executar as pipelines em produção) quando o Carol App for instalado. Este script é utilizado normalmente para a criação de funções padrão para as pipelines.Linha 7(pipelines): especificação de todas as pipelines, seguindo o documento Json a seguir.Linha 8(pipeline): especifica a pipeline e as configurações da pipeline. Deverá haver um objeto Json para cada pipeline.Linha 9(pipelineName): especifica o nome da pipeline.Linha 10(pipelineDescription): especifica a descrição da pipeline, utilizado na plataforma Carol.Linha 11(outputDataModelName): data model que irá armazenar os dados resultantes da pipeline.Linha 12(overlapDeltaMinutes): quantidade de minutos que será executado em sobreposição em relação à última execução desta pipeline. Caso seja a primeira execução, a pipeline será executada sem restrição de dados pela janela de recebimento dos dados (equivalente a um processamento inicial).Linha 13(cronExpressions): permite sobrescrever o calendário de execução global deste manifesto.Linha 14(timeZone): define o timezone do calendário de execução. Por padrão o timezone definido éBR.Linha 15(processScript): indica a pipeline SQL que deve ser executada. Detalhes nas definições das pipelines aqui no guideline de pipelines).Linha 16(sourceEntities): indica staging tables e data models utilizados na pipeline. Essas staging tables e data models serão armazenados no ambiente Unif para processamento dos dados.Linha 37(sendTo): indica quais camadas de dados a pipeline deve enviar seus registros.Linha 38(sendTo.bigquery): indica se a pipeline em sua execução deve enviar seus registros para o BigQuery. Pode-se indicar o envio para os tenantscustomere tenantunifiedde um Carol App. Um tenant do tipodevelopmentusará o valor informado emunified.Linha 42(sendTo.subscriptions): indica que ao término da execução da pipeline, os resultados devem ser enviados via data subscription (caso o data model tenha essa configuração). Registros incluídos e registros removidos são enviados via Data Subscription. Pode-se indicar o envio para os tenantscustomere tenantunifiedde um Carol App. Um tenant do tipodevelopmentusará o valor informado emunified.Linha 46(realtime): indica que ao término da execução da pipeline, os resultados devem ser enviados para o realtime (Elasticsearch).Linha 48(clear): indica que no antes da execução da pipeline, a tabela datamodel indicada emoutputDataModelNamedeve ser limpa completamente em cada execução.Linha 49(clear.bigquery): detalha a ação de limpeza, pode-se indicar a limpeza para os tenantscustomere tenantunifiedde um Carol App. Um tenant do tipodevelopmentusará o valor informado emunified.Linha 53(clear.subscriptions): Adequação do manifesto para futura implementação de plataforma. Por hora não executa nenhuma ação.Linha 57(realtime): indica que no antes da execução da pipeline, a tabela datamodel indicada emoutputDataModelNamedeve ser limpa na camada realtime (Elasticsearch).Linha 59(fanOut): indica que ao término da execução da pipeline no unificado, os resultados devem ser enviados aos tenantscustomer.Linha 60(useBatchObservability): indica que a observabilidade está habilitada, sem vínculo com as eficiências useBatchSQLEfficiency e checkExistsDataToProcess.Linha 61(useBatchSQLEfficiency): indica que a pipeline está configurada para utilizar a eficiência batch. Quando o envio de dados através do intake inclui os parâmetrosbatchIdebatchIdSequence, a plataforma Carol irá esperar a conclusão do envio dobatchpara iniciar o processamento de dados de todas as pipelines vinculadas as staging tables recebidas no batchID para a tenant. Mais detalhes em Eficiência do SQL Processing e Envio de dados.Linha 62(checkExistsDataToProcess): indica que a pipeline está configurada para utilizar a eficiência genérica, considerando apenas novos dados inseridos nas tabelas indicadas emsourceEntities. Apenas quando o envio de dados através do intake ocorrer a pipeline será executada, caso não hajam novos registros, não haverão execuções. Mais detalhes em Eficiência do SQL Processing e Envio de dados.Linha 63(additionalParameters): indica parâmetros adicionais a serem considerados na execução da pipeline. Como exemplo os parametros opicionais que são considerados pelo orquestrador de pipelines: "runOnlyForTenantIds": que permite que uma pipeline seja executada por um grupo de tenants e "ignoreForTenantIds": que permite uma pipeline não seja executada por um grupo de tenants.
Documentação Manifesto de Pipelines V1
{
"defaults": {
"cronExpressions": ["0 */5 0 ? * * *"],
"prepareScripts": ["prepare.sql"]
},
"pipelines": [
{
"pipelineName": "clockin_pipeline",
"pipelineDescription": "Pipeline to process clockin records - test",
"outputDataModelName": "clockinrecords",
"overlapDeltaMinutes": 3600,
"saveToCds": false,
"saveToUnified": true,
"saveToRealtime": false,
"sendToSubscriptions": false,
"cronExpressions": ["0 5,15,25,35,45,55 * * * ?"],
"timeZone": "America/Sao_Paulo",
"processScript": "clockinrecords.sql",
"sourceEntities": {
"dataModels": [
{
"dataModelName": "image"
}
],
"stagings": [
{
"connectorName": "clockinmobile",
"stagingName": "clockinrecords"
},
{
"connectorName": "clockinmobile",
"stagingName": "device"
},
{
"connectorName": "clockinmobile",
"stagingName": "employee"
}
]
},
"useBatchNotification": true,
"additionalParameters": {
"connectorGroup": ["totvsprotheus"]
}
}
]
}
Principais características:
Linha 4(cronExpressions) é definido a regra de agendamento padrão para todas as pipelines. As pipelines podem sobrescrever essa definição com um agendamento especifico. A definição CRON segue o padrão Quartz, que pode ser conferida neste link: https://www.freeformatter.com/cron-expression-generator-quartz.html.Linha 8(prepareScripts) é definido o script que será executado no ambiente Unif (ambiente responsável em executar as pipelines em produção) quando o Carol App for instalado. Este script é utilizado normalmente para a criação de funções padrão para as pipelines.Linha 13(pipelines): especificação de todas as pipelines, seguindo o documento Json a seguir.Linha 15(pipeline): especifica a pipeline e as configurações da pipeline. Deverá haver um objeto Json para cada pipeline.Linha 16(pipelineName): especifica o nome da pipeline.Linha 17(pipelineDescription): especifica a descrição da pipeline, utilizado na plataforma Carol.Linha 18(outputDataModelName): data model que irá armazenar os dados resultantes da pipeline.Linha 19(overlapDeltaMinutes): quantidade de minutos que será executado em sobreposição em relação à última execução desta pipeline. Caso seja a primeira execução, a pipeline será executada sem restrição de dados pela janela de recebimento dos dados (equivalente a um processamento inicial).Linha 20(saveToCds): indica que o resultado da pipeline deve ser salvo no storage type CDS. Em geral, não recomendamos utilizar essa solução pois os dados estão sendo persistidos no Bigquery.Linha 21(saveToUnified): indica que o resultado da pipeline deve ser salvo no ambiente Unif (ambiente centralizador dos dados, responsável por processar os dados em escala). Um tenant do tipodevelopmentusará o valor informado em nesse campo.Linha 22(saveToRealtime): indica que ao término da execução da pipeline, os resultados devem ser enviados para o realtime (Elasticsearch).Linha 23(sendToSubscriptions): indica que ao término da execução da pipeline, os resultados devem ser enviados via data subscription (caso o data model tenha essa configuração). O envio do data subscription ocorre pelas Tenants clientes. Registros incluídos e registros removidos são enviados via Data Subscription.Linha 24(cronExpressions): permite sobrescrever o calendário de execução global deste manifesto.Linha 28(timeZone): define o timezone do calendário de execução. Por padrão o timezone definido éBR.Linha 29(processScript): indica a pipeline SQL que deve ser executada. Detalhes nas definições das pipelines aqui no guideline de pipelines).Linha 30(sourceEntities): indica staging tables e data models utilizados na pipeline. Essas staging tables e data models serão armazenados no ambiente Unif para processamento dos dados.Linha 53(useBatchNotification): indica que a pipeline está preparada para executar utilizando a eficiência do SQL Processing. Quando o envio de dados através do intake envia os parâmetrosbatchIdebatchIdSequencea plataforma Carol irá esperar a conclusão do envio dobatchpara iniciar o processamento de dados de todas as pipelines vinculadas as staging tables recebidas no batchID para a tenant. Mais detalhes em Eficiência do SQL Processing e Envio de dados.Linha 54(additionalParameters): indica parâmetros adicionais a serem considerados na execução da pipeline.
O parâmetro saveToRealtime (V1) ou realtime (V2) uma vez definido com valor TRUE no manifesto, caso a pipeline SQL não tenha trabalhado na deduplicação dos dados, os dados serão deduplicados on-the-fly no momento de pegar os dados da tabela temporária (temp table) para enviá-los com os tipos de registros golden e rejected.
Ou seja, mesmo que o parâmetro deduplicateResults no endpoint processQuery seja FALSE, se o valor saveToRealtime for TRUE no manifesto ele irá deduplicar os registros para todas as camadas de armazenamento, mantendo a consistência entre camadas. O mesmo vale se for um processamento para a tabela de mdmuser e o parâmetro mdmUseDirectUserIntegration estiver FALSE para a tenant. A razão deste comportamento se deve ao fato do ElasticSearch manter a unicidade pelo mdmID, e a pipeline ter retornado mais de um registro com o mesmo mdmID.
Guidelines para pipelines SQL
Esta seção descreve guidelines para construção de pipelines SQL para processamento de dados na Carol e contém requisitos obrigatórios e recomendações para manter o código simples e de fácil manutenção, bem como tratar casos comuns nos pipelines em SQL. Se você deseja obter mais informações relacionadas às etapas para processar dados usando o mecanismo SQL, consulte esta documentação.
É recomendado que o arquivo da pipeline SQL salvo no repositório do Git possua a extensão .csql. Esta extensão permite uma melhor integração com o Plugin do VSCode.
O formato de data suportado na Carol, é o ISO-8601, qualquer outro formato incorrerá em erros na plataforma, tanto na ingestão dos dados quanto no processamento da pipeline.
Requisitos obrigatórios
- Bigquery é um banco colunar, sempre evite SELECT *, mesmo queries iniciando da staging tables. Isso permitirá consultas mais rápidas e com menos uso de slots.
- Sempre retorne todas as colunas do Data Model, respeitando a tipagem dos atributos. Use regras abaixo para converter dados de String para Int64/Float64 e Int64/Float64 para String:
- Utilizaremos o endpoint abaixo para execucução das pipelines
//string to float64
cast (trim(balance) AS float64) as balance
//int64 to string
cast (cashflow AS string) as cashflow
- Query segmentada isolando as staging tables e filtrando apenas os atributos necessários, reduzindo assim o contexto na query.
Linhas 1 e 10iniciam a definição de fontes de dados. O objetivo desses blocos é selecionar apenas os dados necessários para o data model, convertendo os valores e aplicando o nome do atributo no data model.Linha 19efetua o merge desses dados. Caso seja necessário o merge dos dados, uma função analítica deve ser utilizada.Linha 27inicia o processo de definição do golden record, aplicando no atributo mdmDeleted a regra de rejeição e relationship constraint. Este atributo terá o valor true caso o registro deve ser rejeitado.
- O bloco que seleciona os dados das staging tables deve nomear a staging table principal com o nome stg, permitindo a plataforma efetuar a definição correta de meta dados da staging table principal (principalmente nos cenários que ocorre join com outras staging tables).
- Adicionar, para cada staging table, a informação
--metadata{connectorName, stagingTableName}--conforme visualizado nas linhas 7 e 16. A plataforma efetua a ingestão de meta dados automaticamente através dessa keyword.- Caso sejam definidas as informações de connectorName e stagingTableName o crosswalk será definido em tempo de execução da pipeline, permitindo que o dado possua a rastreabilidade interna para o registro da staging area.
- Quando a pipeline implementa a regra de geração do mdmId, a tag
--metadataNoId--deve ser utilizada, desta forma a Carol irá assumir o mdmId gerado pela pipeline. O atributo contendo o mdmId deve ser nomeado como__mdmId. Caso o mdmId seja gerado manualmente pela pipeline, a pipeline deve utilizar como parte da geração do mdmID o connectorID, garantindo assim a unicidade dos IDs gerado pelas diferentes tenants na plataforma Carol. O mdmId gerado pela Carol compreende do crosswalk da staging table, concatenado com o connectorID e o nome da staging table. A string gerada passa pelo processo de md5 e conversão para hexadecimal. Em SQL:TO_HEX(md5(CONCAT(connectorId, stagingTableName, crosswalkAsJson))). - Caso o conector ou a staging table sejam inválidos, a tabela irá preservar o crosswalk definido originalmente na tabela nomeada como stg.
Linha 28aplica a regra de rejeição, retornando true para o atributo mdmDeleted caso o atributo uuid tenha valor null ou em branco.
A plataforma Carol disponibiliza a tag --metadata-v2-- que permite criar Golden Records com os atributos mdmStagingAuditId, mdmTaskId, mdmBatchId e mdmBatchSequenceId. Esses atributos são origiários dos staging records e a pipeline SQL é responsável em determinar qual tabela deve promover esses atributos para o Golden Record. A promoção desses atributos ocorre através da definição do alias stg na pipeline SQL.
Quando a pipeline implementa a regra de geração do mdmId, a tag --metadataNoId-v2-- deve ser utilizada, desta forma a Carol irá assumir o mdmId gerado pela pipeline. O atributo contendo o mdmId deve ser nomeado como __mdmId. Caso o mdmId seja gerado manualmente pela pipeline, a pipeline deve utilizar como parte da geração do mdmID o connectorID, garantindo assim a unicidade dos IDs gerado pelas diferentes tenants na plataforma Carol. O mdmId gerado pela Carol compreende do crosswalk da staging table, concatenado com o connectorID e o nome da staging table. A string gerada passa pelo processo de md5 e conversão para hexadecimal. Em SQL: TO_HEX(md5(CONCAT(connectorId, stagingTableName, crosswalkAsJson))).
As pipelines permitem um filtro otimizado de tenants, para reprocessamentos através da interface gráfica da Carol, e com isso fazer o filtro de dados para as tenants (mdmTenantID) na tabela origem dos dados, otimizando a performance da pipeline.
Para aplicar esse filtro, deve ser utilizado a seguinte notação:
--tenantIds-- and mdmTenantId IN {{tenantIds}}
Quando a interface gráfica de reprocessamento iniciar o processamento dos dados, irá conferir que a pipeline está compatível com o filtro e irá efetuar a substituição de {{tenantIds}} pela lista de tenants aplicado no filtro da plataforma Carol.
O funcionamento caso a tag --tenantIds-- não esteja em filtro ocorre efetuando o encapsulamento da query como inner query, o que pode gerar erro caso a pipeline originalmente utilize o uso de funções temporárias.
with company_fndorganization as (
SELECT
stg.uuid as uuid,
stg.description as name,
stg.description as alias,
(select org.federalid from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY mdmcounterforentity DESC) ranking, * from stg_protheus_carol_organization) where ranking = 1 ) as org where org.uuid = stg.uuid) federalid,
--metadata{protheus_carol, stg}--
from stg_protheus_carol_company as stg
),
organization_fndorganization as (
SELECT
stg.uuid as uuid,
stg.name as name,
stg.alias as alias,
stg.federalid as federalid,
--metadata{protheus_carol, stg}--
from stg_protheus_carol_organization as stg
),
organization as (
select *
from company_fndorganization stg
union all
select *
from organization_fndorganization stg
)
select * except(_counter),
((uuid is null) or (uuid = '')) mdmDeleted
from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY _counter DESC) ranking, * from organization) where ranking = 1 )
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
Como controlar o merge de múltiplas staging tables.
No bloco de código anterior, pode ser aplicado uma regra analítica nas linhas que obtém o dado da staging table (linhas 8 e 17). Uma função analítica com o objetivo de efetuar o merge pode ser visualizada nas linhas 6 e 29, trabalhando em cenários diferentes com o mesmo objetivo de efetuar o merge em tempo de query dos dados.
Como aplicar ETL no pipeline SQL.
O processamento de dados através de pipeline SQL permite o processamento de dados partindo da mesma staging table, fazendo com que não seja necessário a gravação de dados temporários da pipeline.
As funções ETL da Carol são substituídas na seguinte forma:
-
Duplicate: não é necessário processamento adicional, sendo que todo pipeline inicia da staging table raiz (primária). Os pipeline SQL não precisam ter armazenamento de dados de tabelas intermediárias do pipeline. A alteração da crosswalk (chave primária) da staging table normalmente ocorre durante o duplicate. A seção "Como alterar o crosswalk efetuando merge de dados na staging area" explica como ocorre esse processo. -
Join: permite aplicar de duas formas:- Subquery no select, da mesma forma que a query acima efetua na linha 6.
- Através de JOIN (
left,right,inner). Permitindo efetuar o join de uma ou várias tabelas.
-
Split: aplicado condições (where) na cláusula da staging table, assim filtrando dados não desejáveis.
Como alterar o crosswalk (primary key) efetuando o merge (virtual) de dados na staging area
O pipeline SQL pode alterar (virtualmente) o crosswalk de staging tables, fazendo com que o merge ocorra nos momentos iniciais do pipeline, reduzindo assim a quantidade de registro a ser processado.
No exemplo anteriormente compartilhado, o merge poderia ocorrer da seguinte forma, conforme exibido na linha 8:
with company_fndorganization as (
SELECT
stg.uuid as uuid,
stg.description as name,
stg.description as alias,
(select org.federalid from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY mdmcounterforentity DESC) ranking, * from stg_protheus_carol_organization) where ranking = 1 ) as org where org.uuid = stg.uuid) federalid,
`a_techfin`.buildSourceEntityNames('5f629f91ac1a4a5ebcfd29f47fafe153', 'company') as mdmSourceEntityNames,
stg.mdmCounterForEntity as _counter,
--metadata{protheus_carol, stg}--
from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY _counter DESC) ranking, * from stg_protheus_carol_company) where ranking = 1 ) stg
),
organization_fndorganization as (
SELECT
stg.uuid as uuid,
stg.name as name,
stg.alias as alias,
stg.federalid as federalid,
`a_techfin`.buildSourceEntityNames('5f629f91ac1a4a5ebcfd29f47fafe153', 'organization') as mdmSourceEntityNames,
stg.mdmCounterForEntity as _counter,
--metadata{protheus_carol, stg}--
from stg_protheus_carol_organization as stg
),
organization as (
select *
from company_fndorganization stg
union all
select *
from organization_fndorganization stg
)
select * except(_counter),
uuid as __mdmId,
_counter as __mdmCounterForEntity,
((uuid is null) or (uuid = '')) mdmDeleted
from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY _counter DESC) ranking, * from organization) where ranking = 1 )
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
Como controlar o processamento parcial de dados
A Carol possui mecanismos internos para otimizar o processamento parcial através do atributo _ingestionDatetime. O atributo _ingestionDatetime é caracterizado pelo timestamp (em nanosegundos) de quando o dado chega na plataforma Carol. Abaixo é compartilhado um exemplo de um pipeline com mecanismo de processamento parcial:
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
A flag --timestamp-- funciona para configurar o pipeline com cargas incrementais. A condição de filtro incremental é configurado após a flag --timestamp-- conforme demonstrado acima.
No exemplo, o filtro é dado pela coluna _ingestionDatetime. A sintaxe mustache representada por {{start_from}} faz a interpolação entre a data e hora atual menos o overlapDeltaMinutes configurado na definição do pipeline.
Na prática, a Carol remove a flag --timestamp-- e deixa apenas o trecho da consulta que foi configurado logo em seguida. Desta maneira, é possível configurar diferentes estratégias incrementais dependendo da necessidade do usuário. Basta escrever os filtros da consulta após a flag --timestamp--.
IMPORTANTE: a flag --timestamp-- só é removida após a segunda execução do pipeline. Sempre que há uma configuração nova de pipeline ou uma execução que reprocessa todos os dados, esta flag permanece na consulta e uma carga completa é feita. O controle de execuções é feito pelo backend da Carol. Ou seja, ainda que há dados nas tabelas de destino, se não há um registro de execução pela Carol (uma nova configuração, por exemplo), então uma carga completa será completa pela Carol.
Abaixo é compartilhado o código completo de uma pipeline com processamento parcial:
with company_fndorganization as (
SELECT
stg.uuid as uuid,
stg.description as name,
stg.description as alias,
(select org.federalid from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY mdmcounterforentity DESC) ranking, * from stg_protheus_carol_organization) where ranking = 1 ) as org where org.uuid = stg.uuid) federalid,
`a_techfin`.buildSourceEntityNames('5f629f91ac1a4a5ebcfd29f47fafe153', 'company') as mdmSourceEntityNames,
stg.mdmCounterForEntity as _counter,
--metadata{protheus_carol, stg}--
from stg_protheus_carol_company as stg
),
organization_fndorganization as (
SELECT
stg.uuid as uuid,
stg.name as name,
stg.alias as alias,
stg.federalid as federalid,
`a_techfin`.buildSourceEntityNames('5f629f91ac1a4a5ebcfd29f47fafe153', 'organization') as mdmSourceEntityNames,
stg.mdmCounterForEntity as _counter,
--metadata{protheus_carol, stg}--
from stg_protheus_carol_organization as stg
),
organization as (
select *
from company_fndorganization stg
union all
select *
from organization_fndorganization stg
)
select * except(_counter),
uuid as __mdmId,
_counter as __mdmCounterForEntity,
((uuid is null) or (uuid = '')) mdmDeleted
from (select * except(ranking) from (select row_number() over (partition by uuid ORDER BY _counter DESC) ranking, * from organization) where ranking = 1 )
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
Obs.: O ideal sempre é aplicar os filtros nas tabelas afim de evitar que dados sejam carregados para outras sub-queries. Desta forma, ideal sempre aplicar filtro temporal como sendo o primeiro filtro da pipeline, evitando aplicar regras de conversão de dados em todo o dataset, filtrando apenas no final.
Os seguintes recursos não são suportados neste momento:
| Recurso | Motivo |
|---|---|
| Golden Record View | O recurso de view no storage Realtime está em processo de descontinuação desde final de 2021. Este recurso não será compatibilizado com SQL Processing sendo necessário a migração para outra tecnologia ou adequação com o Bigquery. |
| User Management | O mapeamento para o Data Model User para gestão dos usuários não está sendo suportado neste momento. Em versão breve a plataforma terá o suporte a este recurso. A recomendação neste momento é manter este fluxo com o pipeline de processamento atual (através das regras de mapeamento e limpeza). |
Definição de regras de rejeição
As pipelines em SQL podem efetuar a rejeição de registros e indicar o motivo pela rejeição, orientando os usuários no Explore pelo motivo o qual o registro foi rejeitado.
A pipeline a seguir é um exemplo de uma pipeline que explora uma regra de rejeição:
CREATE TEMP FUNCTION rejection_rules(arr ANY TYPE) AS (
(SELECT [
STRUCT("REJECTION_RULE" as mdmStage,
"((record.uuid is null) or (record.uuid = ''))" as mdmErrorMsg,
((record.uuid is null) or (record.uuid = ''))
as mdmActive)
] FROM UNNEST(arr) AS record)
);
WITH organization_organization AS (
SELECT
stg.uuid AS uuid,
stg.name AS name,
stg.alias AS alias,
stg.federalId AS federalid
--metadata--
FROM (
SELECT * EXCEPT(ranking)
FROM (
SELECT ROW_NUMBER() OVER (partition BY mdmId ORDER BY mdmCounterForEntity DESC) ranking, *
FROM stg_protheus_carol_organization
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
)
WHERE ranking = 1
) AS stg
),
company_organization AS (
SELECT
stg.uuid AS uuid,
stg.description AS name,
stg.description AS alias,
(
select org.federalid from (
select * except(ranking)
from (
select row_number() over (partition by uuid ORDER BY mdmcounterforentity DESC) ranking, *
from stg_protheus_carol_organization)
where ranking = 1 ) as org
where
org.mdmTenantId = stg.mdmTenantId
and org.uuid = stg.uuid
) AS federalid
--metadata--
FROM (
SELECT * EXCEPT(ranking)
FROM (
SELECT ROW_NUMBER() OVER (partition BY mdmId ORDER BY mdmCounterForEntity DESC) ranking, *
FROM stg_protheus_carol_company
--timestamp-- WHERE _ingestionDatetime > SAFE.DATETIME(TIMESTAMP_MICROS(SAFE_CAST({{start_from}} AS INT64)))
)
WHERE ranking = 1
) AS stg
),
combinedSources AS (
SELECT * FROM organization_organization
UNION ALL
SELECT * FROM company_organization
),
processedData AS (
select * except(__mdmId), uuid as __mdmId from (
SELECT ROW_NUMBER() OVER (partition BY uuid ORDER BY __mdmCounterForEntity DESC) ranking, *
FROM combinedSources
)
where ranking = 1
)
SELECT *,
(EXISTS(SELECT 1 FROM UNNEST(mdmErrors) WHERE mdmActive = true)) AS mdmDeleted
FROM (
select dm.*,
(rejection_rules(ARRAY((SELECT AS STRUCT
dm.uuid
)))) AS mdmErrors
from processedData as dm
)
Essa pipeline explora os seguintes itens:
- Múltiplas staging tables;
- Consolidação de dados no join para representar um lookup;
- Merge de dados através do atributo de negócio
uuid; - Aplica regra de rejeição para rejeitar registros com
uuidnull ou em branco. combinedSourcestem função similar ao antigo mapeamento visual de regras ETL, nele você pode efetuar a união (merge), por meio da escrita SQL, de uma ou mais tabelas. É um parâmetro opcional na montagem de pipelines portanto, caso não tenha a intenção de efetuar uniões de tabelas então você pode remover este trecho.processedDatatem a função de consolidar todos os registros, mantendo apenas uma versão de cada registro, antes de torná-los golden. Caso tenha removido o trecho combinedSources da sua lógica, você precisa alterar a referência noFROMdentro do bloco processedData apontando para a sua staging em questão.
Pontos de atenção para Pipelines SQL em ambiente unificado
De forma geral precisamos considerar o campo mdmTenantId em todas as pipelines SQL que processem dados em ambiente unificado. Abaixo seguem os pontos que devemos ter atenção redobrada, em pipelines SQL.
1 - O ambiente unificado possui um volume de dados maior, o que requer queries mais performáticas e utilização de condicional no atributo de partition da tabela.
Para obter mais detalhes referente as partições do BigQuery veja essa documentação.
2 - Quando realizar particionamento (PARTITION BY) para fazer deduplicação de dados, recomendamos que o campo mdmTenantId seja o primeiro campo na listagem.

3 - Quando existir a clausula JOIN (INNER JOIN, LEFT JOIN, RIGHT JOIN ou CROSS JOIN ) e subquery, deve ser utilizado o campo mdmTenantId nesta clausula para cada tabela envolvida.

4 - O campo mdmTenantId também deve estar presente nas clausulas GROUP BY.

5 - Os ambientes que tiveram o BigQuery provisioando em 2023 possuem a v3 da estrutura de dados, que disponibiliza o atributo _ingestionDatetime como atributo de partição.
É importante que as pipelines passem por um processo rigoroso de testes para garantir que não possui falhas no join e no uso do atributo mdmTenantId.
Processando dados através de pipelines SQL (endpoint)
Este seção tem como objetivo compartilhar as etapas para processar dados usando o mecanismo SQL.
Se você deseja obter mais informações relacionadas à iniciativa e benefícios, assista a esta apresentação.
Essa versão inicial do processamento de dados SQL nos permite executar o processamento de dados sob demanda chamando um endpoint e enviando o SQL que processará os dados.
Você pode construir o comando SQL para processar os dados usando o Carol Insights Studio e depois enviar a consulta conforme demonstrado nesta documentação.
Processando dados usando o mecanismo SQL
Pré requisitos:
Esta documentação pressupõe que as seguintes etapas foram executadas:
- Login
Construindo a instrução SQL para processar dados
Essa estratégia de processamento de dados não requer o uso de ETL. Como você pode resolver os ETLs como consulta, pode usá-lo para reduzir a complexidade.
Alguns itens a serem considerados na hora de construir suas próprias declarações:
- A consulta deve usar consultas temporárias internas.
- Todas as tabelas temporárias devem começar a partir de uma única tabela de preparação.
- Use tabelas temporárias internas para unir várias tabelas de preparação.
- Sempre use os campos do modelo de dados como saída (renomeie os campos na instrução SQL).
- Use funções tanto quanto isso ajuda.
- As regras de rejeição e restrição de relacionamento devem ser consideradas como parte da consulta.
Práticas recomendadas ao criar uma instrução SQL
Seguem algumas dicas de como construir instruções SQL para processar dados:
- Use funções: você pode reutilizar o código e reduzir a complexidade.
- Segmente sua consulta com base no número da tabela de preparação. Facilita a avaliação da consulta e a localização de eventuais bugs.
- O resultado SQL deve seguir o esquema do Modelo de Dados (nomes dos campos).
Executando uma instrução SQL para processar dados
- Existe um endpoint que nos permite executar enviando o comando SQL definido e informando o modelo de dados que receberá os dados.
- Como Env Admin, após autenticar no Swagger, acesse o endpoint abaixo:

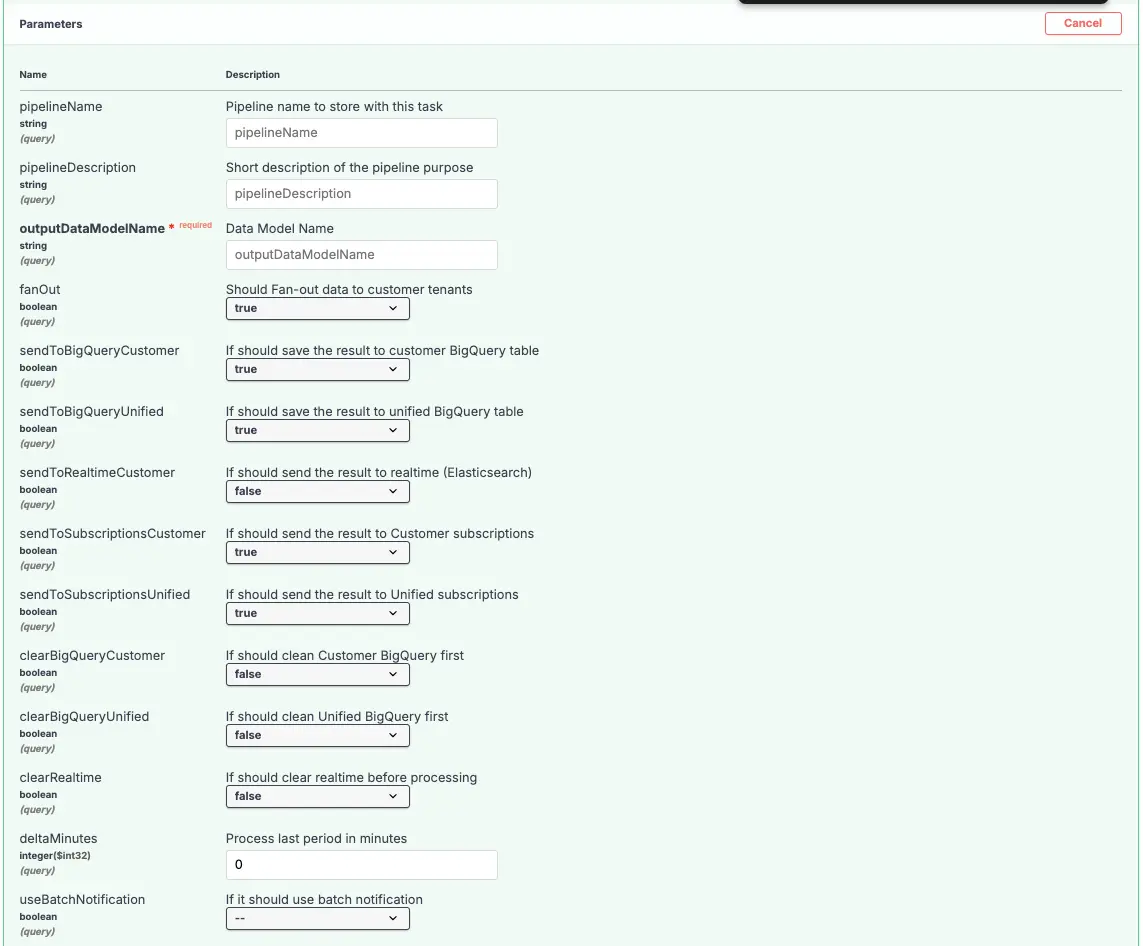
Siga a descrição dos parâmetros disponíveis:
| Nome do Parâmetro | Descrição |
|---|---|
| pipelineName | Este é o nome da pipeline de dados. Esse nome deve ser definido para executar a pipeline (SQL) informado no payload da request. Esse nome estará disponível na task de execução da pipeline. |
| pipelineDescription | Esta é a descrição da pipeline de dados. |
| outputDatamodelName | Este é o nome do modelo de dados que irá armazenar os dados reultantes da pipeline. Você pode obter o nome do modelo de dados correto na interface do usuário do modelo de dados. |
| fanOut | Este parâmetro quando setado como TRUE, indica que ao término da execução da pipeline no unificado, os resultados (golden records) devem ser enviados aos tenants clientes de destino. O valor padrão é TRUE. |
| sendToBigQueryCustomer | Este parâmetro quando setado como TRUE, executará o processo de envio dos golden records para a camada de armazenamento BigQuery nas tenants clientes de destino. O valor padrão é TRUE. O parâmetro fanOut também deve estar TRUE para que o envio dos dados para a tenant cliente ocorra. |
| sendToBigQueryUnified | Este parâmetro quando setado como TRUE, executará o processo de envio dos golden records para a camada de armazenamento BigQuery na tenant unificada. O valor padrão é TRUE. |
| sendToRealtimeCustomer | Este parâmetro quando setado como TRUE, executará o processo de envio dos golden records para a camada de armazenamento RealTime nas tenants clientes de destino. O valor padrão é TRUE. O parâmetro fanOut também deve estar TRUE para que o envio dos dados para a tenant cliente ocorra. |
| sendToSubscriptionsCustomer | Este parâmetro quando setado como TRUE, executará o processo de envio das subscrições para as tenants clientes de destino. O valor padrão é TRUE. O parâmetro fanOut também deve estar TRUE para que o envio dos dados para a tenant cliente ocorra. |
| sendToSubscriptionsUnified | Este parâmetro quando setado como TRUE, executará o processo de envio das subscrições para a tenant unificada. O valor padrão é TRUE. |
| clearBigQueryCustomer | Este parâmetro quando setado como TRUE, executará o processo de limpeza dos Golden Records nas tenants clientes de destino. O valor padrão é TRUE. |
| clearBigQueryUnified | Este parâmetro quando setado como TRUE, executará o processo de limpeza dos Golden Records na tenant unificada. O valor padrão é TRUE. |
| clearRealtime | Este parâmetro quando setado como TRUE, executará o processo de limpeza dos golden records na camada de armazenamento RealTime nas tenants clientes de destino. O valor padrão é TRUE. |
| deltaMinutes | Este parâmetro indica a quantidade de minutos que será executado em sobreposição em relação à última execução desta pipeline. Caso seja a primeira execução, a pipeline será executada sem restrição de dados pela janela de recebimento dos dados (equivalente a um processamento inicial). |
| useBatchNotification | Este parâmetro setado como TRUE, indica que a observabilidade está ativa utilizando-se da eficiência batch. Isto quer dizer, quando o envio de dados através do intake inclui os parâmetros batchId e batchIdSequence, a plataforma Carol irá esperar a conclusão do envio do batch para iniciar o processamento de dados de todas as pipelines vinculadas as staging tables recebidas no batchID para a tenant. Mais detalhes em Eficiência do SQL Processing e Envio de dados. |
| checkExistsDataToProcess | Este parâmetro setado como TRUE, indica que a pipeline está configurada para utilizar a eficiência genérica, considerando apenas novos dados inseridos nas tabelas indicadas em sourceEntities. Apenas quando o envio de dados através do intake ocorrer a pipeline será executada, caso não hajam novos registros, não haverão execuções. Mais detalhes em Eficiência do SQL Processing e Envio de dados. |
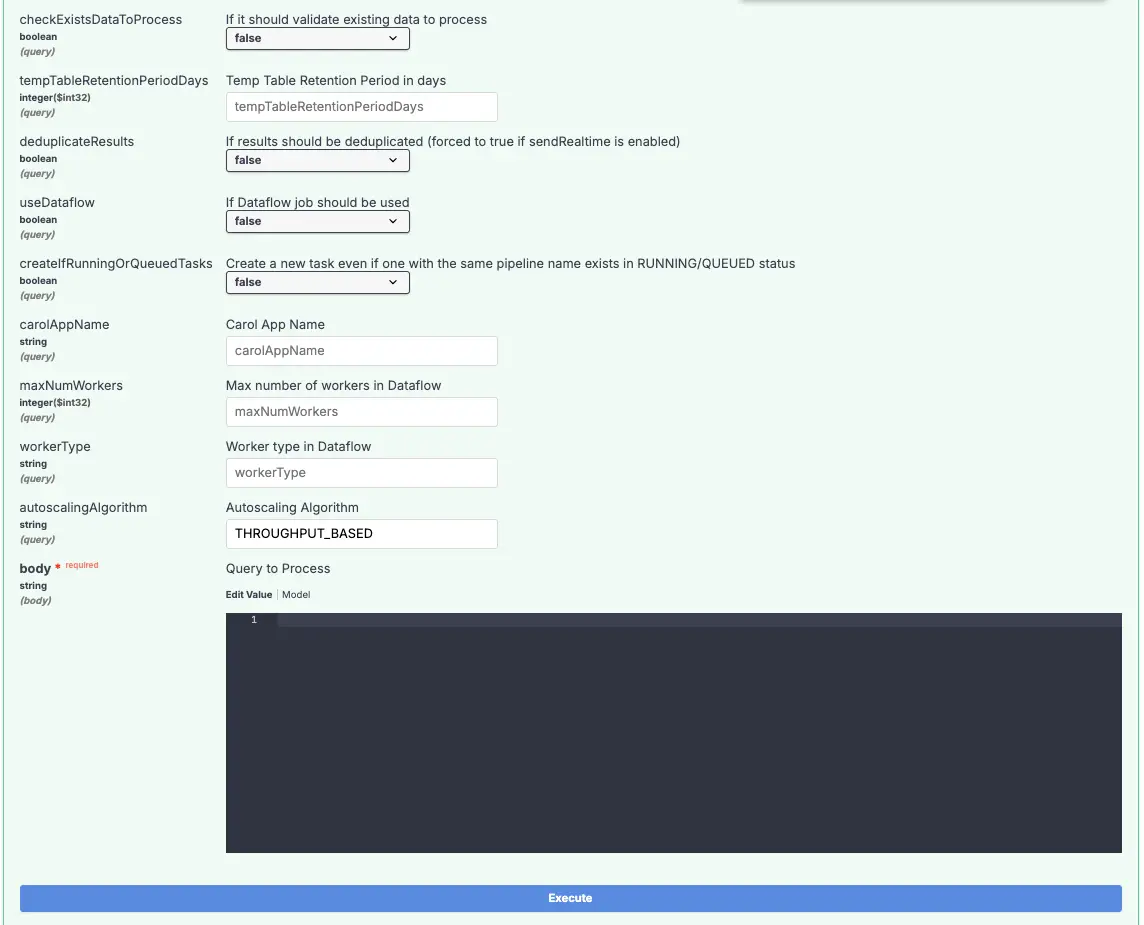
| tempTableRetentionPeriodDays | Este parâmetro opcional indica quantos dias os dados de tabelas de processamento temporárias ficarão retidas no BigQuery. O valor mínimo permitido é de 3 dias e o valor máximo permitido é de 14 dias. Quando este valor não vier setado, o padrão assumido é de 3 dias. |
| deduplicateResults | Este parâmetro setado como TRUE, indica que os resultados do processamento de uma pipeline (golden records) serão deduplicados no momento do envio. O valor padrão é TRUE. |
| useDataflow | Este parâmetro indica se Carol deve executar este processamento de dados no Dataflow. O Dataflow é utilizado quando temos uma carga de dados maior (acima de 10 mb), esse parâmetro permite forçar o uso do Dataflow com o parâmetro TRUE ou deixar que a plataforma Carol opte por rodar com o Dataflow ou sem esse recurso de forma automática. Recomenda-se enviar o parâmetro FALSE deixando a plataforma decidir a melhor forma de processar os dados. |
| createIfRunningOrQueuedTasks | Este parâmetro setado como TRUE, indica que não será realizada uma validação se já existe uma task do mesmo group em execução. O valor padrão é FALSE. |
| carolAppName | Este é o nome do Carol App. Você pode obter o nome do Carol App correto na interface de pipelines. |
| maxNumWorkers | Este parâmetro permite definir o número máximo de workers no Dataflow Batch que irá processar os dados gerado pela pipeline. Este parâmetro existe para fazer ajustes de performance em pipelines que exigem o processamento de mais dados. |
| workerType | Este parâmetro permite definir o tipo de instância do Dataflow Batch. Recomenda-se deixar em branco para que a plataforma definida o tipo de instância correta de acordo com o volume dos dados. |
| autoscalingAlgorithm | Parâmetro para redefinir a estratégia de auto scaling do Dataflow Batch. Recomenda-se deixar esse parâmetro em branco. |
| body | Deve ser enviado a pipeline, conforme descrito na documentação de pipelines. |
Os seguintes recursos serão completamente descontinuados em Dezembro/2024:
| Recurso | Motivo |
|---|---|
| saveCDS, clearCDS | O recurso para Golden Records na camada de armazenamento Carol Data Storage (CDS) está em processo de descontinuação e será completamente removido da plataforma em Dezembro/2024. |
Os times consumindo o recurso foram notificados. A orientação é o uso do BigQuery, incluindo instruções SQL ou Storage Read API em substituição, permitindo manter performance e custos escaláveis.
Como construir um processamento SQL (exemplo de tabela da empresa)
- Antes de realizar qualquer ação, verifique se a Tenant está provisionado com o Big Query.
- Para executar um processamento SQL válido, estamos usando aqui como exemplo o modelo de dados
fndHierarchyOrganizatione a tabela de stagingcompany: - No github, podemos acessar os pipelines de processamento SQL válidos construídos até agora.
- No exemplo abaixo, estamos referenciando campos de metadados.
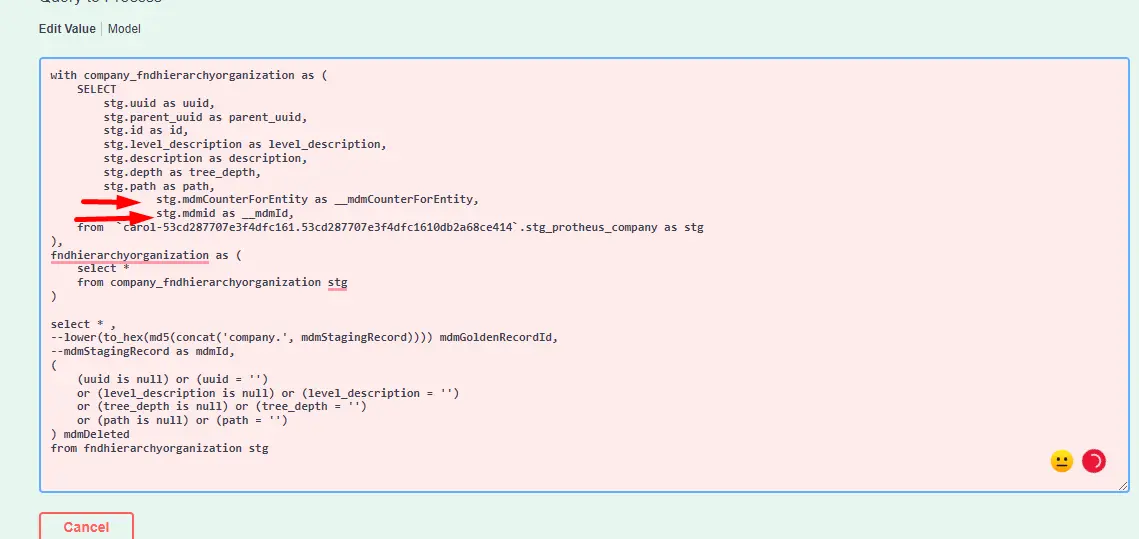
Campos de Metadados
- Hoje em dia, se não quisermos referenciar metacampos, podemos usar o pipeline conforme abaixo:
- Exigimos o uso de um token onde podemos injetar campos de metadados. Esses campos são necessários para que a plataforma possa rastrear as informações do escalonamento, e os registros não fiquem duplicados na plataforma. Por exemplo, quando o mesmo registro é processado duas vezes, deve ser tratado como uma atualização e não como um novo registro.
- O token de metadados é responsável por conectá-lo.
- O que a pessoa que está escrevendo o SQL precisa fornecer:
- Marque a tabela de preparação com o alias
stg
- Marque a tabela de preparação com o alias
from `...table...`as stg
- Insira o token
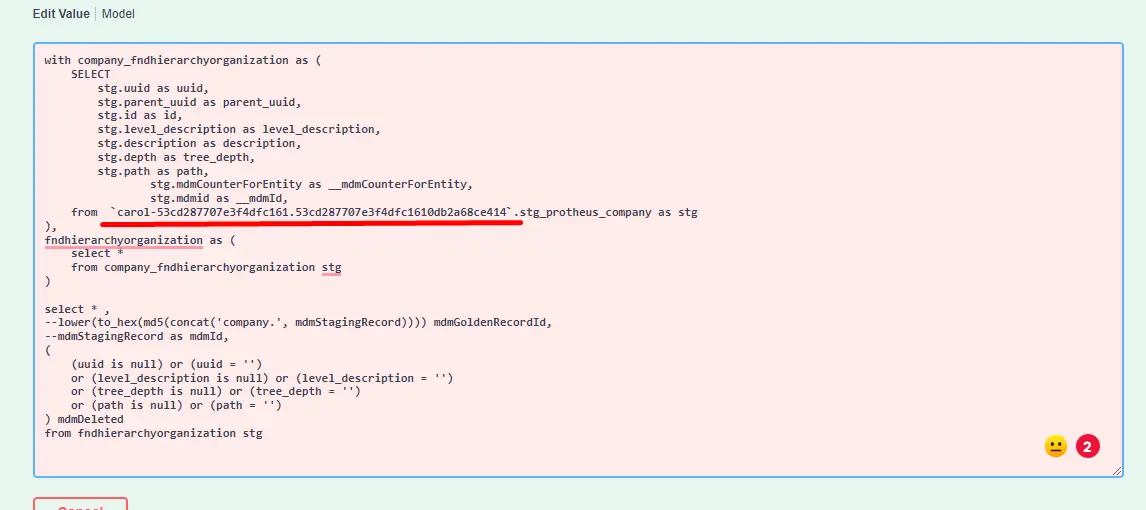
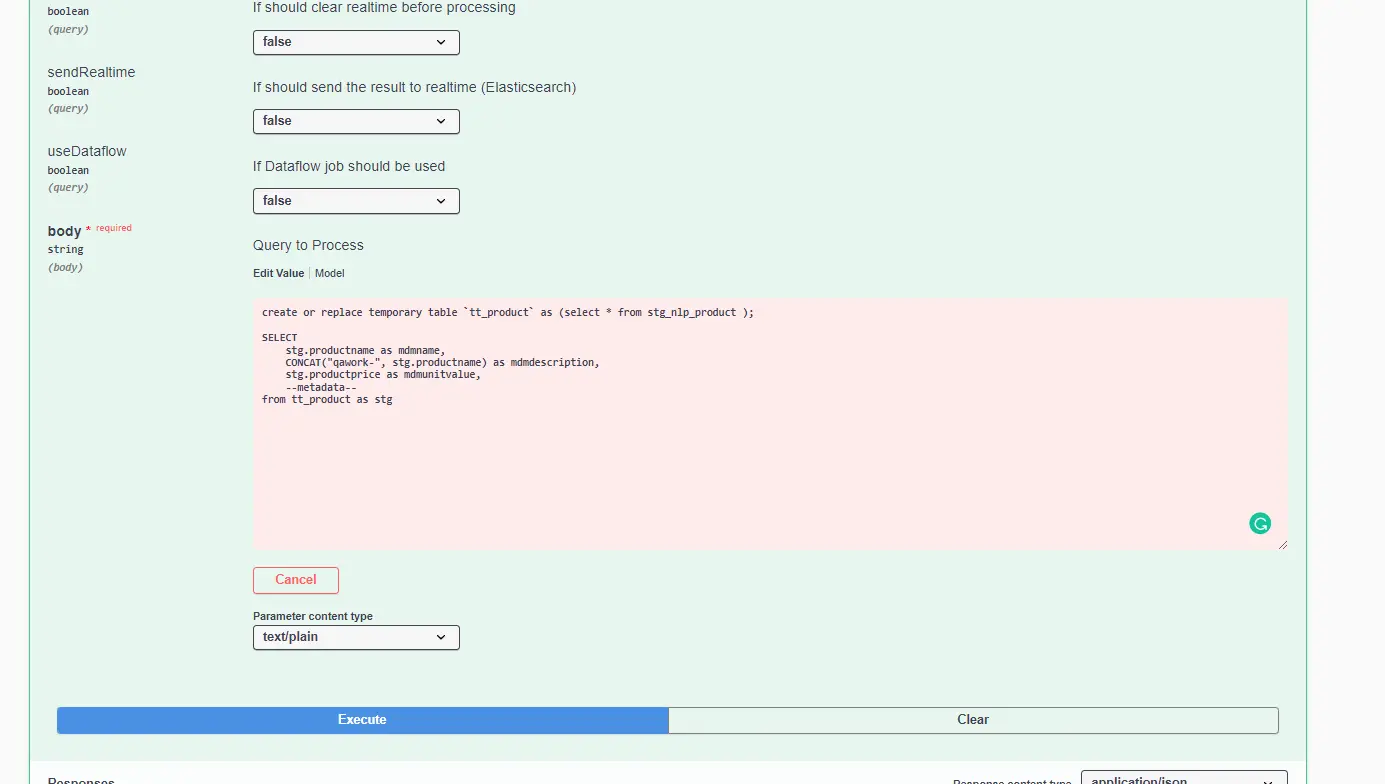
--metadata--na parte de projeçãoSELECTda consulta. Veja exemplo abaixo:
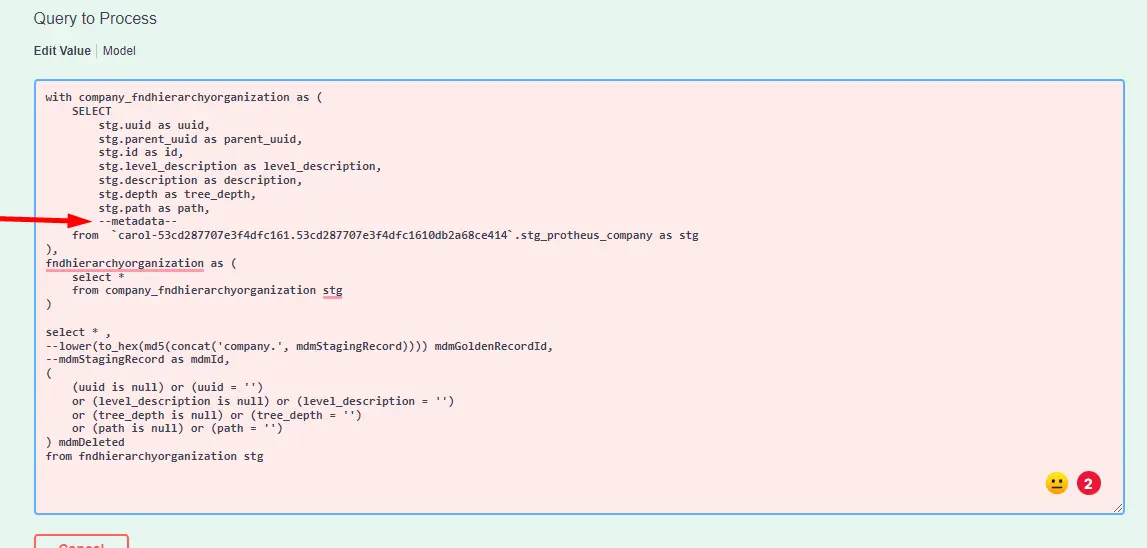
- Atualmente, estes são os campos que Carol está injetando na consulta quando
--metadata--é usado:
stg.mdmId as __mdmId
stg.mdmCounterForEntity as __mdmCounterForEntity
stg.mdmTenantId as __mdmTenantId // (após 3.60.0)
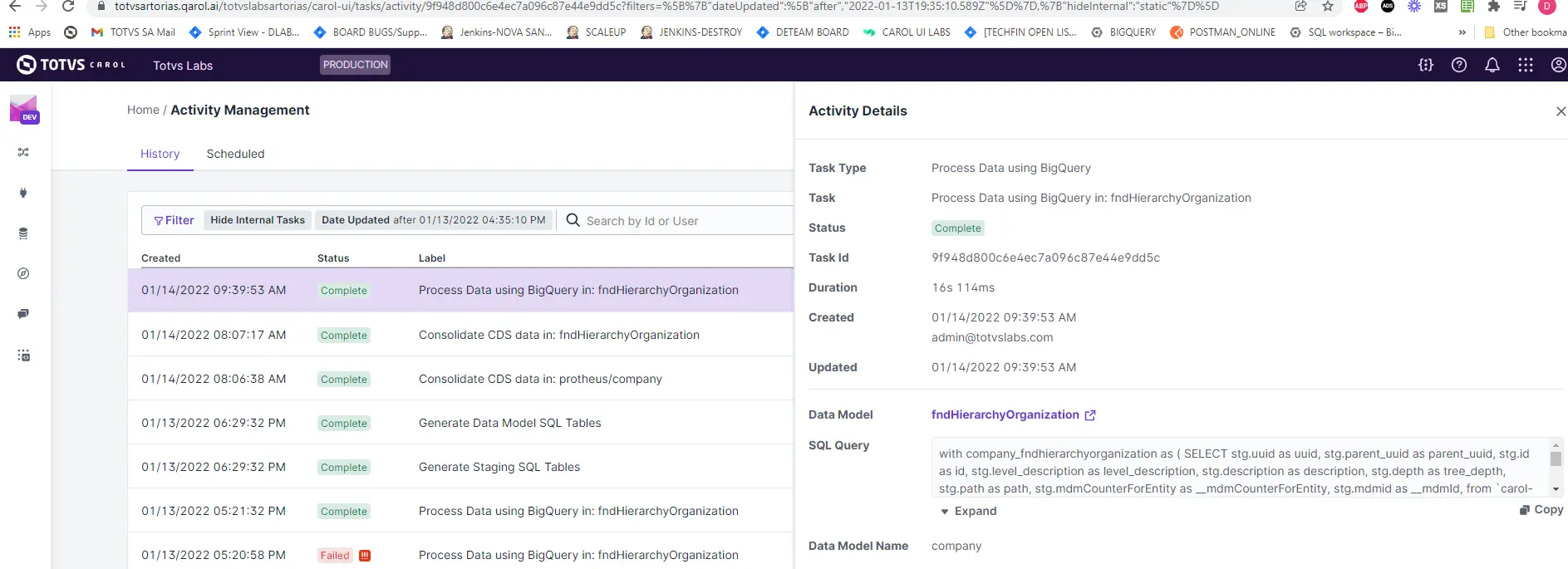
Nível de Tarefa
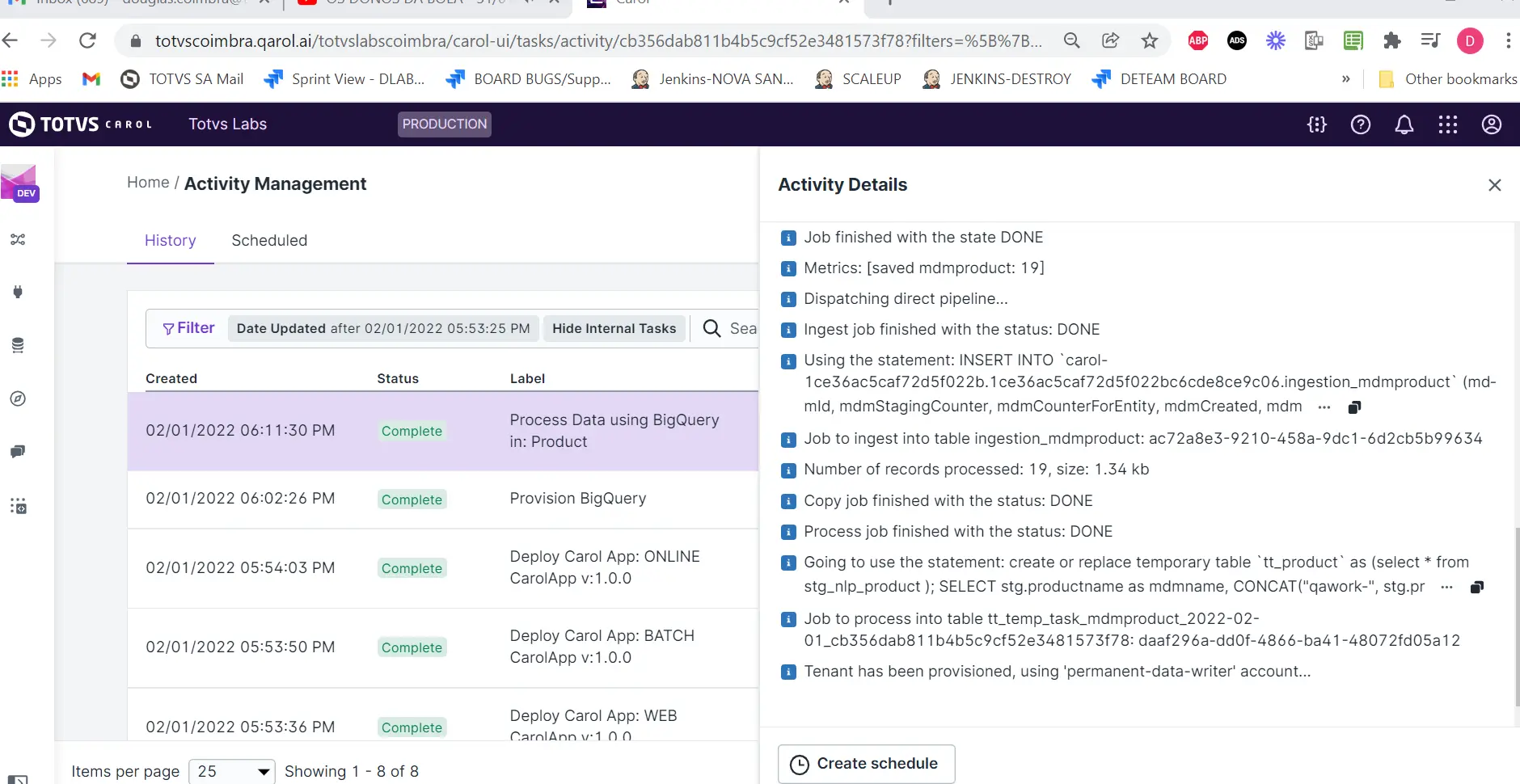
Na plataforma, a tarefa será exibida como Process Data using BigQuery
Observação do conjunto de dados
Observe que devemos especificar o conjunto de dados com base na ID da Tenant (mdmID). (Observe que será a mesma descrição do conjunto de dados do Big Query criado)
Executar processo SQL como tarefa interna
Se precisarmos executar o Processamento SQL para não notificar o usuário sobre a Tarefa, podemos usar o mesmo procedimento adicionando --internal-- conforme exemplificado logo abaixo:
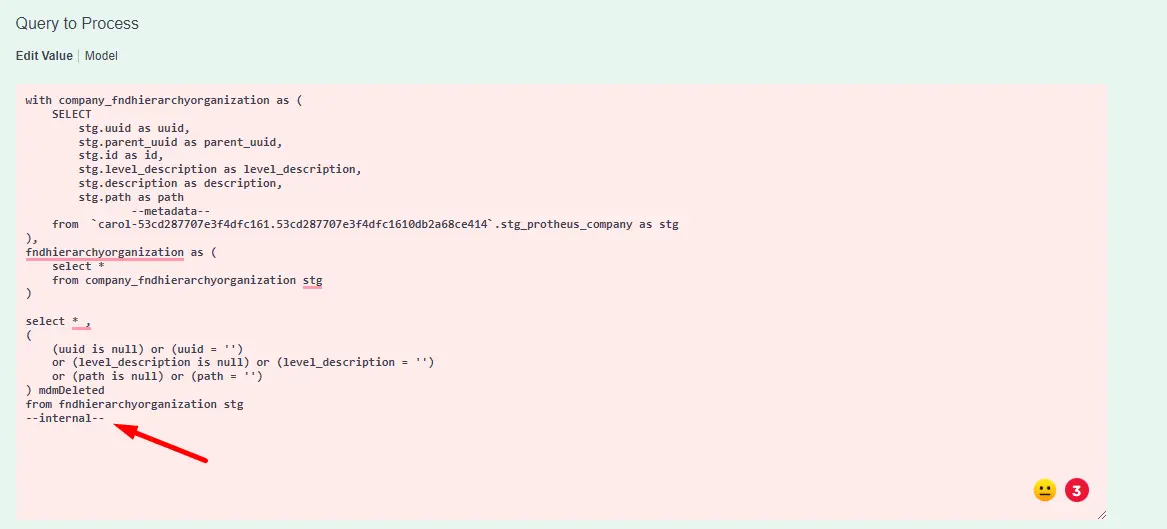
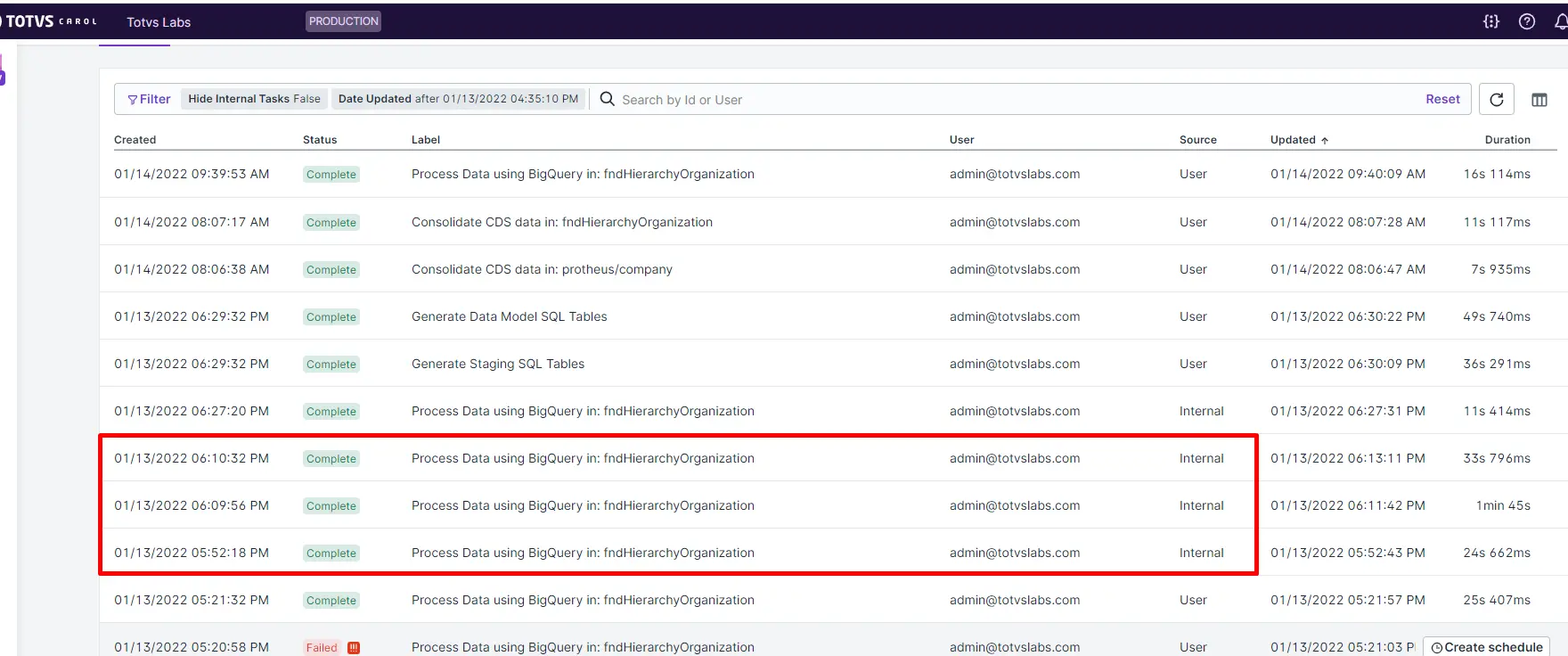
Tabelas temporárias
O processamento de dados SQL permite-nos criar tabelas temporárias, que têm um tempo de expiração definido (cerca de 24h de duração).
-
Uma vez que executamos uma tarefa normal do processo SQL, uma tarefa temporária é criada por padrão como:
-
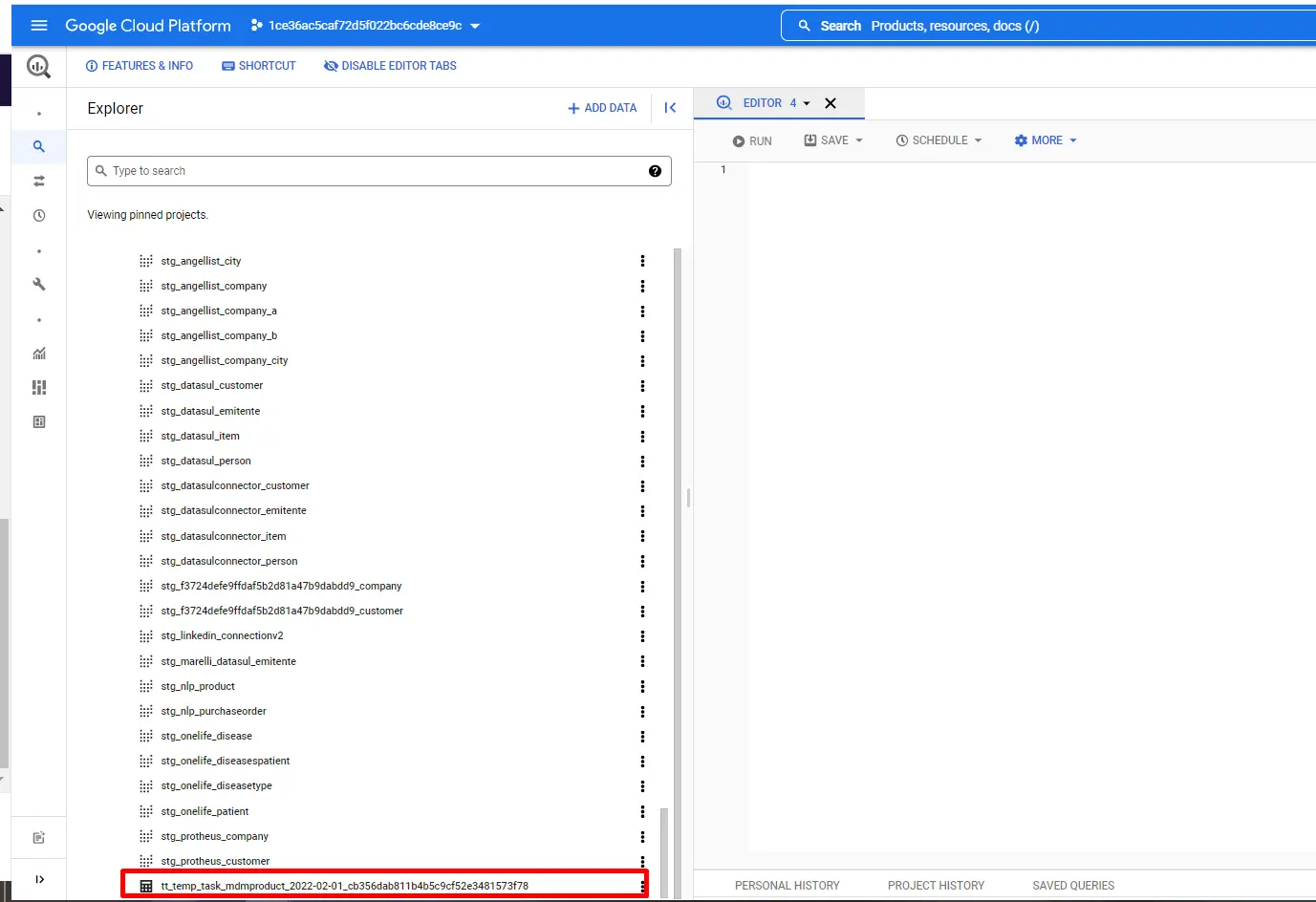
Nome da tabela temporária do Big Query criado no projeto de Tenant após chamar
/v2/bigQuery/processQuery?entityTemplateName=<dataModelName>seguindo o nome do padrão:tt_temp_task_<dataModelName>_<date_ISO>_<taskID> , em que <dataModelName>é o valor passado para entityTemplateName,<date_ISO>é a data em que o terminal foi acionado e<taskID>é a ID da tarefa no painel Activity Details para a tarefa criada após o acionamento do terminal. -
Se a tarefa Processamento SQL não tiver registros, a tabela temporária não será criada.
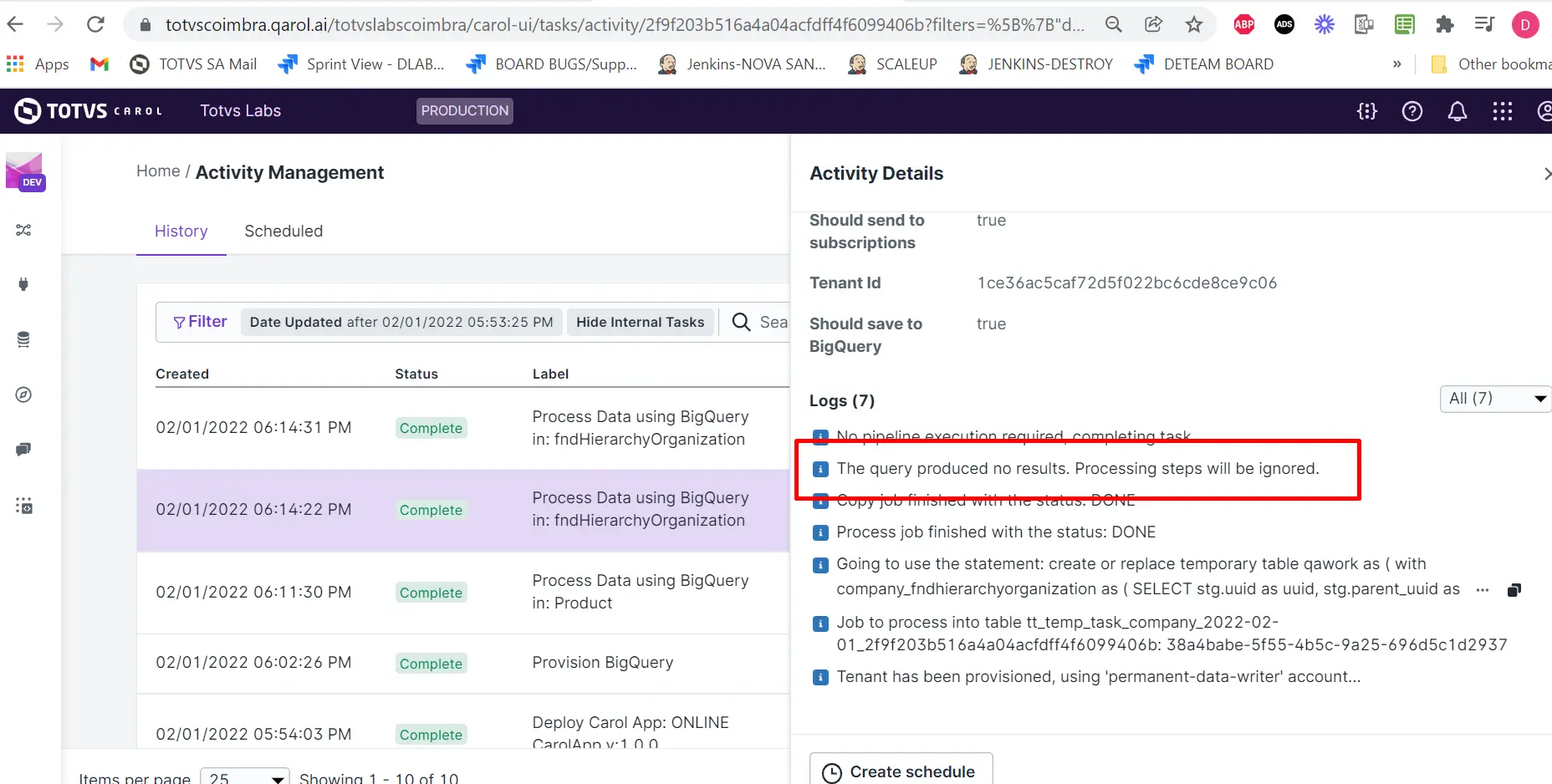
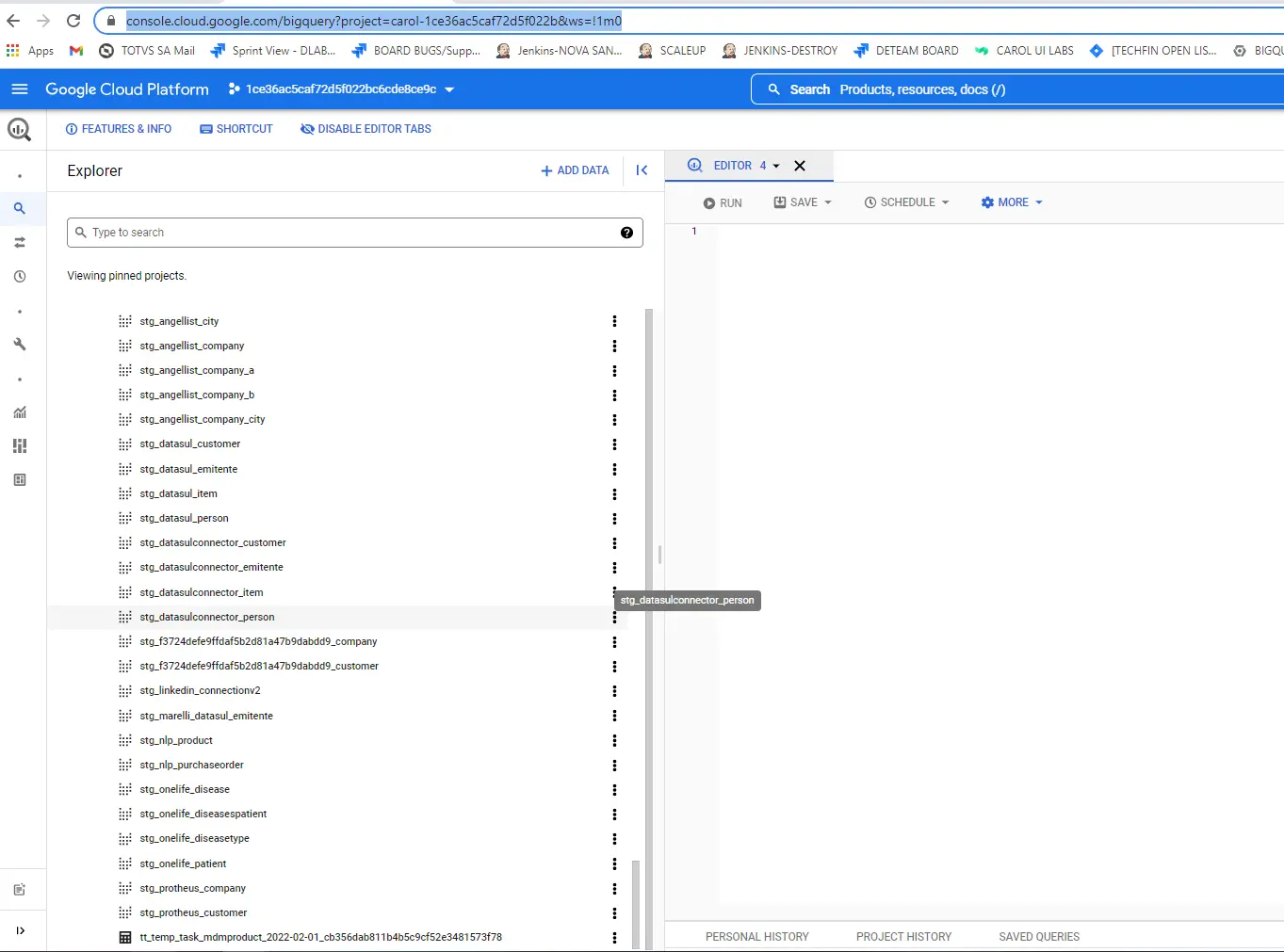
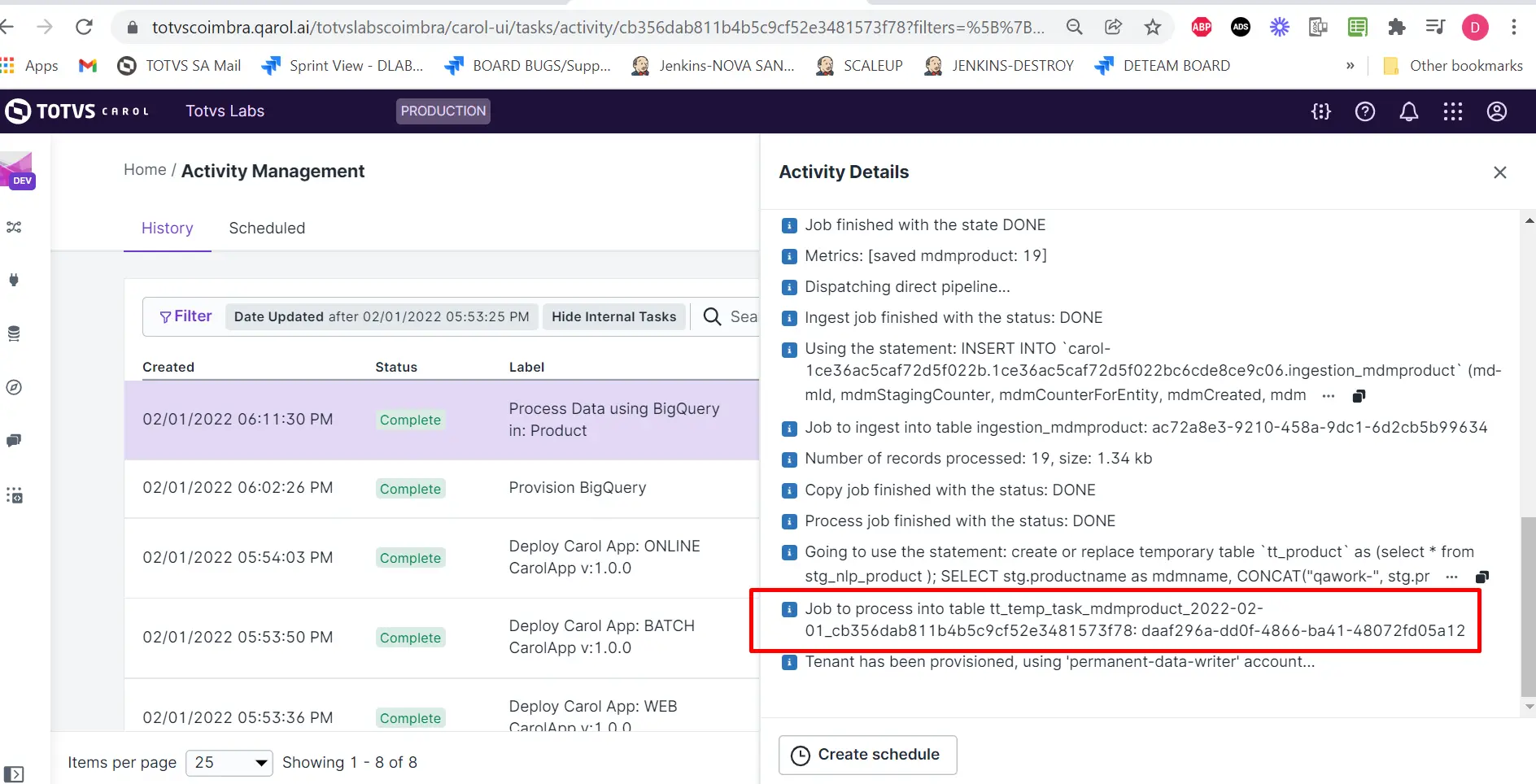
- Também podemos criar uma tarefa temporária através do processamento SQL conforme exemplificado abaixo:
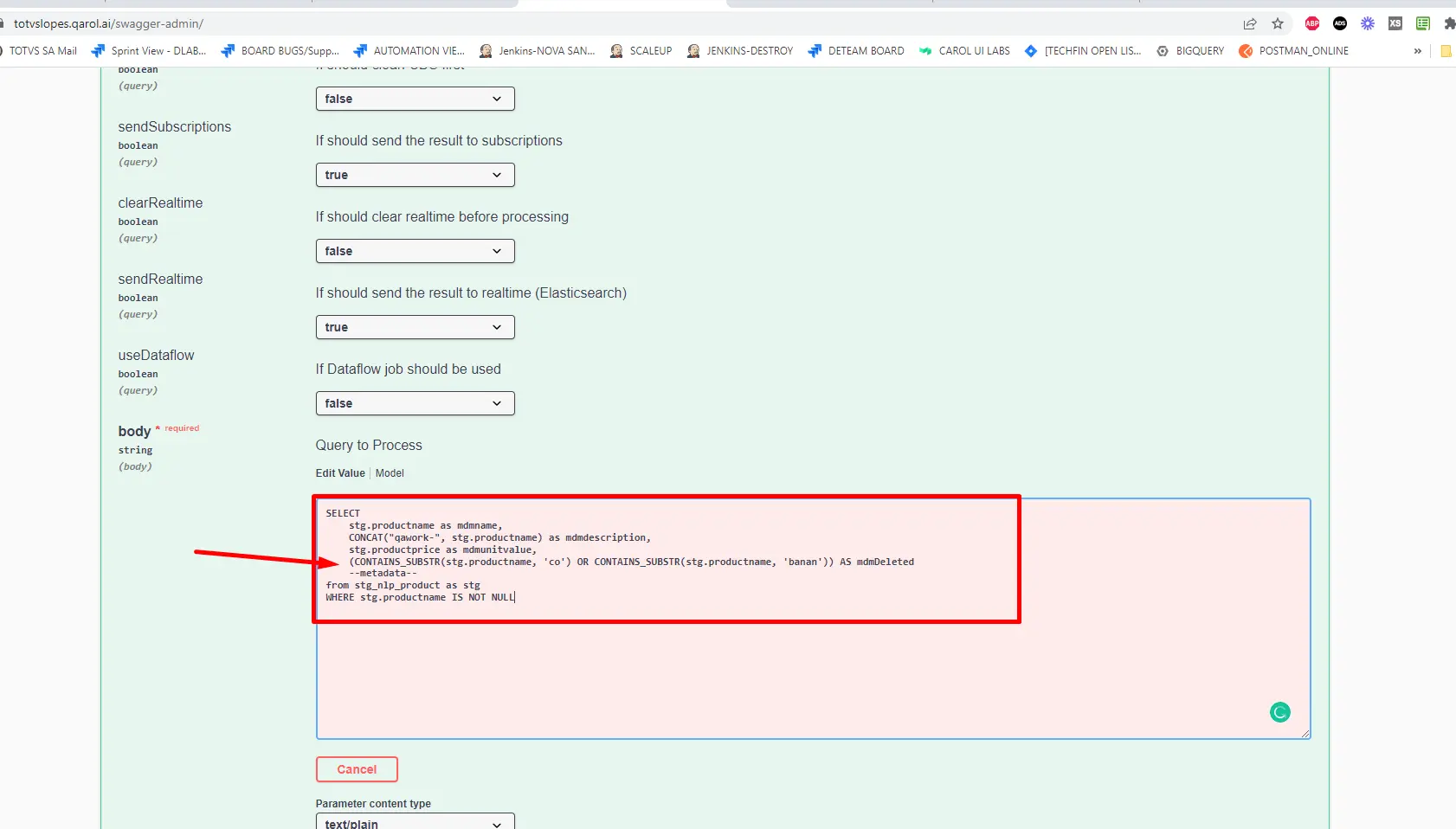
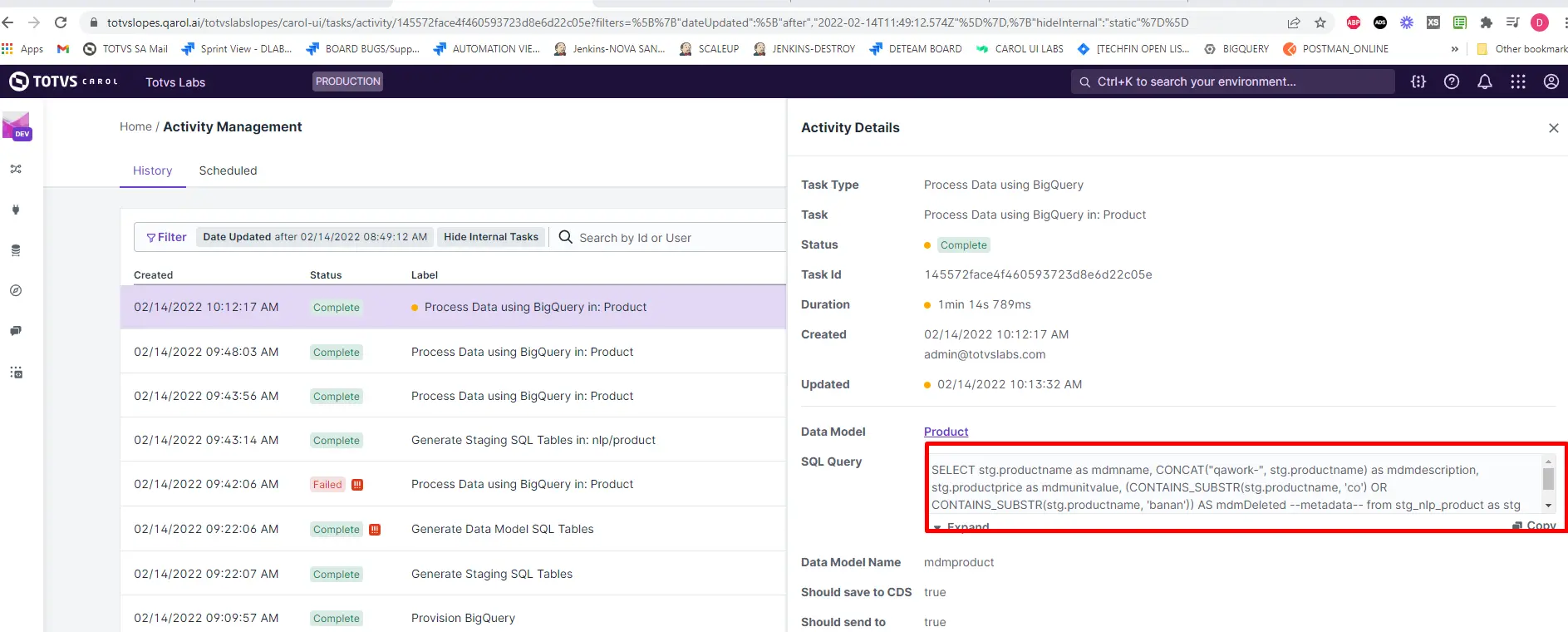
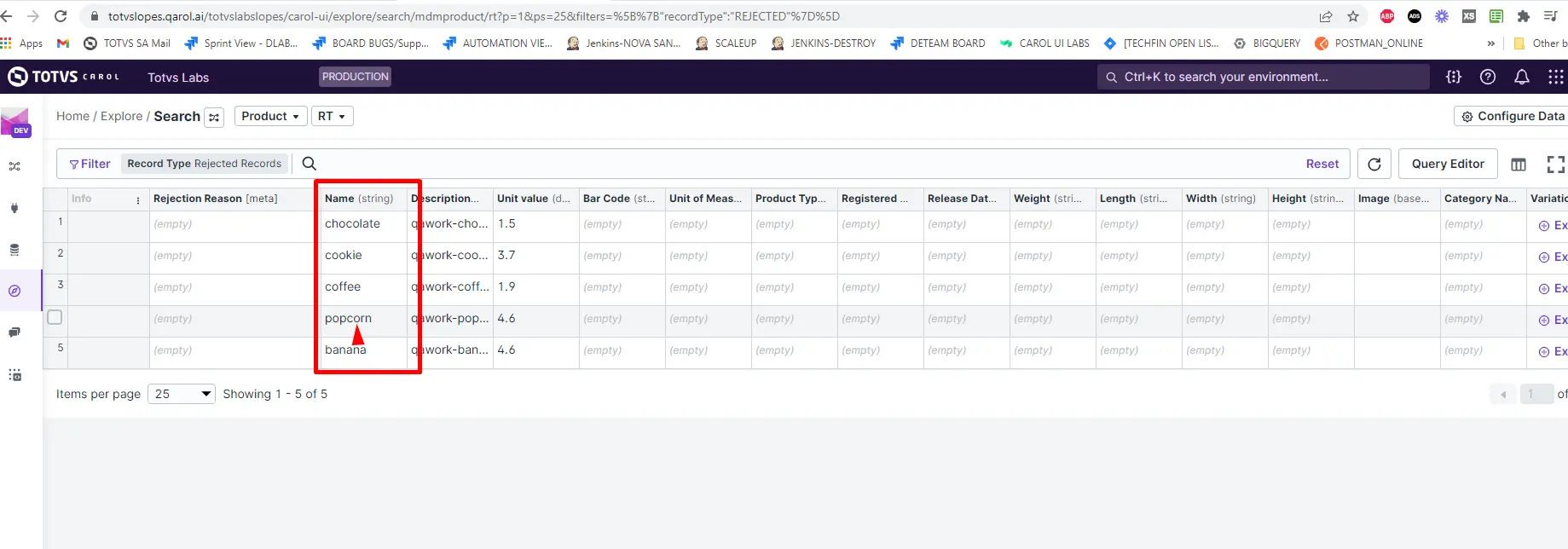
Gerando dados rejeitados para Realtime
Caso precisemos enviar dados rejeitados através do SQL Data Processing, podemos utilizar o endpoint também conforme exemplificado abaixo:
Conclusão
O processamento de dados SQL nos permite obter alguns benefícios, com destaque para desempenho, escalabilidade e custos. Alguns benefícios adicionais:
- Decoração de dados resolvida por consultas.
- Nenhuma operação ELT, pois tudo é resolvido em tabelas de preparação primárias (por exemplo, SA1).
- Regra de mapeamento e limpeza como código (SQL).
- Otimização de custos.
- Desempenho: processe grande quantidade de dados em segundos.
Essa estratégia de processamento de dados utiliza o conceito de processamento em lote, permitindo processar apenas uma janela específica de dados em vez de todos os dados o tempo todo.
Gerando erros em pipelines SQL (interrompendo a execução da pipeline)
O BigQuery permite a geração de erros para forçar a interrupção da execução de pipelines SQL.
Para obter esse comportamento, precisamos usar a função ERROR, conforme demonstrado abaixo:
SELECT
IF((SELECT COUNT(*) FROM dataset.table) > 0,
'Okay',
ERROR('No rows in the table'))
Resolvendo problemas relacionado as pipelines SQL (Debugging)
Localizar tasks relacionadas a um registro golden record
Todas as tasks de processamento de dados (Process Data using BigQuery) geram uma tabela temporária que disponibiliza os dados processados por um período de 3 dias. Durante esse período podemos executar um processo de debug que permite mapear todos os estágios do processamento de dados.
Vamos considerar o cenário que possuímos o golden record de um Data Model mdbusinesspartnergroup com o atributo businesspartnergroup_id com o valor 60576223992e7957cf09a746c99783ec.
Revisando uma task de processamento de dados:
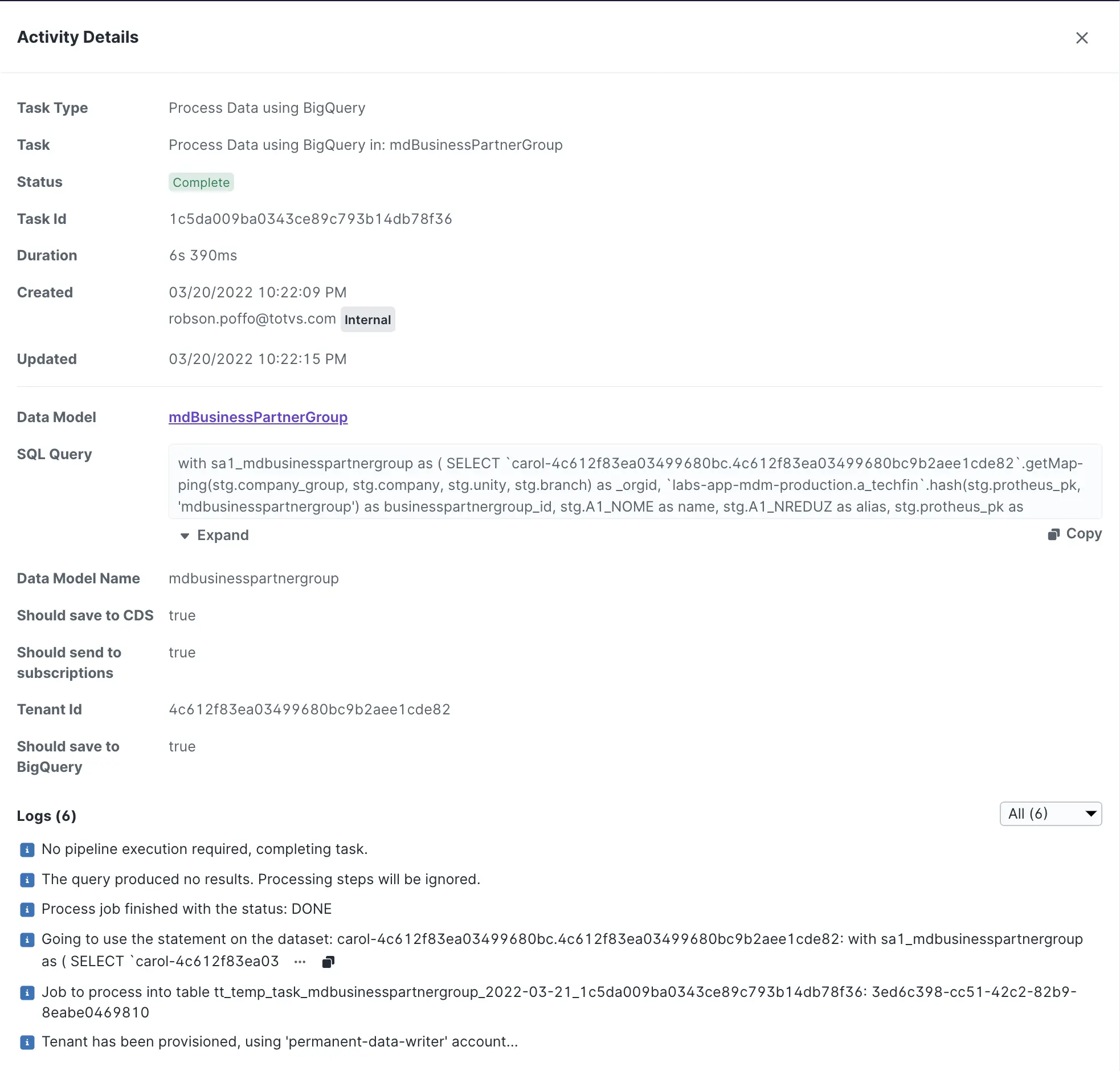
As tasks de processamento de dados possuem duas características importantes:
- datasetID / projeto
(carol-4c612f83ea03499680bc.4c612f83ea03499680bc9b2aee1cde82). - tabela temporária
(tt_temp_task_mdbusinesspartnergroup_2022-03-21_1c5da009ba0343ce89c793b14db78f36).
A tabela temporária é formada da seguinte forma:
tt_temp_task_: valor constante.mdbusinesspartnergroup: nome do data model.2022-03-21: data de execução da task no formato ISO.1c5da009ba0343ce89c793b14db78f36: ID da task na Carol.
Com os dados acima, podemos elaborar a seguinte query para buscar quais tasks processaram os dados para um registro específico:
select _TABLE_SUFFIX as tb, *
from `carol-4c612f83ea03499680bc.4c612f83ea03499680bc9b2aee1cde82`.`tt_temp_task_mdbusinesspartnergroup_2022-03-*`
where businesspartnergroup_id = '60576223992e7957cf09a746c99783ec'

A query acima busca todos os registros processados com o valor 60576223992e7957cf09a746c99783ec no atributo businesspartnergroup_id. Essa query usa o recurso de wildcard tables do Bigquery (tt_temp_task_mdbusinesspartnergroup_2022-03-*) que permite executar a query em várias tabelas, desta forma podemos rodar a query em várias tasks para descobrir quais processaram os dados.
Também utilizamos um recurso para obter o sufixo do nome da tabela, que neste caso é o taskID. Com isso, podemos buscar a task na interface da Carol e obter mais detalhes da execução da task, bem como se o registro foi adicionado ou removido (mdmDeleted true/false).
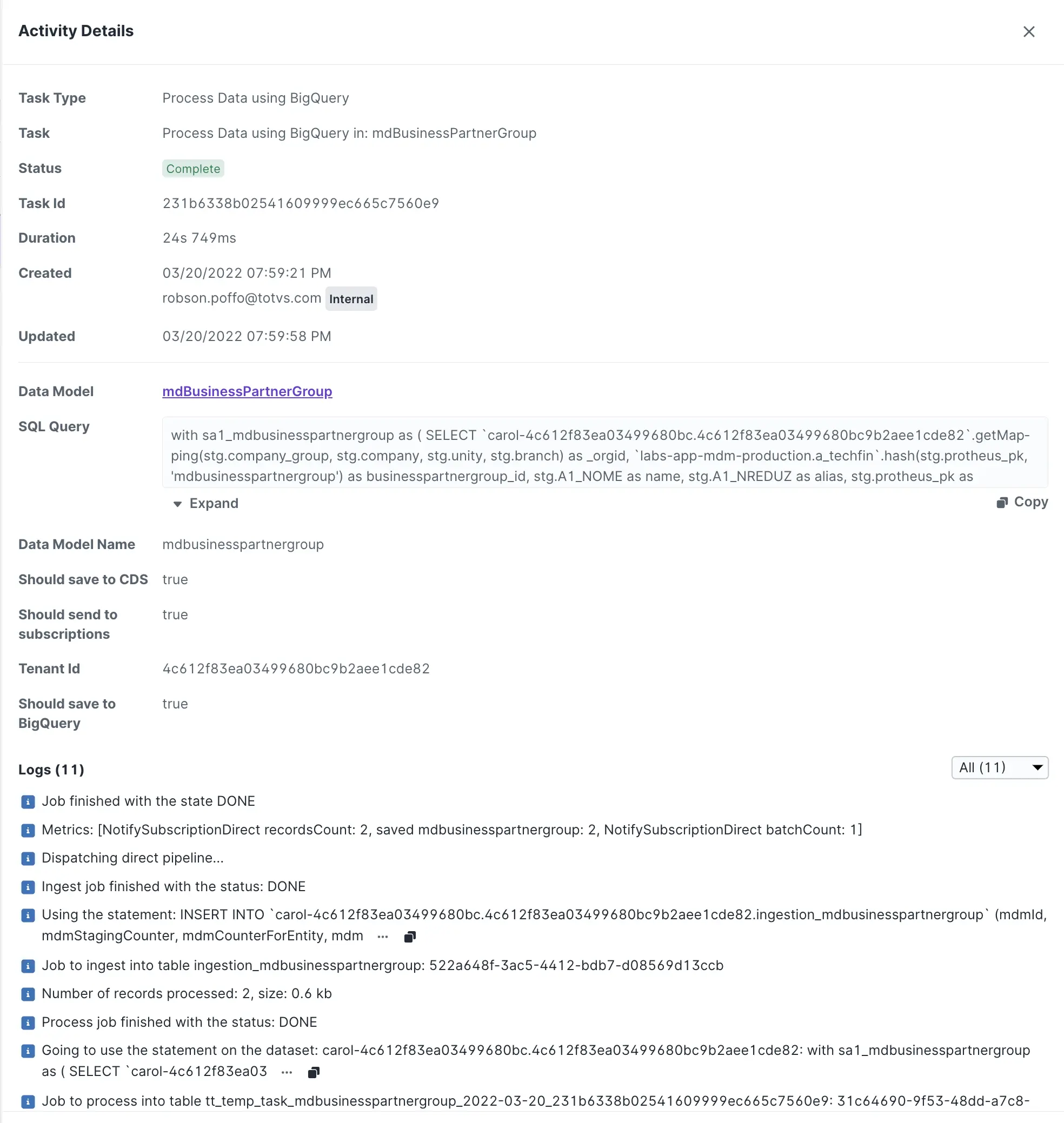
Obter versão da pipeline SQL através da task de execução
Para obter a query executada pela task, você deve abrir a task através do Activity Management.
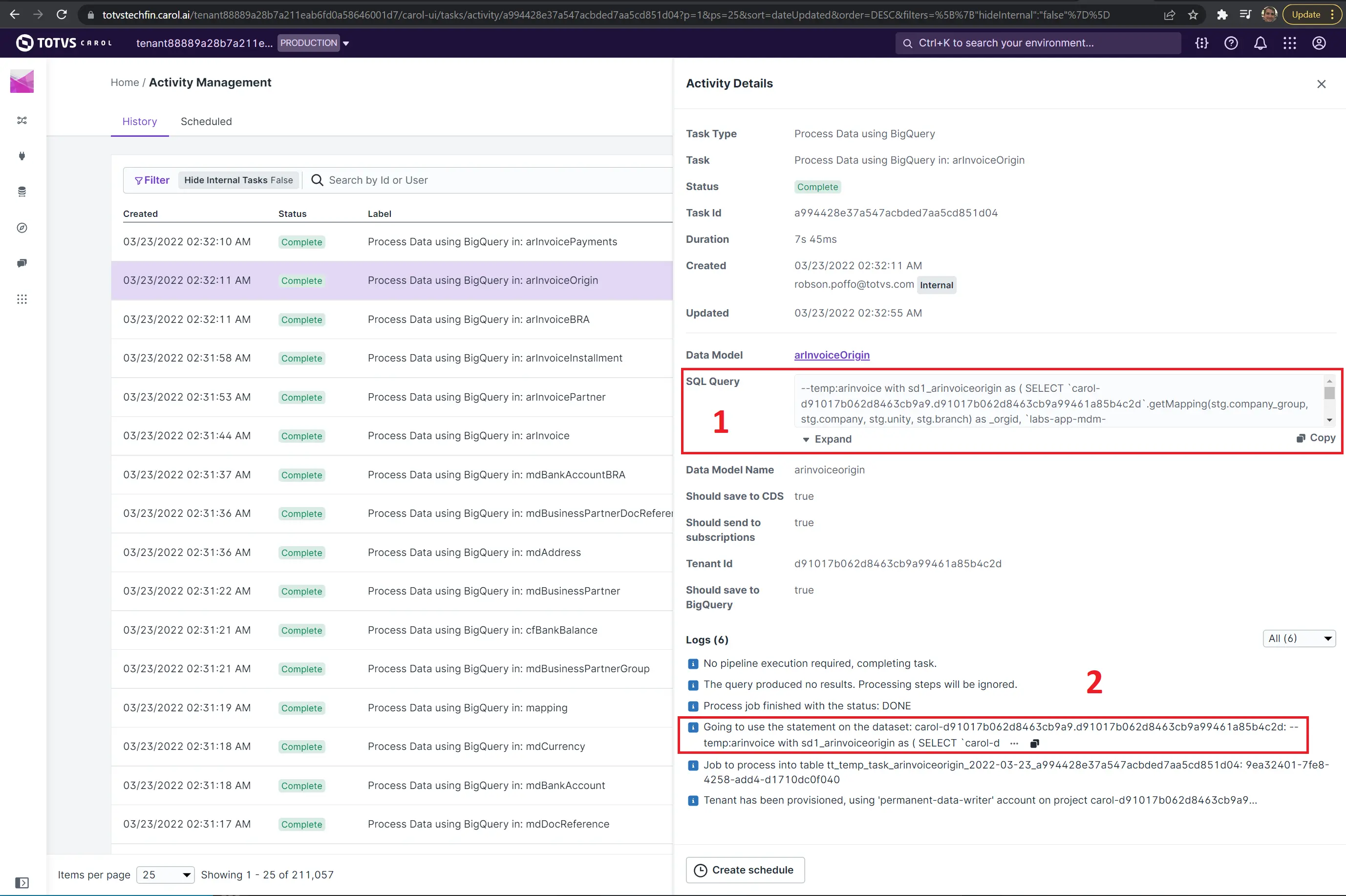
A task permite visualizar a query através de duas formas.
- Consultando a query no cabeçalho da task: essa query ainda não esta formatada. Atríbutos como
--metadata–ainda não foi substituído. - Query do log da task: essa query é a final executada, ela possui a troca das meta informações pelos valores correspondentes.
Visualizar os dados processados por uma task
As tasks de processamento de dados SQL geram uma tabela temporária para consulta dos dados processados pela task. Esses dados estão disponíveis por 3 (três) dias.
Os dados de uma task podem ser consultados através da seguinte query:
select _TABLE_SUFFIX as tb, *
from `carol-4c612f83ea03499680bc.4c612f83ea03499680bc9b2aee1cde82`.`tt_temp_task_mdbusinesspartnergroup_2022-03-*`
where businesspartnergroup_id = '60576223992e7957cf09a746c99783ec'
Os dados das tabelas temporárias de tasks estão disponíveis por apenas três (3) dias.
Esta query pode ser executada através do módulo Explore na Carol.
Visualizar os logs relacionados ao data subscription
A Carol disponibiliza o acesso aos dados de Data Subscription de três formas:
Org Admin
O usuário OrgAdmin terá acesso através da home page para visualizar graficamente as mensagens com o ack ou nAck de todos os ambientes abaixo desta organização.
Tenant Admin
O usuário Tenant Admin terá acesso através da home page para visualizar graficamente as mensagens com o ack ou nAck.
BigQuery
Neste fluxo, é possível executar queries numa tabela integrada ao Stackdriver permitindo consultar os logs através de queries.
A execução desta query deve ocorrer no Carol Insights Studio, na conexão carol-bigquery. Abra um chamado caso você tenha alguma dúvida.
Algumas queries de referência estão disponíveis:
- Consultar mensagens ligadas a um Golden Record (mdmID) subscription
select timestamp ts, *
from (
select
trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'tenant ')+6, 33)) tenantId,
*
from `a_logs.stdout`
) l
inner join (select distinct tenantId, tenantname, orgname from `da1c1280ac9b11e68e250401f8d88501`.dm_caroltenant) t on t.tenantid = l.tenantId
where jsonPayload.message like '%74512f15ede946348daf9bccd587d886%'
order by timestamp desc
limit 100
- Agregado do tipo de resposta das mensagens Data Subscription
select l.tenantId, t.tenantname, t.orgname, max(timestamp)
-- , array_agg(struct(responseCode, timestamp))
from (
select
trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'tenant ')+6, 33)) tenantId,
(
case
when SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, ' returned ')+10, 3) = "201" then "201"
when strpos(jsonPayload.message, '503 - Service Temporarily Unavailable') > 0 then "503"
when strpos(jsonPayload.message, '401 - Unauthorized. Golden') > 0 then "401"
else SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'message id')+29, 15)
END
) responseCode,
*
from `a_logs.stdout`
order by timestamp desc
) l
inner join (select distinct tenantId, tenantname, orgname from `da1c1280ac9b11e68e250401f8d88501`.dm_caroltenant) t on t.tenantid = l.tenantId
where
responseCode in ("401", "503")
and timestamp BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 4 HOUR) AND CURRENT_TIMESTAMP()
group by l.tenantId, t.tenantname, t.orgname
order by 4 desc
- Consultar tempo mínimo, máximo, médio e mediano da entrega de mensagens
with data as (
select ts, COALESCE[took, tookk] as took, * except(ts, took, tookk) from (
select timestamp ts, * except (timestamp, jsonpayload)
from (
select
trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'tenant ')+6, 33)) tenantId,
trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, ' Response of webhook ')+21, 33)) subscriptionId,
safe_cast((replace(trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'Created - ')+10, (strpos(jsonPayload.message, 'ms - '))-strpos(jsonPayload.message, 'Created - '))), 'ms - {"ack','')) as int64) took,
safe_cast((replace(trim(SUBSTRING(jsonPayload.message, strpos(jsonPayload.message, 'returned 200 - OK - ')+20, (strpos(jsonPayload.message, 'ms - '))-strpos(jsonPayload.message, 'returned 200 - OK -'))), 'ms - {"ack":true,"re','')) as int64) tookk,
a.timestamp, a.jsonPayload
from `labs-app-mdm-production.a_logs.stdout` a
) l
left join (select distinct tenantId, tenantname, orgname from `labs-app-mdm-production.da1c1280ac9b11e68e250401f8d88501`.dm_caroltenant) t on t.tenantid = l.tenantId
where timestamp between timestamp_sub(current_timestamp(), interval 1 DAY) and timestamp_sub(current_timestamp(), interval 0 DAY)
)
),
mediam as (
select distinct subscriptionId, percentile_disc(took, 0.5) over (partition by subscriptionId) _median
from data
)
select *
from (
select d.subscriptionId, min(took) _min, max(took) _max, avg(took) _avg, count(*) _total, max(ts) max_ts, min(ts) min_ts
from data d
where took is not null
group by subscriptionId
order by 3 desc
) d
inner join mediam m on d.subscriptionId = m.subscriptionId
Reenvio de dados via data subscription
O reenvio de dados para os aplicativos ligados ao Data Subscription pode ocorrer através de uma execução da pipeline na Carol, através do Plugin Carol no VSCode para codificação de pipelines SQL
Complemento: Definição do arquivo de manifesto de pipelines SQL
O manifest.json para processamento de pipelines tem a seguinte estrutura:
{
"defaults": {
"cronExpressions": ["0 */5 0 ? * * *"],
"prepareScripts": ["prepare.sql"]
},
"pipelines": [
{
"pipelineName": "apinvoice_main",
"pipelineDescription": "Pipeline for the apinvoice table, that uses se2, etc...",
"outputDataModelName": "apinvoice",
"overlapDeltaMinutes": 180,
"saveToCds": false,
"saveToUnified": true,
"sendToSubscriptions": true,
"cronExpressions": ["0 */5 0 ? * * *"],
"prepareScripts": ["apinvoice_prepare.sql"],
"timeZone": "America/Sao_Paulo",
"processScript": "apinvoice.sql",
"sourceEntities": {
"dataModels": [
{
"dataModelName": "mdcurrency"
}
],
"stagings": [
{
"connectorName": "protheus_carol",
"stagingName": "se2"
}
]
}
}
]
}
A seção defaults contém as propriedades aplicáveis a todos os pipelines. No entanto, prepareScripts, nesta seção, só é executado na primeira vez que o pipeline é instalado.
Os seguintes campos são configuráveis:
cronExpressions: os agendamentos nos quais o pipeline deve ser executado. Esta ferramenta pode ajudar a gerar/analisar expressões: https://www.freeformatter.com/cron-expression-generator-quartz.htmlprepareScripts: o script de preparação que deve ser executado quando o pipeline é instalado (padrão) ou em cada execução do pipeline (pipelines).pipelines: lista de pipelines nesse manifestopipelineName: identificador exclusivo para o pipeline (no aplicativo)pipelineDescription: breve descrição do propósito do pipelineoutputDataModelName: nome do modelo de dados de saída que receberá os dadosoverlapDeltaMinutes: valor (em minutos) para que será usado para calcular min_date na instrução SQL do pipeline para sobreposição de processamento de dadossaveToCds: se os registros processados devem ser salvos no CDS. Em geral, não recomendamos utilizar essa solução pois os dados estão sendo persistidos no Bigquery.saveToUnified: se os registros processados devem ser salvos no App Unified TenantsendToSubscriptions: se os registros processados devem ser enviados para assinaturas/webhooks- processScript: o script que será usado para processar os dados.
sourceEntities: as entidades que são utilizadas neste processamento, utilizadas para rastreabilidade e cópia de dados no onboard inicial dos clientes.
Executando pipelines SQL de Apps em um ambiente de desenvolvimento via API/CURL
- Esta é uma requisição HTTP POST usada para executar uma ou mais pipelines SQL de um ou mais Carol App em um ambiente de desenvolvimento. O corpo da requisição contém o ID do App e uma lista com os nomes das pipelines a serem processadas além de especificar o ambiente no cabeçalho da requisição.
- Outras configurações não informadas na requisição são herdadas no manifest do app.
- Em caso de sucesso, após a requisição é esperada a criação de uma task para cada pipeline no ambiente.
- Segue o modelo da requisição 1, que processa pipeline com delta minutes:
curl -X 'POST' \
'https://api.carol.ai/api/v4/carolApps/pipelines/process' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer TOKEN' \
-d '{"processPipelines":{"CAROL_APP_ID":["NOME_PIPELINE_1","NOME_PIPELINE_2"]},"deltaMinutes":VALOR_EM_MINUTOS}'
- Segue o modelo da requisição 2, que podemos limpar o Data Model e processar todos os dados da Stage.
curl -X 'POST' \
'https://api.carol.ai/api/v4/carolApps/pipelines/process' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer TOKEN' \
-d '{"processPipelines":{"CAROL_APP_ID":["NOME_PIPELINE_1","NOME_PIPELINE_2"]},"cleanUp":true,"processAllData":true}'
- Segue o modelo da requisição 3, que podemos apenas processar todos os dados da Stage.
curl -X 'POST' \
'https://api.carol.ai/api/v4/carolApps/pipelines/process' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer TOKEN' \
-d '{"processPipelines":{"CAROL_APP_ID":["NOME_PIPELINE_1","NOME_PIPELINE_2"]},"processAllData":true}'
- Definição de parâmetros
| Nome do Parâmetro | Descrição |
|---|---|
| CAROL_APP_ID | ID do Carol App que contém as pipelines a serem executadas. Cada chave no objeto processPipelines representa um App ID possibilitando processar pipelines de mais de um app por requisição. |
| NOME_PIPELINE_1, NOME_PIPELINE_2 | Nomes das pipelines SQL que serão executadas. Podem ser múltiplas, informadas como array. |
| VALOR_EM_MINUTOS | Intervalo de tempo em minutos do campo deltaMinutes já definido acima. |
| TOKEN | Bearer token de autenticação utilizado para autorizar a execução da pipeline. O ambiente que gerou o TOKEN será o ambiente de processamento. |
| cleanUp | true apaga os dados do Data Model antes de processar os dados. |
| processAllData | true processa todos os dados da Stage. |
| Content-Type (header) | Tipo de conteúdo do corpo da requisição. Deve ser application/json. |
| accept (header) | Tipo de resposta esperado da API. Geralmente application/json. |
- OBS - O id do app pode ser visto no ambiente dev do app na url ao acessar o app, como exemplo na imagem abaixo.

- Principais campos do Retorno
| Nome do Campo | Descrição |
|---|---|
| data | Array contendo os objetos de execução das pipelines (tasks). |
| mdmTaskStatus | Status da task de execução, por exemplo: READY, RUNNING, FAILED. |
| mdmTaskType | Tipo da task executada, nesse caso BIGQUERY_PROCESS_DATA. |
| mdmTenantId | ID do tenant/ambiente onde a pipeline foi executada. |
| success | Booleano que indica se a requisição foi aceita com sucesso (true ou false). |
- Exemplo de requisição:
curl -X 'POST' \
'https://api.carol.ai/api/v4/carolApps/pipelines/process' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer c1c48cf78d37424c98afc3642c999999' \
-d '{"processPipelines":{"d36d1ba458e945e2905a28258f36284c":["customer","records"]},"deltaMinutes":0}'
-
Este é um exemplo da requisição que inicia a execução de duas pipelines SQL, customer e records, de um Carol App específico (d36d1ba458e945e2905a28258f36284c) no ambiente tenant id (6e9f181451c34328832adb24e6999999), pois foi o ambiente que gerou o token. O valor deltaMinutes passado é 0 e o token utilizado foi c1c48cf78d37424c98afc3642c999999.
-
Resultado esperado: Tasks criadas no ambiente

- Exemplo de retorno
{
"data": [
{
"mdmTaskStatus": "READY",
"mdmTaskType": "BIGQUERY_PROCESS_DATA",
"mdmData": {
"pipelineDefinition": {
"pipelineName": "customer",
"pipelineDescription": "customer",
"outputDataModelName": "customer",
"fanOut": true,
"sendTo": {
"bigquery": {"customer": true, "unified": true},
"realtime": false
}
},
"tenantId": "6e9f181451c34328832adb24e6999999",
"carolAppName": "appfortestsongit9999"
},
"mdmCreated": "2025-10-21T17:22:07.092Z",
"mdmCreatedUser": "sandro.menezes@totvs.com.br"
},
{
"mdmTaskStatus": "READY",
"mdmTaskType": "BIGQUERY_PROCESS_DATA",
"mdmData": {
"pipelineDefinition": {
"pipelineName": "records",
"pipelineDescription": "records",
"outputDataModelName": "records",
"fanOut": true,
"sendTo": {
"bigquery": {"customer": true, "unified": true},
"realtime": false
}
},
"tenantId": "6e9f181451c34328832adb24e6999999",
"carolAppName": "appfortestsongit9999"
},
"mdmCreated": "2025-10-21T17:22:07.114Z",
"mdmCreatedUser": "sandro.menezes@totvs.com.br"
}
],
"success": true
}
Executando pipelines SQL de Apps em um ambiente unificado via API/CURL
-
Esta é uma requisição HTTP POST usada para executar uma ou mais pipelines SQL do Carol App em um ambiente unificado para tenants específicas. O corpo da requisição contém o ID do App, uma lista com os nomes das pipelines a serem processadas, além de uma lista de tenants do cliente. Nesse caso, as pipelines irão processar exclusivamente os dados das tenants informadas na requisição. O ambiente unificado é especificado no cabeçalho.
-
Em caso de sucesso, após a requisição é esperada a criação de uma task para cada pipeline no ambiente unificado.
-
Segue o modelo da requisição 1, que processa pipelines com delta minutes no ambiente unificado que processe dados de apenas algumas tenants de cliente:
curl 'https://api.carol.ai/api/v1/tenantApps/pipelines/process' \
-H 'accept: application/json' \
-H 'content-type: application/json' \
-H 'authorization: TOKEN_UNIFICADO' \
-d '{
"processPipelines": {
"CAROL_APP_ID": ["NOME_PIPELINE_1", "NOME_PIPELINE_2"]
},
"customerTenantIds": ["TENANT_ID_1", "TENANT_ID_2"],
"deltaMinutes": VALOR_EM_MINUTOS
}'
- Se na requisição for necessário processar todos os dados das tenants nas pipelines podemos utilizar o modelo da requisição 2. Esse modelo utiliza no corpo da requisição a flag processAllData em vez de deltaMinutes.
curl 'https://api.carol.ai/api/v1/tenantApps/pipelines/process' \
-H 'accept: application/json' \
-H 'content-type: application/json' \
-H 'authorization: TOKEN_UNIFICADO' \
-d '{
"processPipelines": {
"CAROL_APP_ID": ["NOME_PIPELINE_1", "NOME_PIPELINE_2"]
},
"customerTenantIds": ["TENANT_ID_1", "TENANT_ID_2"],
"processAllData": true
}'
- Exemplo de requisição 2:
curl -X 'POST' \
'https://api.carol.ai/api/v1/tenantApps/pipelines/process' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'authorization: 27a36bb3e7f74ee1b291ea9f9999999' \
-d '{
"processPipelines": {
"15e064faccae4a7daf1466c708ac8453": [
"organization_pipeline"
]
},
"customerTenantIds": [
"5cdd6773b30644ff851b4d4e4d878f45"
],
"processAllData": true
}'
- No exemplo da requisição, 27a36bb3e7f74ee1b291ea9f9999999 é o token do ambiente unificado utilizado para autenticar o processamento, 15e064faccae4a7daf1466c708ac8453 é o ID do Carol App que contém a pipeline a ser executada, organization_pipeline é o nome da pipeline SQL que será processada dentro desse App, 5cdd6773b30644ff851b4d4e4d878f45 é o tenantId do cliente cujos dados serão processados dentre dados de todas as tenants no ambiente unificado, e processAllData: true indica que a pipeline deve processar todos os dados deste tenant em vez de utilizar janelas de tempo com delta minutes.
Executando pipelines SQL de Apps em um ambiente unificado via UI da Carol
- A opção de processamento de pipelines no ambiente unificado está disponível no menu lateral esquerdo, na opção Pipelines, conforme destacado em azul na imagem abaixo.
- Após selecionar a pipeline, clique na opção de três pontos, conforme o destaque em azul na imagem abaixo.

- Será exibida a tela com as opções conforme a imagem a seguir.
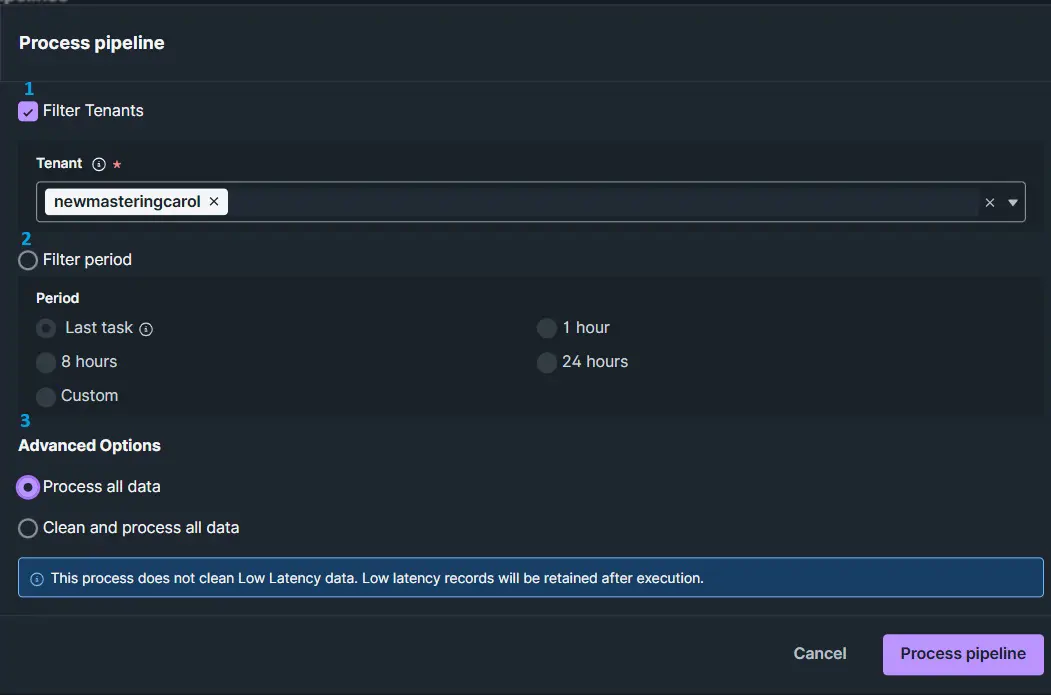
- Na imagem acima, destacamos três opções enumeradas em azul, onde:
- 1 - Devemos usar essa opção quando desejamos selecionar tenants de clientes específicas que terão seus dados processados na pipeline.Essa opção unciona apenas se a pipeline contemplar Nota Filtro Tenants citada em acima nesse documento.
- 2 - Opções de janela de período de tempo em que os dados serão processados, utilizada quando não é necessário reprocessar todos os dados.
- 3 - Opção de reprocessar todos os dados, desconsiderando a janela de período de tempo, e também a opção de realizar a limpeza de todos os dados do Data Model dessa pipeline antes de reprocessar tudo.
Boas práticas
Prática 01: Processamento Parcial
Em algumas estratégias de processamento parcial de pipelines é utilizada a informação do último registro de uma staging table processado que está armazenado no Data Model correspondente. Com isso é possível processar apenas registros de uma staging table que ainda não foram processados. Essa informação é representada pelo ultimo valor do campo mdmStagingCounter no Data Model em questão, por exemplo o Data Model fictício DATAMODELNAME. A forma mais otimizada de buscar essa informação no Data Model DATAMODELNAME, é buscando pela última partição conforme comando SQL abaixo.
SELECT
MAX(mdmStagingCounter) AS max,
RAND()
FROM
DATAMODELNAME dm
WHERE dm._ingestionDatetime >=
(
SELECT last_partition
FROM
(
SELECT
IFNULL(PARSE_DATE('%Y%m%d',MAX(partition_id)), DATETIME(TIMESTAMP_SECONDS(0))) AS last_partition
FROM
`INFORMATION_SCHEMA.PARTITIONS`
WHERE
table_name = 'ingestion_DATAMODELNAME'
AND partition_id <> '__NULL__'
)
)