Data models
Antes de começar
Dúvidas sobre o que é um Data model? → Veja mais informações na seção de conceitos.
Dúvidas sobre o que é um golden record? → Veja mais informações na seção de conceitos.
Listando data models
Para listar todos os data models da Tenant basta acessar o menu lateral esquerdo da plataforma e clicar sobre Data Models.

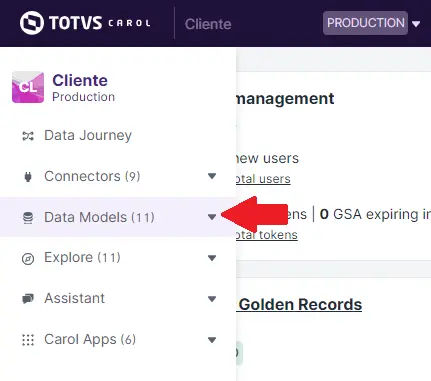
Este menu é auto expansível, portanto ao mover o mouse sobre o módulo é possível listar um data model específico.
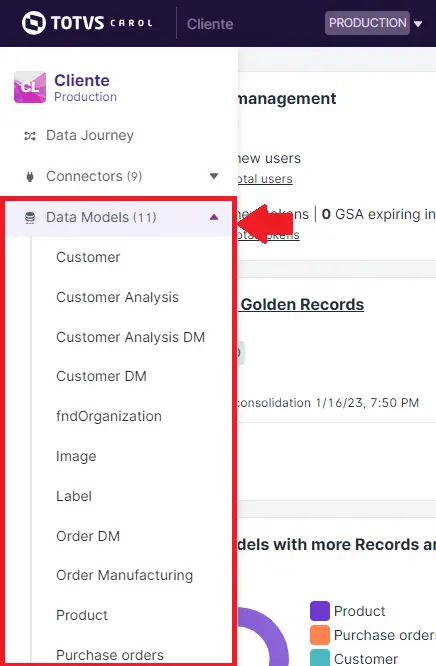
A seguir será apresentada a página Data Models contendo uma tabela com os data models representados em cada linha e os seus atributos nas colunas.
No rodapé da página é apresentada a quantidade de data models presentes na Tenant e a data da última consolidação executada.
No topo da página é possível aplicar opções de filtro, criar um data model manualmente, atualizar a página e visualizar relacionamentos.
Ao passar o mouse sobre as linhas é possível ainda configurar ou eliminar todos os registros do data model desejado.
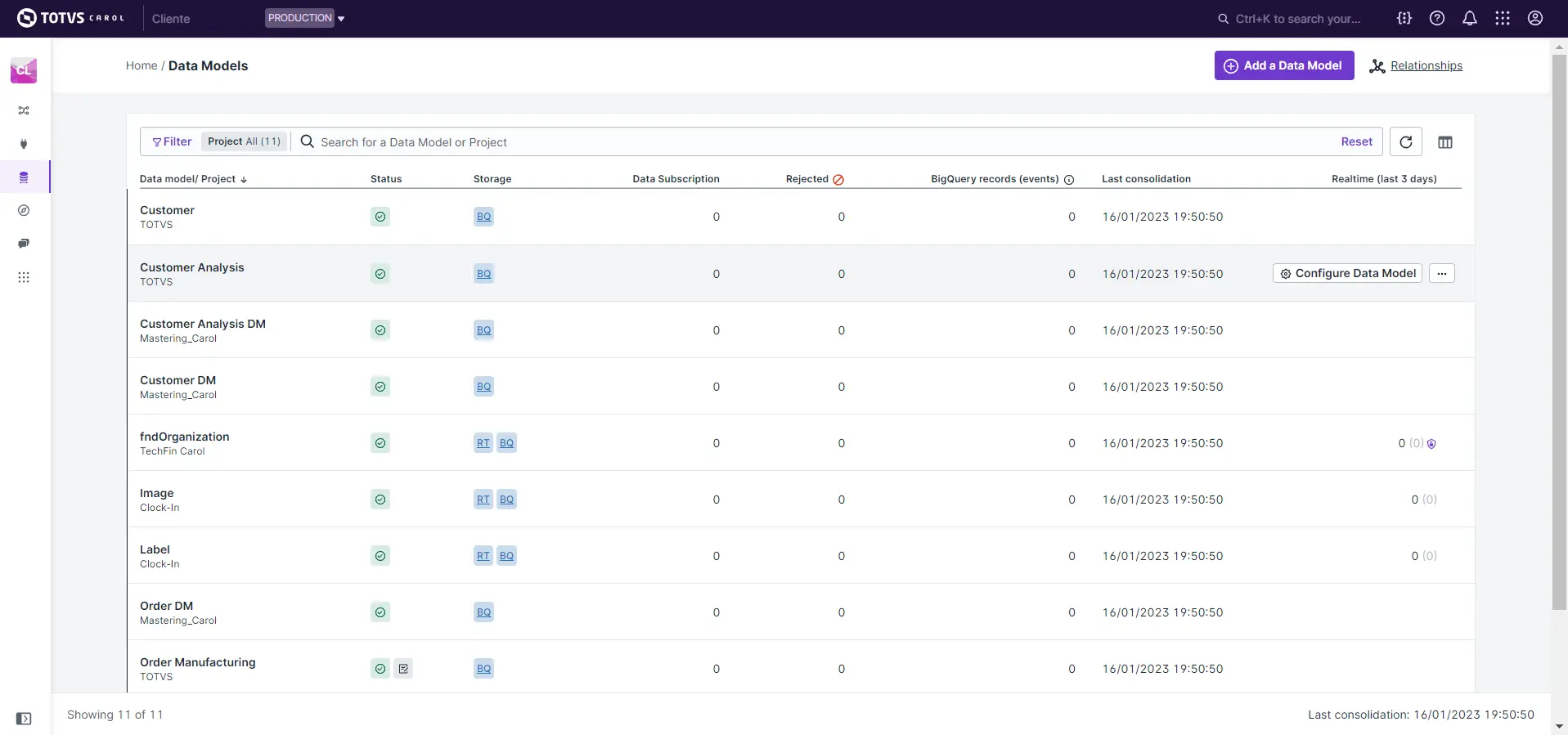
Em relação as colunas da tabela os seguintes atributos são apresentados a seguir:
Data model/Project: O nome do data model e projeto ao qual ele pertence.Status: situação do data model que pode ser has published ou has draft
ou has draft  .
.Storage: tipo de armazenamento utilizado pelo data model que pode ser BQ (BigQuery) ou RT (RealTime)Data Subscription: número de mensagens enviadas por subscrição de dados.Rejected: número de registros rejeitados.BigQuery records (events): número de registros armazenados no BigQuery e os seus eventos. Os eventos representam ações de inclusão de novos dados, alteração de registros existentes ou eliminação de registros existentes, tanto na staging area ou no golden record. Os eventos influenciam a quantidade final de registros armazenados no Big Query após o processo de consolidação dos registros. Os eventos podem impactar a quantidade de registro dependendo da ação que eles representam:- Atualização, não irá impactar a quantidade final de registros após a consolidação, uma vez que esse evento vai alterar um registro existente.
- Inserção, irá aumentar a quantidade final de registros após a consolidação.
- Eliminação, irá reduzir a quantidade final de registros após a consolidação.
Last consolidation: data da última consolidação executada com sucesso.Realtime (last 3 days): número de registros armazenados no RealTime e seus eventos nos últimos 3 dias.
Filtrando data models
É possível filtrar um ou mais data models utilizando-se das seguintes opções de filtro:
Project: por padrão é definidoAll, porém é possível selecionar os projetos a partir de uma lista de valores apresentada.Publish Status: pelo status da publicação, a partir de uma lista contendo os valoresHas Draft,Has Published,OnlyDraftouOnlyPublished.Storages: pelo tipo de armazenamento, a partir de uma lista contendo os valoresHas Realtime,Has SQLouNo Storage Type.Data Subscription: pela existência ou não de uma subscrição de dados configurada (Has DataSubscription|No DataSubscription).Realtime Records on last days: pela existência ou não de registros nos últimos 3 dias.
Além disto, é possível escrever diretamente na caixa de pesquisa o nome do data model ou projeto desejado.

Criando novo data model
A melhor maneira de criar novos data models se dá através do desenvolvimento de Carol Apps, desta forma o processo de criação torna-se automático a partir da instalação do Carol App. Como benefício além do ganho de produtividade, evitamos a falha humana ao reproduzir a mesma configuração em outras Tenants. → Veja mais informações em Carol App.
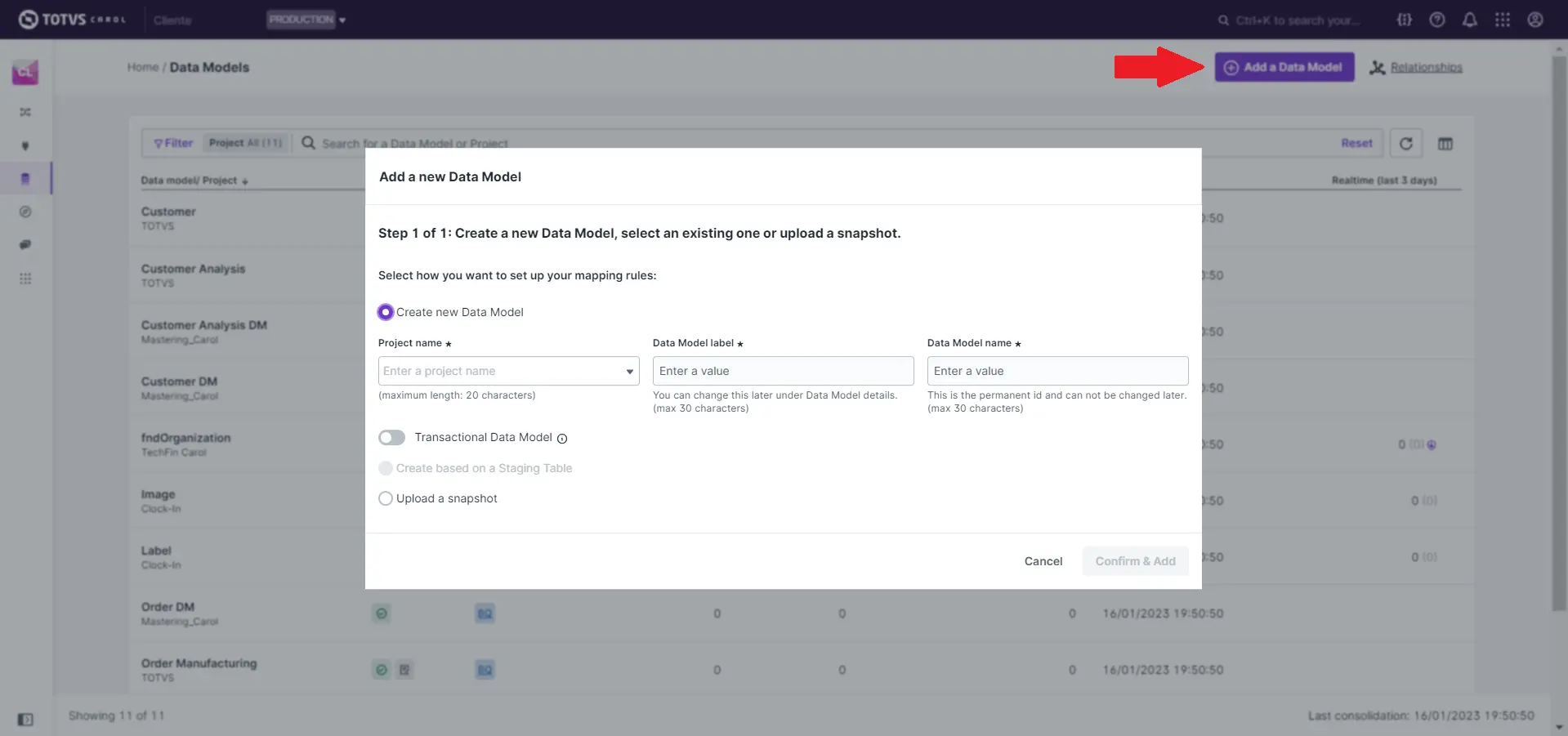
Para atender a situações específicas, basta clicar no botão Add a Data Model e seguir os passos na janela que é apresentada a seguir. Nesta janela existem 3 opções:
- Criar um novo data model informando os seguintes campos na janela:
Create new Data Model- Obrigatório
Project name: Nome do projeto.Data Model label: Rótulo utilizado para fins de visualização na plataforma.Data Model name: Nome pelo qual é registrado na plataforma e referenciado nas pipelines e queries.
- Opcional
Transactional Data Model: se marcado permite que registros com características de temporalidade (time series), ou seja com data e hora específica, sejam representados na forma de histograma na visualização por meio da páginaExplore. São exemplos de registros: ordens de compra e venda, recibos, pedidos, etc.
- Obrigatório
-
Criar baseado em uma tabela staging existente na Tenant:
Create based on a Staging Table
-
Criar um novo data model a partir da carga de arquivo no formato JSON contendo o schema do data model.
Upload a snapshot
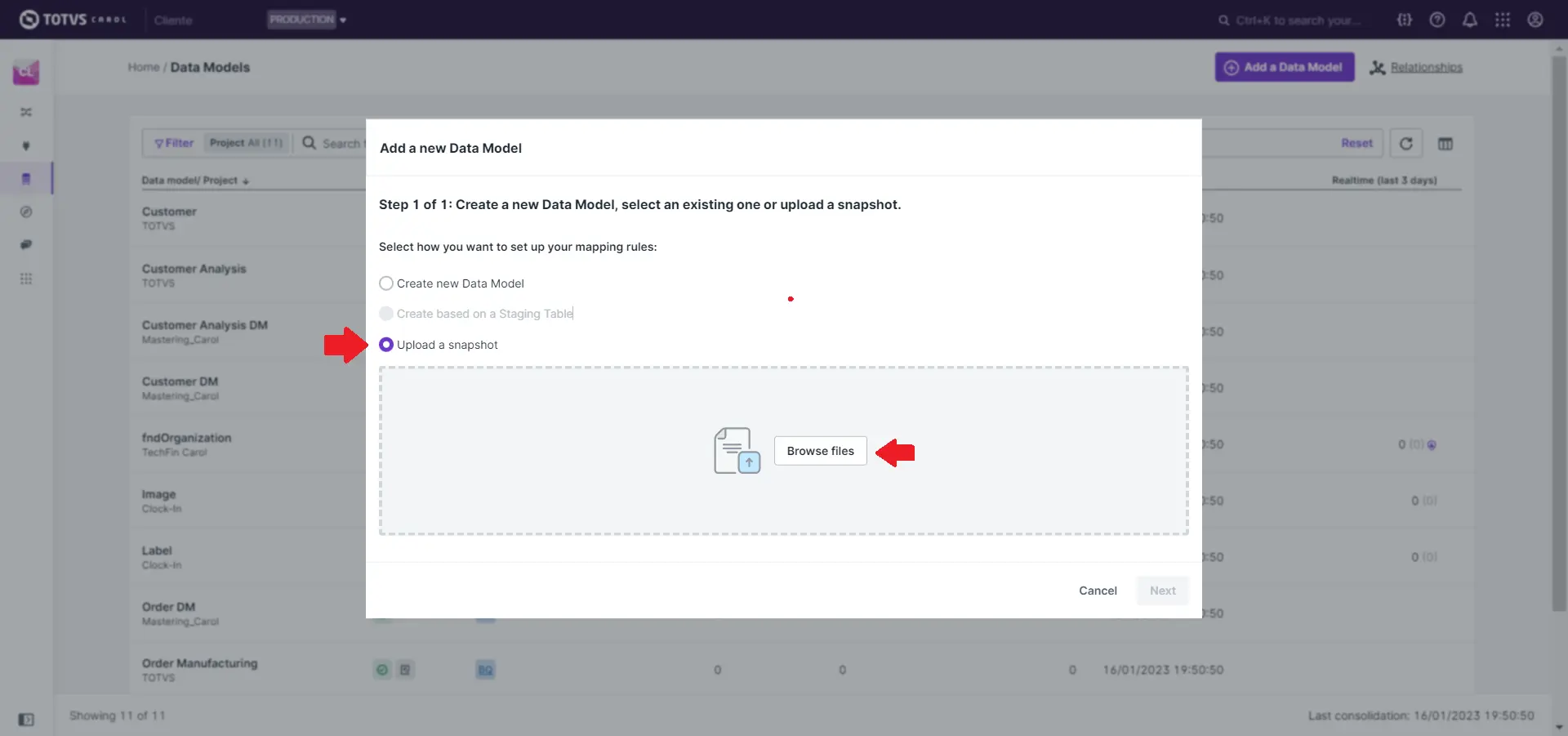
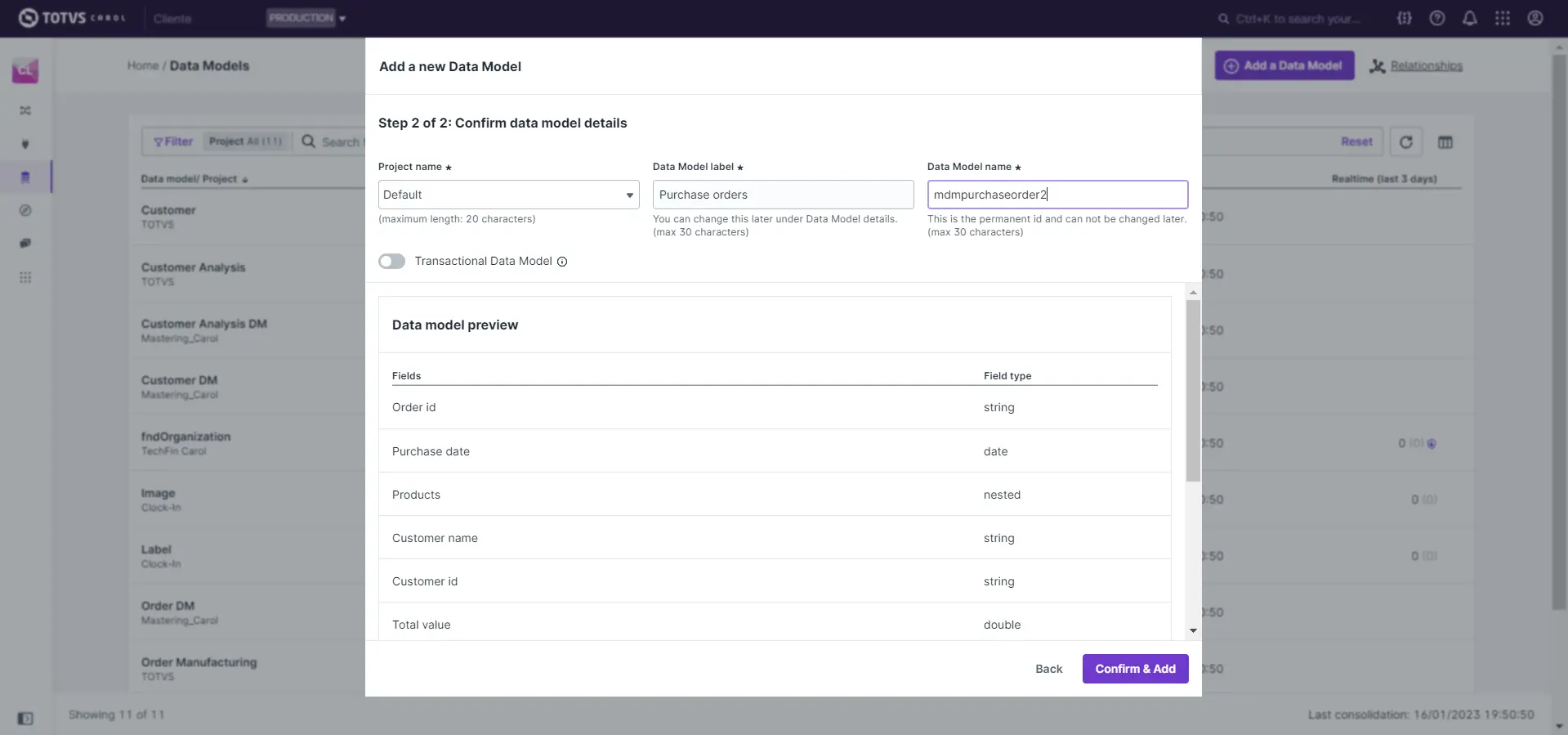
O data model recém criado permanecerá no status Draft até que seja publicado por meio do botão Publish.

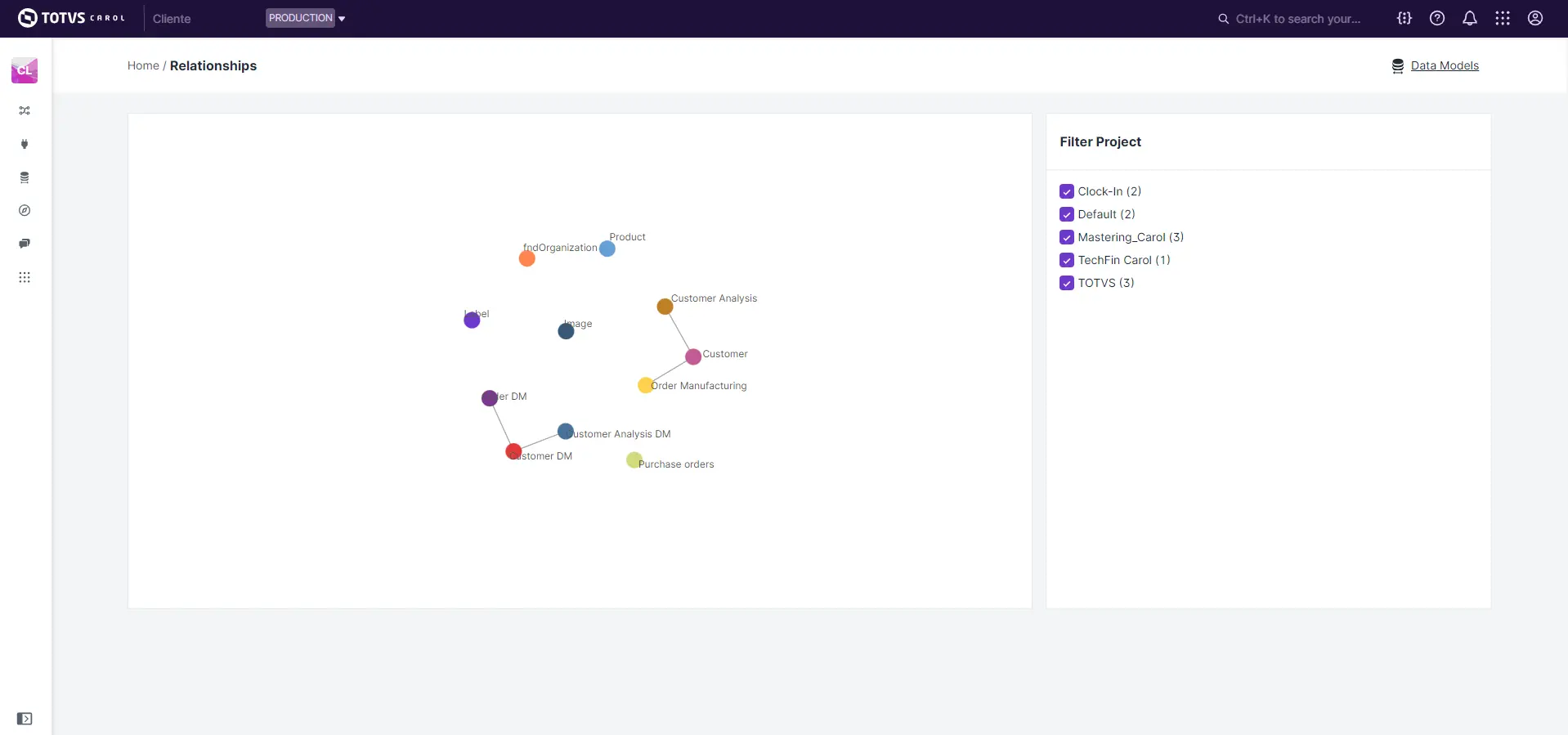
Visualizando relacionamentos
Esta é a maneira de conectar e criar a relação entre dois Data Models diferentes. Um exemplo é Customer e Order Manufacturing.
Configurando data model
Para acessar esta página ainda dentro da lista de data models passe o mouse sobre o data model desejado e clique no botão Configure Data Model.
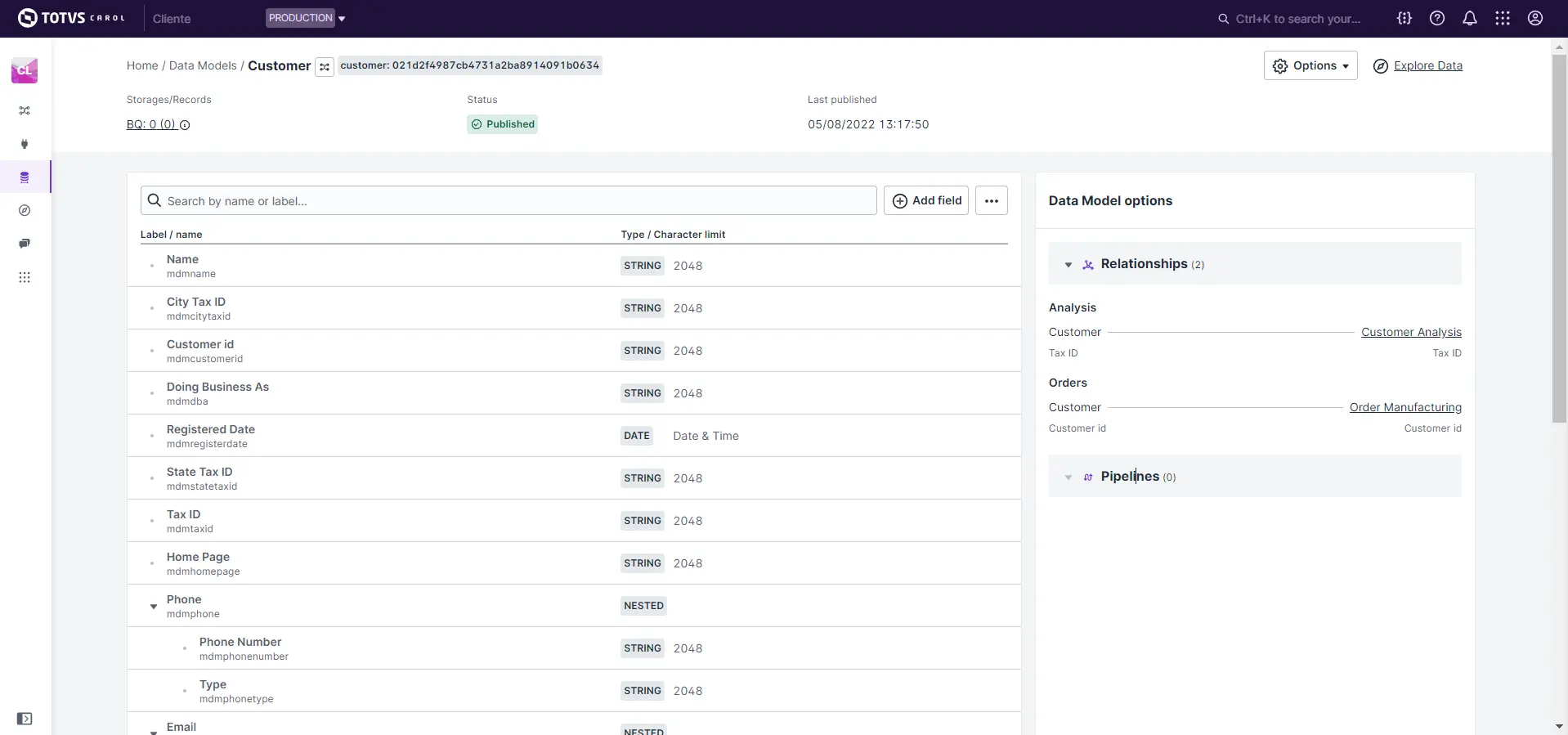
A seguir será apresentada a página do data model escolhido com os campos nas linhas e os seus atributos nas colunas da tabela.
No topo da tabela é possível aplicar opções de filtro e adicionar novos campos. À direita da tabela é possível editar os relacionamentos.
No topo da página é possível acessar o Data Journey ![]() , visualizar dados gerais do data model, editar configurações avançadas e visualizar registros no
, visualizar dados gerais do data model, editar configurações avançadas e visualizar registros no Explore.
Dados gerais do Data Model
ID e Nome do Data Model: é o código de identificação único e o nome utilizado em pipelines e queries.

Storage/Records: número total de registros e eventos no BigQuery.Status: situação do data model que pode ser Published ou Draft .Last published: data da última publicação.Options: botão para acesso as configurações avançadas.Explore Data: hyperlink para acesso a visualização de registros noExplore.
Filtro
A busca pode ser realizada de duas formas: por nome ou rótulo do campo.
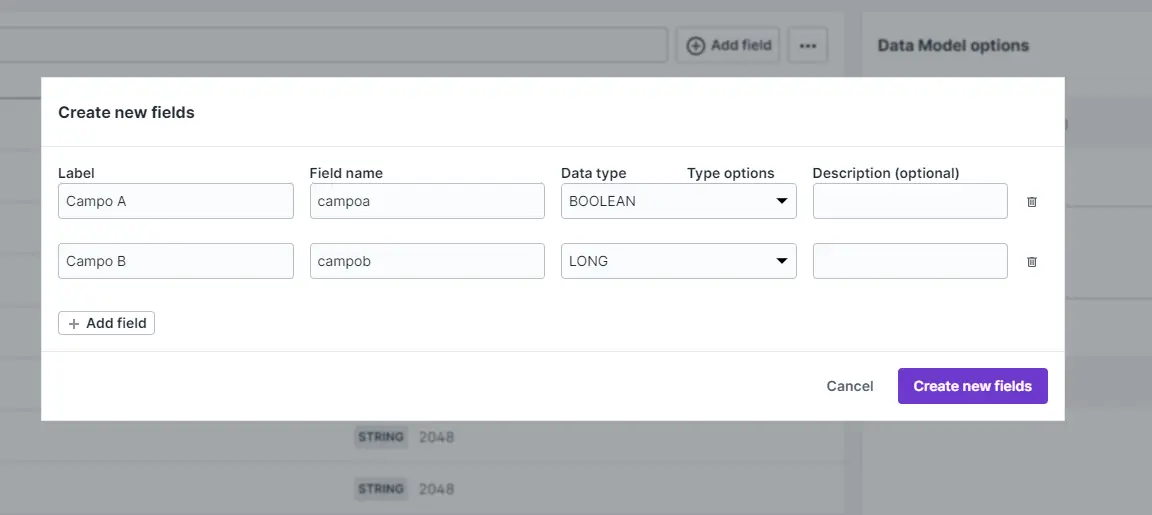
Novos campos
Ao clicar no botão Add Field será apresentada uma janela com opção em seu cabeçalho para consulta e um botão para a criação de novos campos, logo abaixo deles em formato de tabela consta a lista com os campos já existentes ou recém criados onde é possível habilitar ou desabilitar cada campo no data model.
Ao clicar no botão Create new devem ser informados os seguintes atributos para o novo campo:
Label: rótulo para visualização do campo.Field name: nome do campo utilizado como referência em pipelines e queries.Data type Type options: o tipo do atributo, que pode ser booleano, inteiro, entre outros por exemplo.Description (optional): uma descrição sobre o campo.+ Add field: botão para adicionar uma nova linha de campo.
Configurações Avançadas
Ao clicar no botão Options é exibida as seguintes opções:
Edit Data Model: permite a edição do label e do projeto.Download snapshot: gera um arquivo JSON com o schema do data model.Management and Subscription: permite a edição das configurações de gestão e subscrição de dados.Discard Draft Changes: descarta todas as mudanças realizadas no data model.Delete all records: elimina todos os registros do data model.Delete Data Model: elimina o data model e todos os seus regitros.

Management and Subscription
-
Data Management
-
BigQuery
Consolidate records: permite habilitar ou desabilitar o processo de consolidação de dados, ou seja, este processo identificará as versões dos dados e as excluirá, armazenando apenas uma única instância do registro. Por padrão, a plataforma sempre realiza a consolidação dos registros.
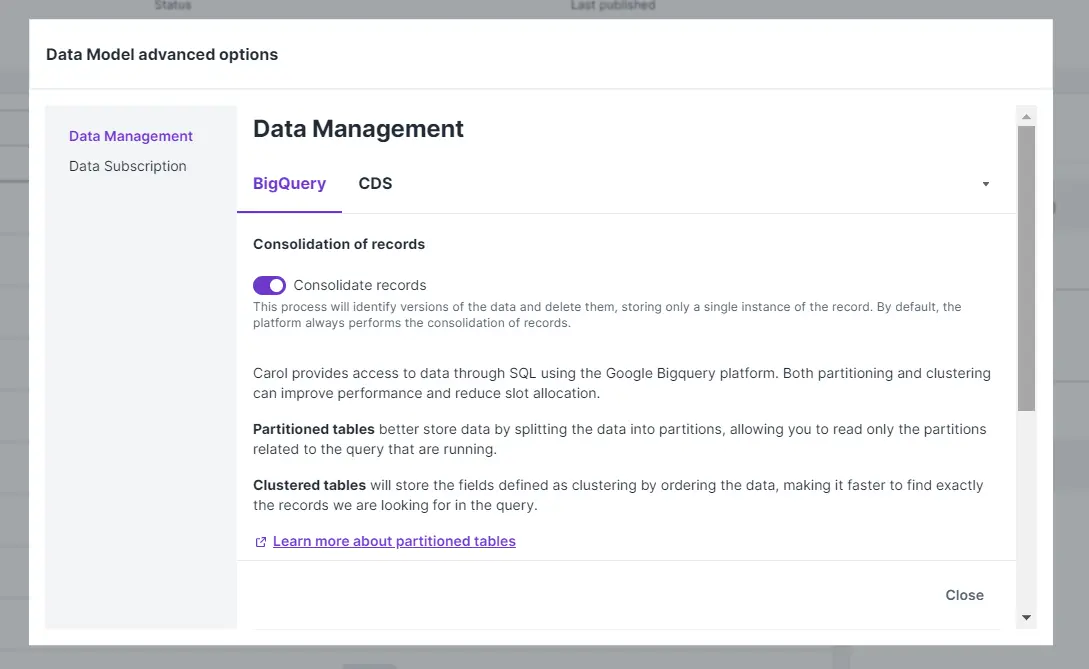
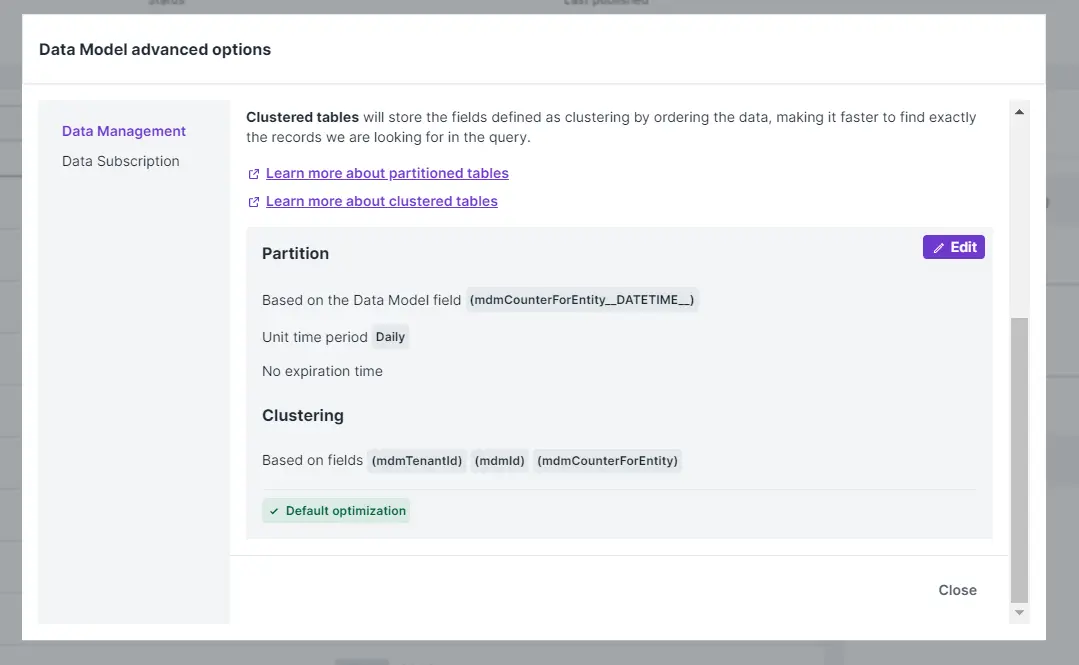
PartitioneClustering: A plataforma Carol fornece acesso aos dados por meio de SQL usando a plataforma Google BigQuery. Tanto o particionamento quanto o clustering podem melhorar o desempenho e reduzir a alocação de slots. As tabelas particionadas armazenam melhor os dados dividindo-os em partições, permitindo que você leia apenas as partições relacionadas à consulta que está sendo executada. As tabelas clusterizadas irão armazenar os campos definidos como clustering ordenando os dados, tornando mais rápido encontrar exatamente os registros que procuramos na consulta.
→ Saiba mais sobre tabelas particionadas
→ Saiba mais sobre tabelas em cluster
Tanto o particionamento quanto o clustering já vem habilitados e configurados por padrão em todos os data models criados na plataforma, mas podem ser desabilitados ou modificados, caso necessário.
-
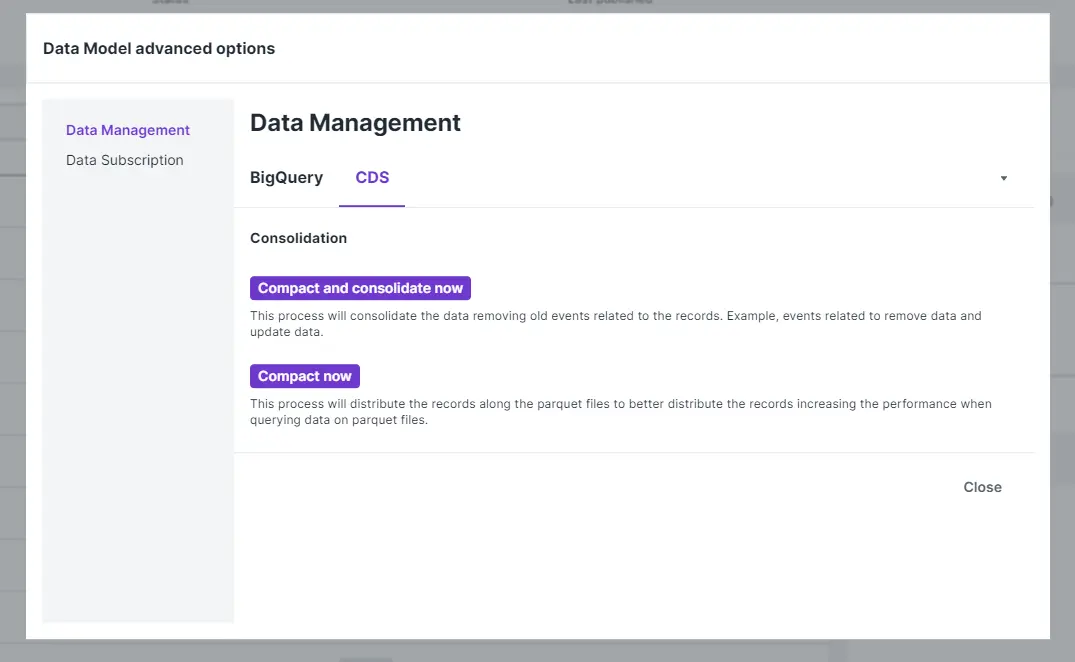
CDS
Compact and consolidate now: Este processo irá consolidar os dados removendo eventos antigos relacionados aos registros. Exemplo, eventos relacionados à remoção de dados e atualização de dados.Compact now: Este processo distribuirá os registros ao longo dos arquivos parquet para melhor distribuir os registros aumentando o desempenho na consulta de dados em arquivos parquet.
-
-
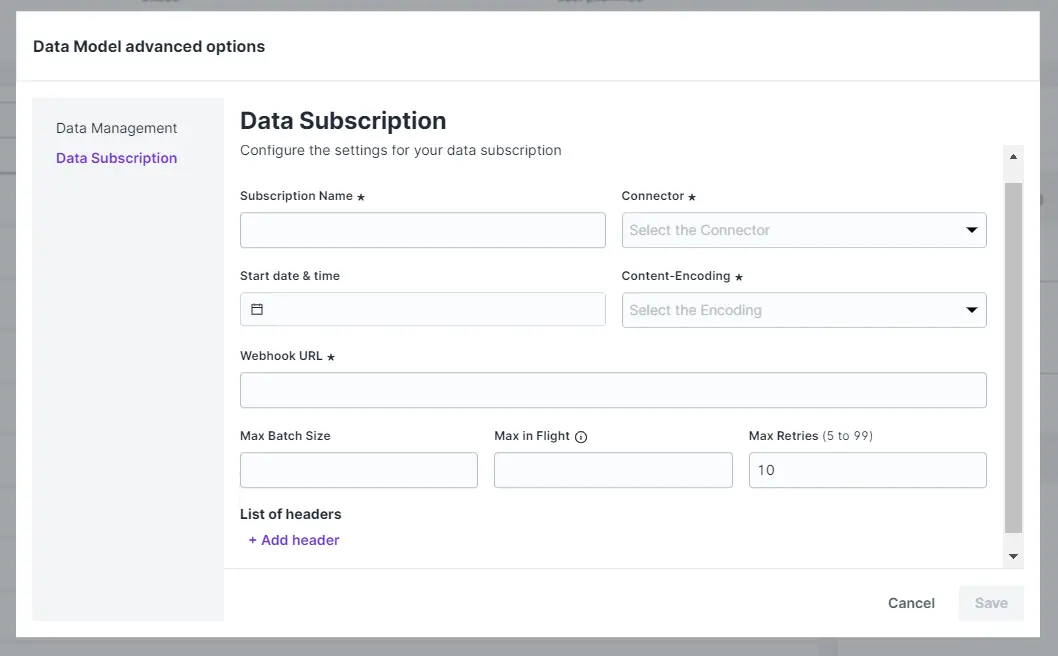
Data Subscription
+ Add subscription: permite adicionar e configurar um serviço de subscrição para sincronizar dados com outras estratégias de armazenamento fora da Carol.

Eliminando todos os registros
A eliminação de todos os registros de um data model pode ser realizada a partir de 2 locais:
- A partir da lista de data models ao passar o mouse sobre um data model específico e clicar no botão com três pontos.

- A partir da página de configurações de um data model específico por meio do botão
Options.

Eliminando o data model
A eliminação de um data model pode ser realizada somente a partir da página de configurações do data model específico por meio do botão Options. Ao eliminar um data model todos os seus registros também serão eliminados da Carol.