SQL Processing +Eficiente
A estratégia de processamento de dados da plataforma Carol permite ativar um recurso chamado de Eficiência do SQL Processing, o qual torna o recurso mais eficiente reduzindo custos quanto ao uso de slots, storage e outros recursos com menor impacto.
A eficiência do SQL Processing permite iniciar o processamento de dados apenas quando novos dados são enviados para a plataforma Carol, ao invés de executar a pipeline continuamente conforme expressão cron definida para cada pipeline.
Com isso, estamos acionando as pipelines de forma inteligente quando deve ter novos dados disponibilizados.
Deve-se prestar atenção em alguns requisitos para essa funcionalidade. O principal requisito é garantir que o arquivo de manifesto das pipelines (pipelines.json) está corretamente configurado. Cada pipeline deve, obrigatoriamente, especificar as staging tables que a pipeline depende. O evento de recebimento de dados para essas staging tables irá acionar a execução da pipeline no próximo agendamento de execução.
Por exemplo: se a pipeline está configurada para rodar uma vez por hora, no minuto zero, e atualmente estamos no minuto 30 e recebemos novos dados, quando chegarmos no minuto zero novamente a pipeline será executada.
Se não receber dados, a task de execução SQL Processing é criado, mas uma mensagem é exibido informando que novos dados não foram recebidos e por conta disto a task não será executada. A task será encerrada antes de iniciar a execução da pipeline SQL.
Para melhorar o acompanhamento criamos a task, na qual terá duração de execução muito curta e não terá o uso de slots.
A configuração da eficiência do SQL Processing possui detalhes especificos para cada estratégia de execução da pipeline: Orquestrator e através da Tenant Unificada com integração de dados através do Smartlink.
Observação.: A integração de dados através do Smartlink atualmente é suportada apenas pelo Protheus na release de Outubro/2023.
Unified SQL Processing (utilizando batchID)
O requisito para a eficiência do SQL Processing através de tenants unificadas e do batchID:
- Tenant Unificada configurada.
- Carol App configurado com Tenant Unificada.
- Manifesto de pipelines configurado, mais detalhes Manifesto de pipelines.
- Para V1, utilize o parâmetro
useBatchNotification. - Para V2, utilize o parâmetro
useBatchSQLEfficiency.
- Para V1, utilize o parâmetro
- Envio de dados através do endpoint
intake, conforme descrito em Enviando dados para a Carol. - Finalização do envio de dados através do endpoint
summary(descrito no processo de envio de dados para a Carol).
Quanto esses itens forem atendidos, a task irá executar a pipeline SQL apenas quando dados tiverem sido enviados contendo um batchId informado no endpoint do intake e o batchId deve ter sido encerrado através do endpoint summary. Caso não tenha sido enviado dados para a plataforma Carol, as tasks serão encerradas informando não ter recebido dados:
SQL Processing baseado no Orquestrador
Tasks iniciadas através do Orchestrador seguem automaticamente os requisitos abaixo:
- Tasks informam o nome do Carol App.
- Tasks informam o nome da pipeline.
- Tasks são iniciadas com o parâmetro
checkExistsDataToProcesscom o valortrue.
Tasks seguindo os parâmetros acima irão passar pela seguinte validação:
- Carol App Name informado deve possuir uma tenant unificada.
- A tenant unificada vinculada ao Carol App deve possuir as pipelines disponíveis na tenant unificada (checkout do manifesto de pipelines).
- A pipeline vinculada à task deve ter recebido dados, ou esta deve ser a primeira execução da pipeline.
Aqui destaco novamente a importância da pipeline possuir a lista correta de staging tables necessárias para ativar a pipeline. Do contrário, a pipeline não irá executar no recebimento dos dados.
Pelo menos uma das staging tables listadas na propriedade sourceEntities da pipeline deve receber dados para que a pipeline seja acionada no próximo agendamento.
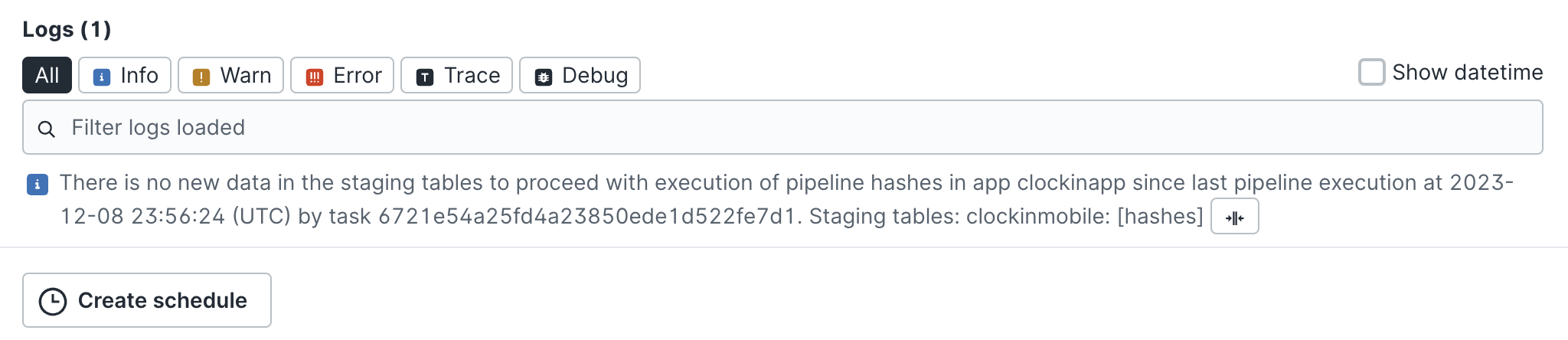
As tasks que não tiveram a pipeline executada recebem uma mensagem como a abaixo, e são encerradas rapidamente, sem executar a pipeline, e reduzindo o custo do processamento de dados:
mdmId para processamento Pipelines
o mdmId é um identificador único, determinístico e exclusivo para criação de pipelines, gerado para cada registro de dado que entra na plataforma,ou seja, sempre será gerado da mesma forma para os mesmos dados.
Função Principal:
- Serve como chave primária global dos dados dentro da Carol.
- Garante que registros idênticos (mesmos valores nos campos de chave primária da tabela, usados para gerar o mdmId) sempre recebam o mesmo identificador, independentemente da origem do dado (API, pipeline, upload, etc.).
- Evitar duplicidade de registros entre dados inseridos pela API na camada RT e os registros processados pelos pipelines SQL.
- Uniformidade no padrão de identificação em toda a plataforma.
- Também é possivel utilizar a tag --metadata-- que irá realizar a criação do mdmId de forma gerenciada pela plataforma, confome explicado na documentação de metadados .
Como é gerado:
Na pipeline é definido quais campos são usados como “chave” do registro. Exemplo de campos que podem fazer parte de chaves: CPF, CNPJ, código do cliente, código do produto, etc. Esses campos são normalizados e é feita uma concatenação de todos os valores, sobre essa concatenação é aplicado um hash MD5, convertido em hexadecimal.
Abaixo está sendo demonstado um tipo de técnica para se obter o resultado final do mdmid, porém, existem outros tipos de técnica que podem ser utilizados.
Estrutura de código::
TO_HEX(MD5(LOWER(CONCAT(
(SELECT r.__mdmTenantId FROM UNNEST(e.o) r WHERE r.__mdmTenantId IS NOT NULL LIMIT 1),
'employee{',
'"employeecode":"', (SELECT r.employeecode FROM UNNEST(e.o) r WHERE r.employeecode IS NOT NULL LIMIT 1), '",',
'"mdmtaxid":"', (SELECT r.mdmtaxid FROM UNNEST(e.o) r where r.mdmtaxid IS NOT NULL LIMIT 1), '"',
"}"
)))) AS __mdmId,