VSCode Plugin
O plugin TOTVS Carol para o Visual Studio Code permite a construção e teste de Pipelines com recursos como code completion, testes dry-run da pipeline e execução da pipeline SQL na Carol.
Instalação
→ Para conhecer os passos de instalação acesse a página oficial do plugin TOTVS Carol.
Após instalado, o plugin pode ser acessado no menu lateral esquerdo do VSCode.
Para gerenciar as Tenants e realizar outras ações, use o atalho (Ctrl + Shift + P) e digite "Carol".
Para fazer login, você deverá informar a Organização, e será redirecionado para o login na Carol. Após o login será possível selecionar as Tenants que serão ativadas, e o plugin estará pronto para uso, permitindo processar e criar novas pipelines, entre outras operações listadas abaixo.
Para melhor uso do plugin do VSCode, os arquivos pipeline deve ser definidos com extensão csql.
Operações
O plugin do VSCode permite as seguintes operaç�ões:

Algumas operações podem ser acionadas diretamente ao abrir arquivos csql, no canto superior direito.
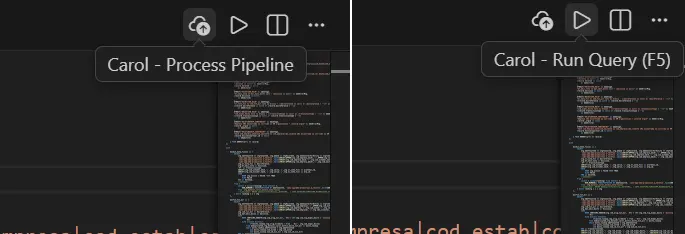
Os comandos do VSCode possuem o seguinte objetivo:
Carol - Login
O plugin solicitará os dados para adicionar uma Tenant dentro do VSCode, permitindo a interação com a Carol através de uma conexão já estabelecida. Internamente, o plugin irá criar o connector token no ambiente informado.
Carol - Tenants
Este comando permite listar todas as Tenants disponíveis no plugin permitindo ativar uma Tenant ou deletar uma Tenant.
Uma vez que a Tenant está ativa, a informação da Tenant ficará disponível no rodapé do VSCode:

Carol: Refresh Staging Tables
Este comando permite atualizar em tela a lista de staging tables da tenant ativa.
Carol: Refresh Data Models
Este comando permite atualizar em tela a lista de data models da tenant ativa.
Carol - Dry Run Query
O comando dry-run submete a query para o dry-run do Bigquery, retornando a quantidade estimada de megabytes que será lido. Este comando é ideal para validar recursos necessários para execução da query.
O resultado é observado no rodapé do VSCode, ao lado do ambiente conectado.
Carol - Run Query
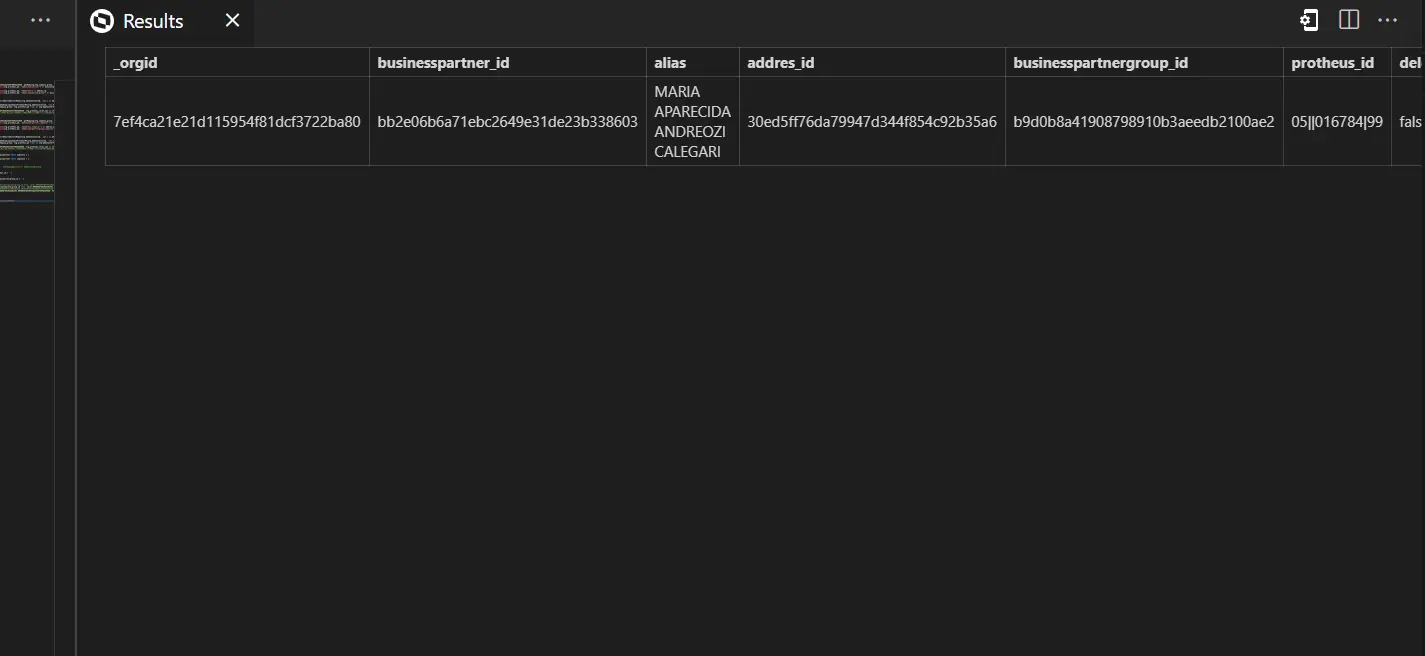
Este comando permite executar uma query para validar o resultado da pipeline. Um atalho para esse comando é a tecla F5, que vai submeter a query ao ambiente conectado (visível no rodapé) e vai mostrar o resultado numa panel nova.
Este comando não valida o schema retornado pela pipeline contra o schema do Data Model.
Carol: Create Pipeline
Este comando permite criar uma pipeline que será posteriormente utilizada por um manifesto ou que poderá ser executada diretamente pelo comando Carol - Process Pipeline.
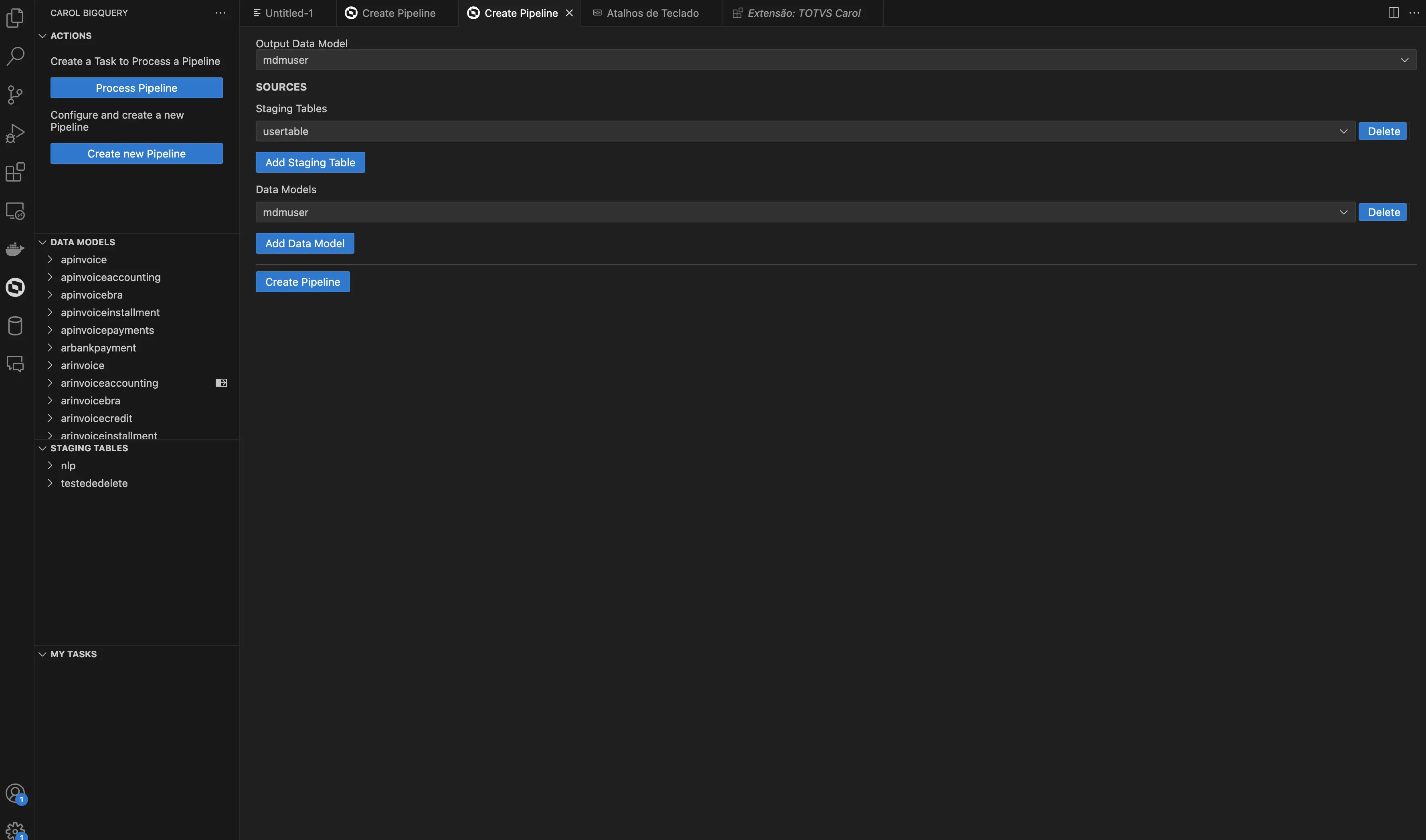
Os parâmetros disponíveis:
Output Data Model:SOURCES: agrupador indicando as origens dos dados a serem processados.Staging Tables: indica quais tabelas com registros brutos serão utilizadas no processamento. As tabelas podem ser adicionadas ou removidas, por meio do botão disponível.Data Models: indica quais tabelas com registros já processados serão reutilizadas no processamento. As tabelas podem ser adicionadas ou removidas, por meio do botão disponível.
Quando o botão Create Pipeline é acionado, será criada a partir dos parâmetros informados, a estrutura base da pipeline facilitando o processo posterior de configuração pelo desenvolvedor.
Carol: Process Pipeline
Este comando permite processar os dados na Carol executando a pipeline diretamente na Carol. O comando permite alterar uma série de parâmetros para determinar aonde o dado processado será armazenado, quando executado esse comando será criado uma task na Carol para acompanhamento.
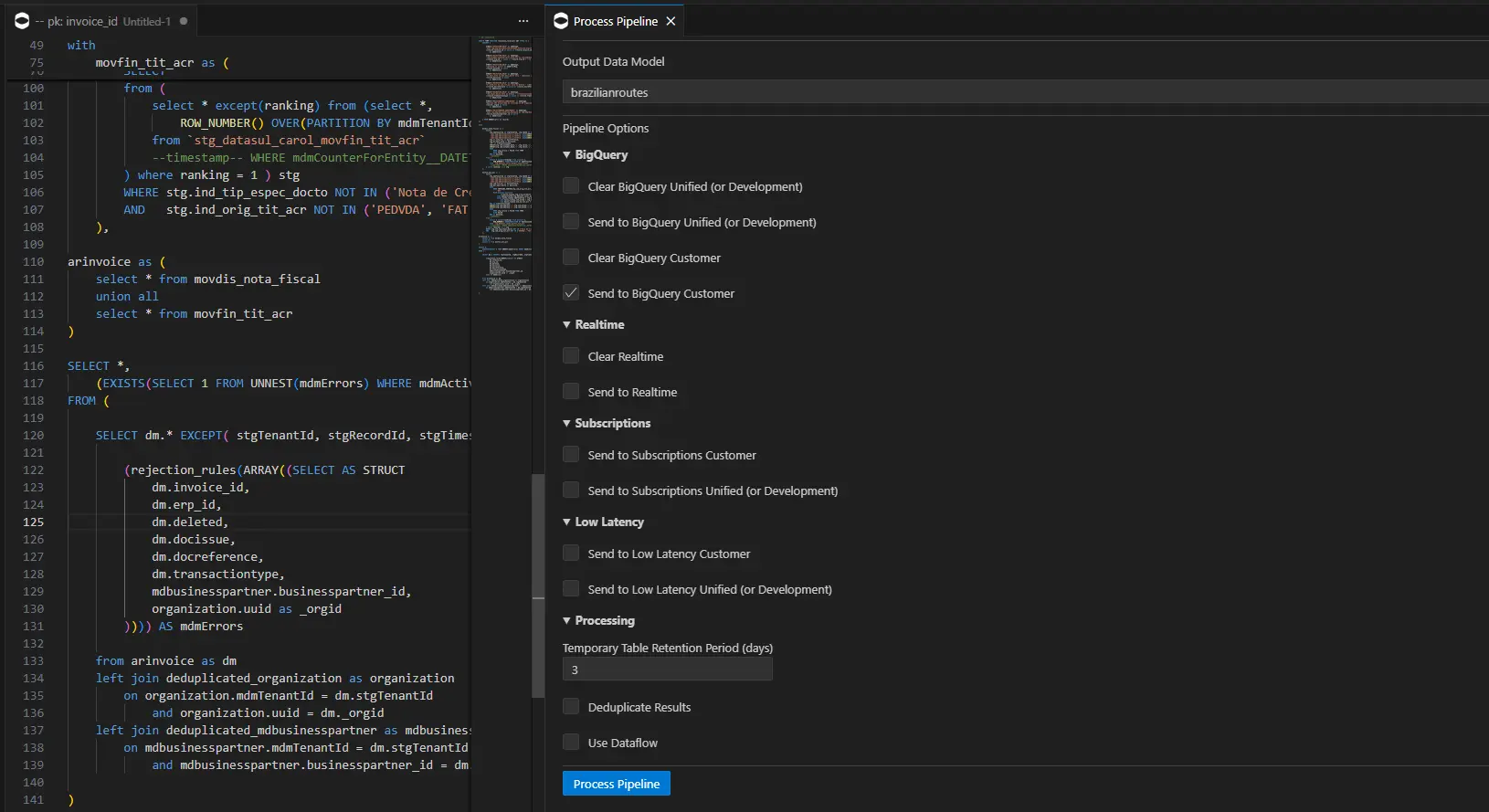
Os parâmetros disponíveis:
Arquivo CSQL: este é o arquivo correspondente pela pipeline.Output Data Model: datamodel que a Carol irá armazenar os dados.BigQuery - Clear BigQuery Unified (or Development): indica para a Carol para limpar o storage Bigquery antes de salvar os novos dados na tenant do tipo Unificada ou de Desenvolvimento.BigQuery - Send to BigQuery Unified (or Development): indica para a Carol salvar os dados processados no storage Big Query na tenant do tipo Unificada ou de Desenvolvimento.BigQuery - Clear BigQuery Customer: indica para a Carol para limpar o storage Bigquery antes de salvar os novos dados na tenant do tipo Customer (apenas quando executada no ambiente Customer).BigQuery - Send to BigQuery Customer: indica para a Carol salvar os dados processados no storage Big Query na tenant do tipo Customer (apenas quando executada no ambiente Customer).Realtime - Clear Realtime: indica para a Carol limpar a camada Realtime antes de inserir os novos dados.Realtime - Send to Realtime: indica para a Carol salvar os dados na camada Realtime (RT).Subscriptions - Send to Subscriptions Customer: indica para a Carol enviar os dados processados para as subscriptions do data model output cadastradas na tenant do tipo Customer. Caso o registro tenha o atributo mdmDeleted como falso, será enviado a mensagem de eliminação no Data Subscription.Subscriptions - Send to Subscriptions Unified (or Development): indica para a Carol enviar os dados processados para as subscriptions do data model output cadastradas na tenant do tipo Unificada ou Desenvolvimento.Low Latency - Send to Low Latency Customer: indica para a Carol enviar os dados para a camada baixa latência da plataforma IDEIA na tenant do tipo Customer (apenas quando executada no ambiente Customer).Low Latency - Send to Low Latency Unified (or Development): indica para a Carol enviar os dados para a camada baixa latência da plataforma IDEIA na tenant do tipo Unificada ou de Desenvolvimento.Processing - Temporary Table Retantion Period (days): Tempo em dias de retenção dos dados na tabela temporária de processamento no BigQuery (tabelas temporárias)Processing - Deduplicate Results: indica para a Carol realizar deduplicação de registros resultantes da pipeline de acordo com o Id do registro gerado no processamento.Processing - Use Dataflow: indica para a Carol utilizar o Dataflow para processar os dados. Este valor quando enviado false é gerenciado automaticamente pela Carol dependendo do tamanho dos dados processados na pipeline.
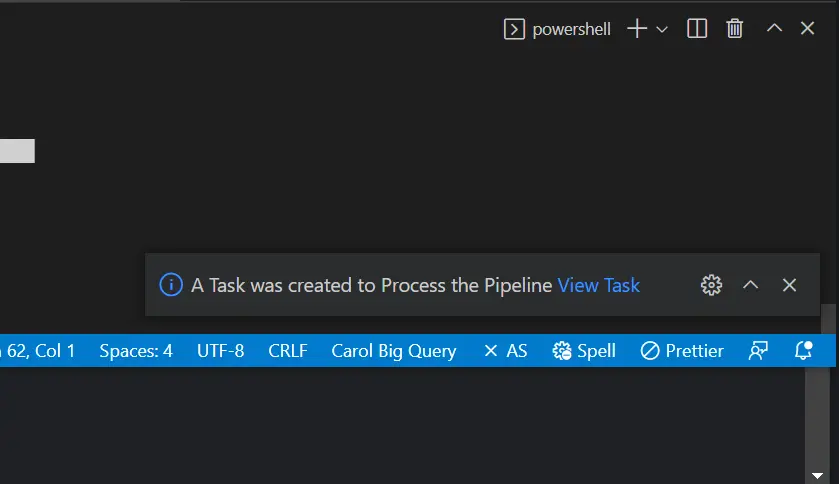
Quando o botão Process Pipeline é acionado, a mensagem de confirmação aparecerá juntamente com o link para acessar a task criada para processar os dados:
Carol: View Manifest
Este comando permite criar um manifesto a partir de uma pipeline existente. Para isto, o desenvolvedor precisa clicar no arquivo .csql da pipeline com o botão direito do mouse e selecionar a operação Carol - View Manifest.
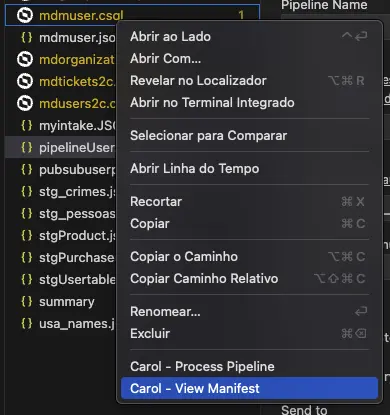
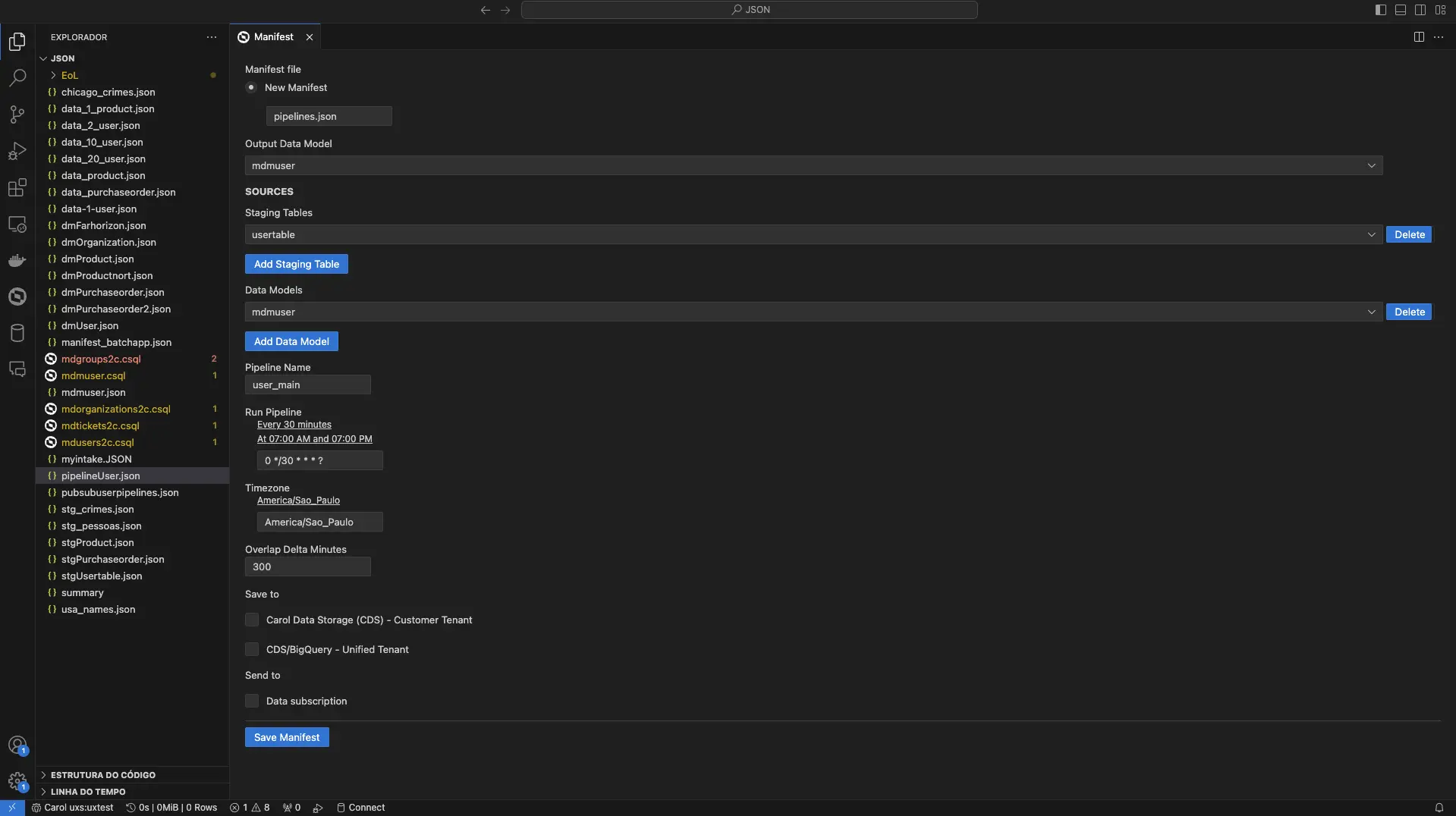
Os parâmetros disponíveis:
New Manifest: indica a criação de um novo manifesto e traz por convenção o nome padronizado ao arquivo como pipelines.json, porém editável pelo desenvolvedor.Output Data Model: indica o data model de destino do processamento dos dados.SOURCES: agrupador indicando as origens dos dados a serem processados.Staging Tables: indica quais tabelas com registros brutos serão utilizadas no processamento. As tabelas podem ser adicionadas ou removidas, por meio do botão disponível.Data Models: indica quais tabelas com registros já processados serão reutilizadas no processamento. As tabelas podem ser adicionadas ou removidas, por meio do botão disponível.Pipeline Name: indica o nome a ser atribuído a pipeline.Run Pipeline: indica os períodos de execução programada da pipeline por meio da expressão cron a ser configurada pelo desenvolvedor.Timezone: indica o fuso horário da região do calendário de execução. Por padrão o timezone definido é America/Sao_Paulo.Overlap Delta Minutes: indica a quantidade de minutos que será executado em sobreposição em relação à última execução desta pipeline. Caso seja a primeira execução, a pipeline será executada sem restrição de dados pela janela de recebimento dos dados (equivalente a um processamento inicial).Save to: agrupador indicando onde será salvo o resultado da pipeline.Carol Data Storage (CDS) - Customer Tenant: indica que o resultado da pipeline deve ser salvo no storage type CDS da tenant cliente.CDS / BigQuery - Unified Tenant: indica que o resultado da pipeline deve ser salvo em ambos os storage types (CDS e BigQuery) da tenant unificada (ambiente centralizador dos dados, responsável por processar os dados em escala).Send to: agrupador indicando onde será enviado o resultado da pipeline.Data Subscription: indica que ao término da execução da pipeline, os resultados devem ser enviados via data subscription (caso o data model tenha essa configuração). O envio do data subscription ocorre pelas tenants clientes. Registros incluídos e registros removidos são enviados via Data Subscription.
Quando o botão Save Manifest é acionado, será criada a partir dos parâmetros informados, a estrutura base do manifesto facilitando o processo posterior de configuração pelo desenvolvedor.
Carol - Upload Data
O comando upload-data permite a subida de arquivos apenas no formato .json para a Carol.
Estes arquivos podem submeter dados de duas formas:
- Registros em staging tables já existentes.
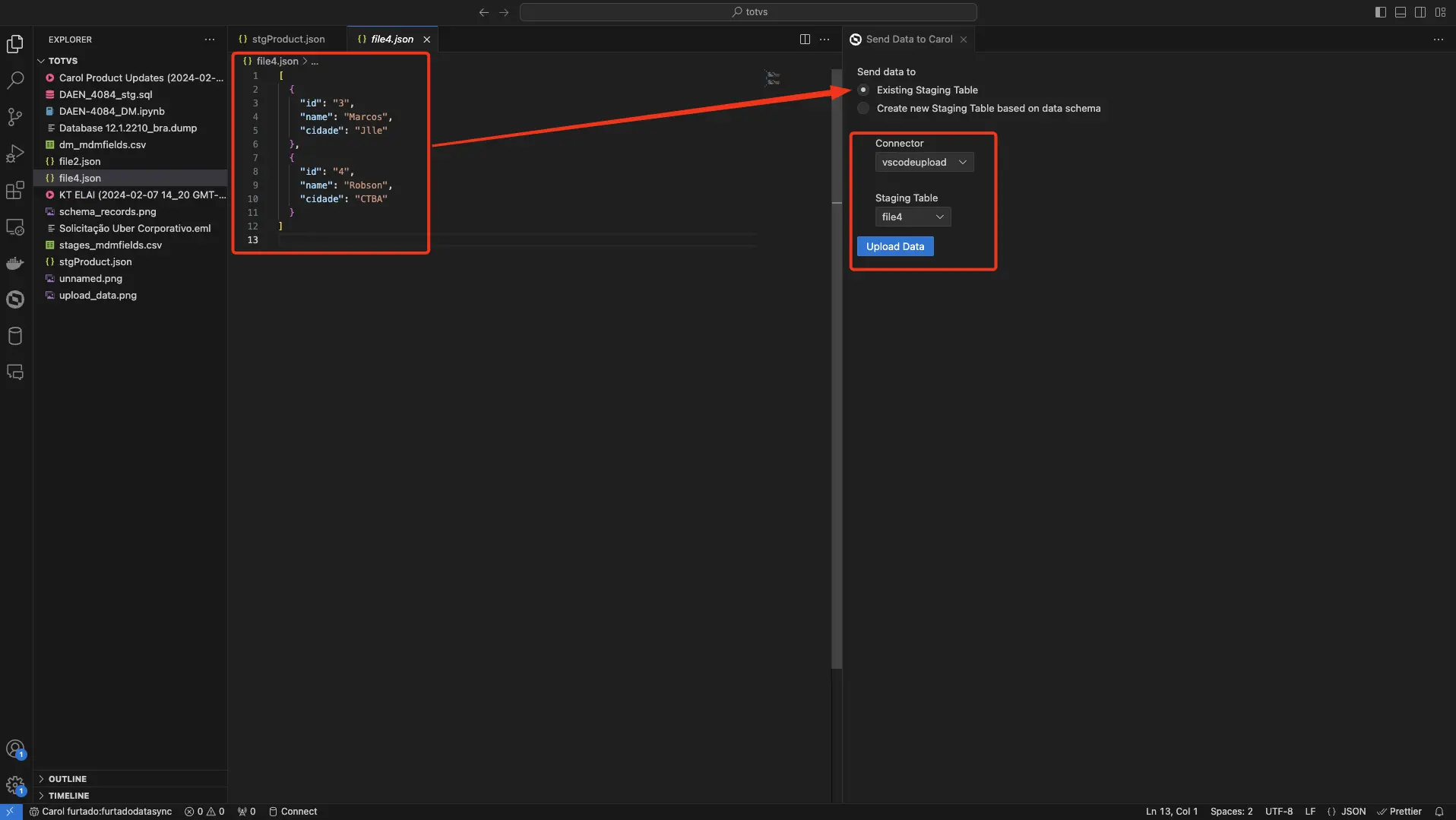
- Esquema de dados para a criação de novas staging tables.
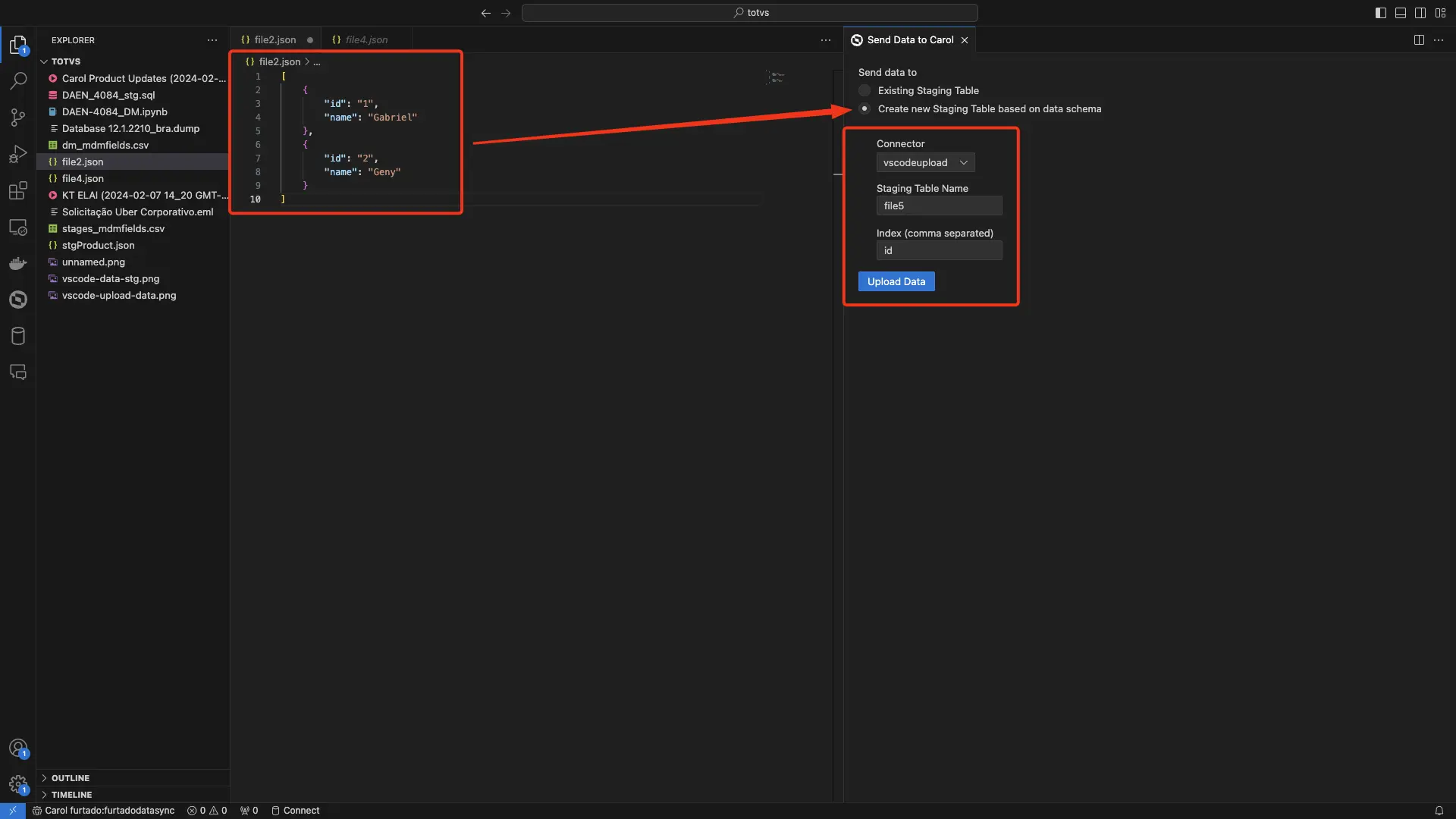
Estes arquivos podem submeter dados de duas formas:
- Registros em staging tables já existentes.
- Esquema de dados para a criação de novas staging tables.
Agente de Otimização de consultas SQL
No menu de processamento de pipelines e execução de queries, está disponível a funcionalidade SQL Optimization by Carol Agent, capaz de otimizar consultas SQL nos bancos de dados:
- BigQuery. (padrão)
- PostgreSQL.
- Microsoft SQL Server.
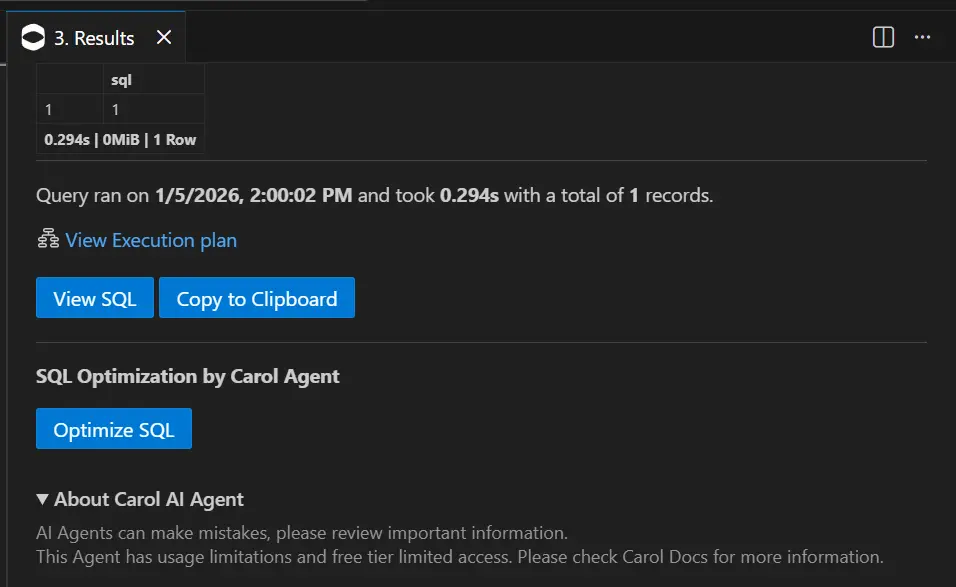
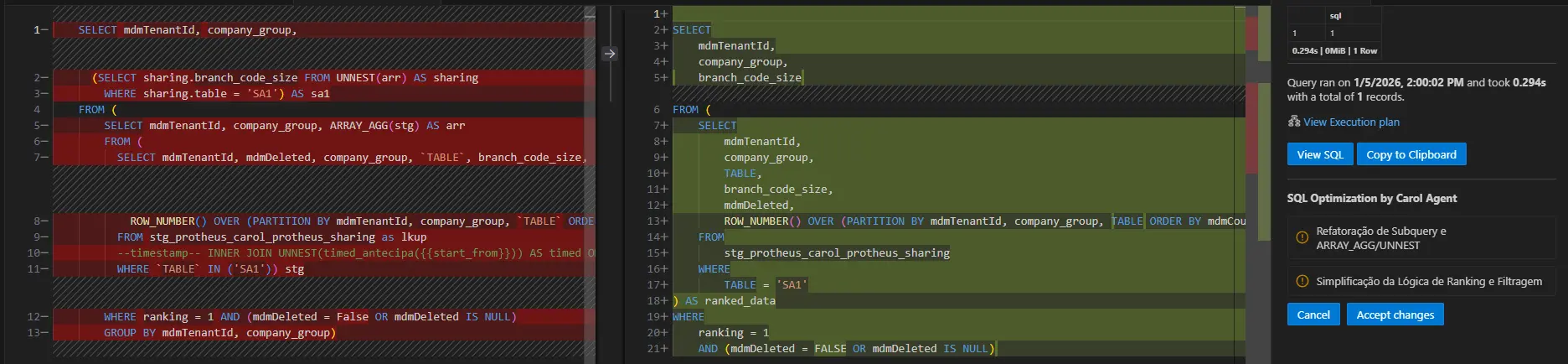
O Agente de otimização de consultas SQL pode sugerir otimizações nas consultas e exibe as diferenças da forma abaixo após ser iniciado.
Limites de uso e configurações adicionais podem ser encontradas em sua documentação específica.