Otimizações em consultas
É crucial garantir o desempenho eficiente das consultas de pipelines em SQL, para auxiliar nesta tarefa que pode ser extensa, estaremos utilizando o plano de execução do BigQuery.
→ Como o Bigquery armazena os dados
→ Como o Bigquery processa os dados
→ Compreendendo o plano de execução
→ Analisando planos de execução
→ Otimizações de performance em dashboards
Como o Bigquery armazena os dados
Columnar storage
Bancos de dados relacionais tradicionais, como Postgres e MySQL, armazenam dados linha por linha em armazenamento orientado a registros. Isso os torna ótimos para atualizações transacionais e casos de uso OLTP (Online Transaction Processing), porque só é necessário recuperar uma única linha para ler ou gravar dados. No entanto, se você quiser realizar uma agregação como a soma de uma coluna inteira, precisará ler a tabela inteira na memória.

O BigQuery usa armazenamento em colunas, onde cada coluna é armazenada em um bloco de arquivo separado. Isso torna o BigQuery uma solução ideal para casos de uso OLAP (Online Analytical Processing). Quando você deseja realizar agregações, você só precisa ler a coluna que está agregando.
Partitioning
Uma tabela particionada é uma tabela fisicamente dividida em segmentos, chamados partições. O BigQuery utiliza o particionamento para diminuir a quantidade de dados que os slots lêem do disco. As consultas que contêm filtros na coluna de particionamento podem reduzir o total de dados armazenados que são lidos, o que pode gerar melhor desempenho e redução do custo de processamento. Quando novos dados são gravados em uma tabela particionada, eles são automaticamente separados na partição apropriada.

O BigQuery oferece suporte às seguintes formas de criar tabelas particionadas:
- Tabelas particionadas por tempo de ingestão: partições diárias que refletem a hora em que os dados foram ingeridos no BigQuery.
- Tabelas particionadas por coluna de unidade de tempo: o BigQuery atribui dados para a partição apropriada com base no valor da data na coluna de particionamento.
- Tabelas particionadas de intervalo INTEGER: Você pode agrupar os valores inteiros para criar partições do tamanho desejado, como ter todos os clientes com IDs de 0 a 100 na mesma partição.
Clustering
Quando uma tabela é agrupada em cluster no BigQuery, os dados são ordenados automaticamente com base no conteúdo de uma ou mais colunas (até quatro, conforme definição da tabela). Normalmente, colunas de alta cardinalidade e não temporais são preferidas para agrupamento, em oposição ao particionamento, que é melhor para campos com cardinalidade mais baixa.
A ordem das colunas agrupadas determina a ordem de classificação dos dados. Quando novos dados são adicionados a uma tabela, o BigQuery realiza o novo clustering automático e sem custos em segundo plano.

O clustering pode melhorar o desempenho das consultas:
- Cláusulas
WHEREcom coluna clusterizada: o BigQuery usa os blocos clusterizados para eliminar leitura de dados desnecessários. A ordem dos filtros na cláusula `WHERE`` é importante, devem ser usados filtros que aproveitem o cluster primeiro. - Agregações com base em valores de coluna clusterizada: o desempenho é melhorado porque os blocos clusterizados ordenam as linhas com valores idênticos.
- Cláusulas
JOINcom coluna clusterizada: menos dados são lidos durante a junção de duas tabelas.
Partitioning + Clustering
Não há limitação na escolha da utilização de Clustering ou Partitioning, é possível a definição de ambos em uma única tabela.
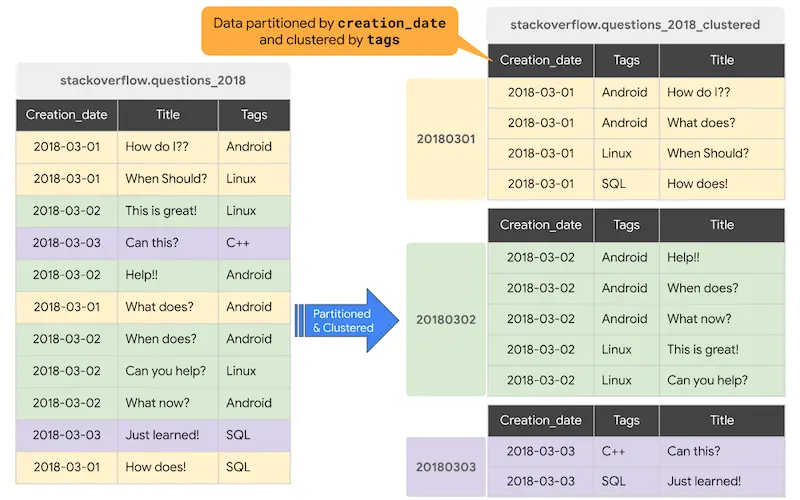
Como o Bigquery processa os dados
Arquitetura
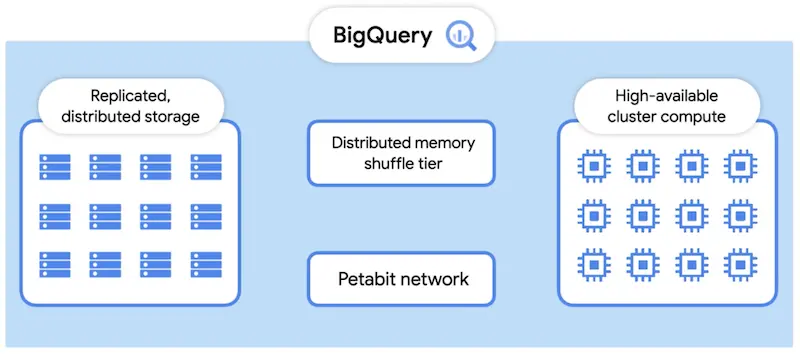
Como é possível ver no diagrama abaixo, a arquitetura de processamento do BigQuery é composta por um conjunto de workers. Cada um desses workers executa parte de uma tarefa de forma independente e paralela. O BigQuery usa uma área de armazenamento de memória distribuída (memory shuffle) para armazenar dados intermediários produzidos por workers em vários estágios de execução. Isso torna possível executar operações distribuídas em um pipeline.
Ciclo de Vida
Utilizando a arquitetura de processamento descrita anteriormente, o BigQuery realiza a execução de queries, que passam por diferentes estágios de validação e processamento.
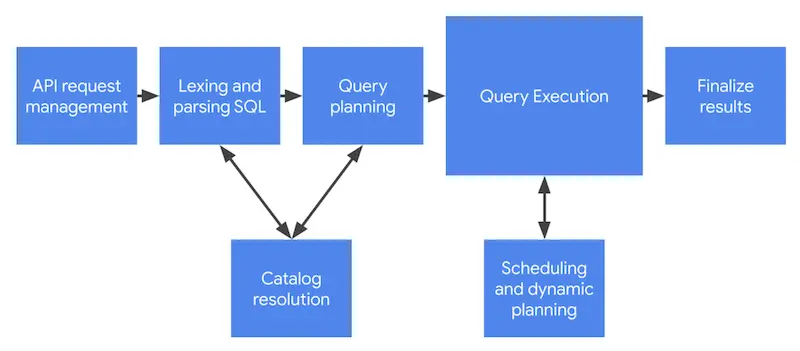
- API request management: algumas das coisas que devem ser feitas são autenticar e autorizar a solicitação.
- Lexing and parsing: análise léxica e sintática da linguagem SQL.
- Catalog resolution: validação dos identificadores de projeto, dataset, tabelas, views e colunas presentes na query.
- Query planning: definição do plano de execução mais rápido e eficiente para a quey, como um conjunto de tasks de execução distribuída.
- Query execution: processo de avançar através dos estágios de execução definidos pelo plano até a conclusão.
- Scheduling and dynamic planning: além dos workers envolvidos na execução do próprio plano, workers adicionais monitoram e direcionam o progresso geral da execução, definindo questões como o enfileiramento e provisionamento de novos workers.
- Finalize results: a conclusão do processamento produz artefatos de saída na forma de resultados, que neste estágio são enviados à camada de armazenamento.
Compreendendo o plano de execução
Input e Output
Referem-se aos dados lidos (input) e escritos (output) durante cada estágio do processamento de consultas.

-
Input: quantidade de registros que são lidos a partir do armazenamento distribuído ou memory shuffle, e necessários para processamento daquele estágio.
-
Output: após o processamento daquele estágio, os registros resultantes resultados são escritos para o armazenamento em disco ou memory shuffle.
A quantidade de dados lidos interfere na quantidade de slots necessária para consumo destes dados naquele estágio do processamento, deste modo, a utilização de Partitioning e Clustering auxilia na diminuição da quantidade de dados lidos.
Fases e duração
É possível ver o tempo médio e máximo que cada worker (slot) gastou esperando, lendo, processando e escrevendo em cada etapa do processamento:

-
Waiting: aguardando que slots fiquem disponíveis, ou que um estágio anterior comece a escrever resultados que possam ser consumidos do memory shuffle. Muito tempo gasto na fase de espera, pode indicar uma retenção de slots devido à concorrência com outros processamentos.
-
Read: o slot está lendo dados do armazenamento distribuído ou do shuffle. Muito tempo gasto nesta fase, indica que pode haver uma oportunidade de limitar a quantidade de dados consumidos pela consulta.
-
Compute: onde ocorre o processamento, tal como executando funções ou expressões SQL. Uma consulta bem ajustada, normalmente passa a maior parte do tempo na fase de computação. Muito tempo gasto nesta fase, pode indicar a necessidade de reavaliação de manipulações mais custosas nos dados.
-
Write: quando os dados são gravados, seja no próximo estágio, shuffle ou resultado final retornado ao usuário. Muito tempo gasto aqui, indica que pode haver uma oportunidade de limitar os resultados deste estágio, através de consolidações ou filtros por exemplo.
Bytes Shuffled
Representa a quantidade de dados movimentada para o trabalhos dos workers durante os estágios do processamento.
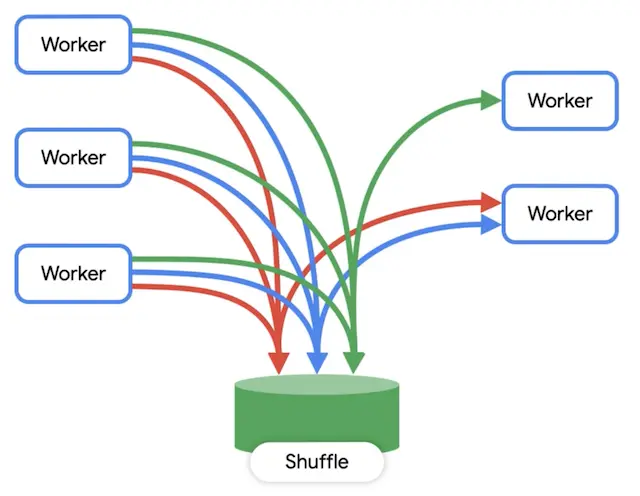
Como dados presentes no shuffle são distribuídos entre workers de um estágio, operações como JOIN e GROUP BY realizam processamentos parciais antes da agregação final.
Apesar de ser uma área em memória, em algumas circunstâncias o worker pode ser forçado a utilizar o disco, por exemplo quando não houver simetria na distribuição dos dados entre os workers.
Consumo de Slots
-
Um slot representa uma unidade computacional de processamento.
-
Quantidade de slots necessária é calculada automaticamente para cada estágio do plano de execução.
-
A Carol utiliza o modelo de reserva compartilhada por todos os projetos e seus processamentos.
-
A disponibilidade de slots livres afeta o tempo de execução das queries.
-
A quantidade de dados lidos em cada estágio do plano de execução define a quantidade de slots necessária para esta operação de leitura.
Otimizações em SQL
Em tabelas particionadas, o atributo da partição deve ser a primeira condicional informada na query. Além disso, a condição no atributo da partição deve conter apenas constantes. Por exemplo, o cenário abaixo NÃO efetua o filtro de partições não referênciadas:
SELECT * FROM A WHERE A_date >= (SELECT B_date FROM B LIMIT 1)
Enquanto isso, a query acima trata corretamente a partição e irá ler menos dados pelo fato de utilizar partições corretamente:
DECLARE dateB TIMESTAMP;
SET dateB = (SELECT B_date FROM B LIMIT 1);
SELECT * FROM A WHERE A_date >= dateB;
Otimizações de performance em dashboards
Estratégia de consumo de slot para Dashboards
Esta estratégia foi desenvolvida para otimizar o uso de slots no Google BigQuery, equilibrando custos e desempenho. Nesse modelo, os slots possuem um contrato de longo período com a Google o que torna o custo hora do slot mais barato, e esses slots são compartilhado em diversos projetos na plataforma Carol. Ela divide o ambiente de processamento de dados em dois tipos de configuração:
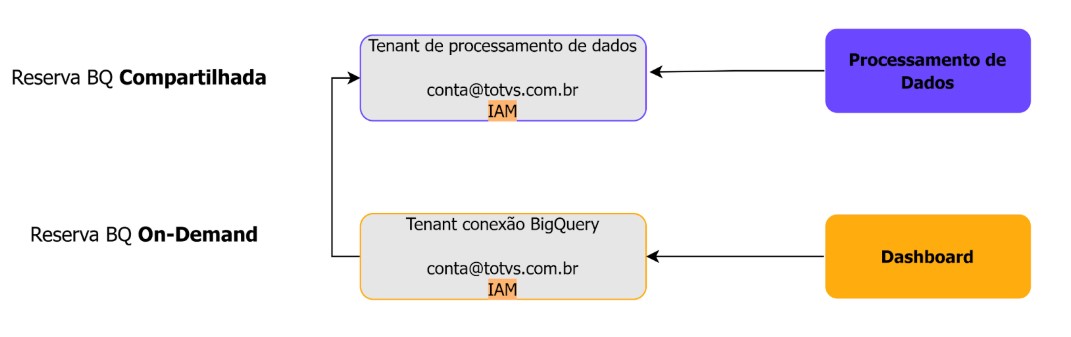
1- Tenant com Reserva Compartilhada de Slots
2- Tenant com Consumo On-Demand de Slots
Slot no BigQuery é a unidade de processamento responsável por executar e transformar os dados. O consumo de slots determina a velocidade do processamento.
Recomendações por Tipo de Ambiente
Reserva Compartilhada: Para Processamento de Dados
Nesse modelo, os slots de processamento são reservados e compartilhados entre diferentes projetos. Embora possam haver concorrências que tornem o processamento um pouco mais lento em momentos de alta demanda, esse modelo oferece um bom equilíbrio entre controle de custos e desempenho. É ideal para tarefas regulares e intensivas, como o processamento de pipelines de dados.
Ideal Para: Pipelines que processam grandes volumes de dados ou processamento de dados regular (a cada 20 minutos, todos os dias, etc). Transformações complexas que exigem alto desempenho computacional. Casos onde o custo precisa ser controlado e dimensionado antecipadamente.
On-Demand: Para Dashboards
No modelo on-demand, os slots não possuem contrato prévio, ao contrário, a alocação ocorre conforme demanda das queries. O BigQuery aloca automaticamente os recursos necessários para cada consulta, cobrando com base no volume de dados processados. Essa flexibilidade é perfeita para projetos que precisam exibir informações em dashboards. Dashboards como os do Looker Studio têm consumo imprevisível e frequentemente menor em termos de processamento contínuo. O modelo on-demand oferece flexibilidade ao cobrar apenas pelo volume de dados processados, além de garantir tempo de espera reduzido para consultas, melhorando a experiência de usuários que necessitam de respostas rápidas.
Ideal Para: Dashboards interativos Casos onde a frequência de uso é variável, e normalmente o nível de consumo é baixo, e a performance das queries para obtenção dos dados é crucial.
Vantagens da Estratégia
-
Eficiência no Uso de Recursos: Separar o processamento de pipelines e exibição de dashboards otimiza o consumo de slots.
-
Flexibilidade e Controle de Custos: Ambientes on-demand para dashboards ajustam custos ao uso real, enquanto reservas compartilhadas garantem previsibilidade no processamento.
-
Performance Acelerada para Dashboards: O modelo on-demand reduz significativamente o tempo de espera das consultas, aprimorando a experiência do usuário final.
Case: Projeto de Telemetria
Cenário:
Processa cerca de 2 TB de dados por dia em pipelines e exige dashboards de alta performance para exibir informações complexas.
Solução:
Pipelines: Executados em reserva compartilhada, garantindo custo controlado e capacidade para processar grandes volumes.
Dashboards (Looker Studio Pro): Configurados em reserva on-demand, proporcionando respostas rápidas mesmo com consultas intensivas.
Destaque: O dashboard utiliza a conta on-demand para consultas e acessa dados armazenados na conta compartilhada, sem duplicação de dados. Apenas o criador do dashboard precisou permissão em ambos os ambientes da Plataforma.
Case: TOTVS Analytics com GoodData
Cenário:
O projeto TOTVS Analytics utiliza a plataforma GoodData para oferecer dashboards de soluções como Backoffice e RH. Cada solução possui reservas de BigQuery compartilhada e on-demand.
Solução:
Reserva Compartilhada: Centraliza o provisionamento de ambientes dos clientes e o processamento de pipelines com regras de negócio.
Reserva On-Demand: Exclusiva para consultas da plataforma GoodData, garantindo alta performance nos dashboards.
Integração: Foi realizado shared data dos data models para o ambiente on-demand, eliminando duplicações e garantindo atualização sincronizada.