Batch Load Ingestion
É o método para mover arquivos de storage para a camada BigQuery da Carol de forma rápida e de baixo custo. Comporta grandes volumes de dados em pacotes, garantindo alta performance e eficiência na integração estruturada.
1. Habilitação da funcionalidade
Para iniciar qualquer operação de carga em lote, a funcionalidade deve ser liberada na estrutura organizacional:
- Na página da organização, clique em “Organization Admin” -> "Settings". No final da página, é necessário habilitar a flag de batch ingestion

Assim que a habilitação for feita, a aba External Ingestion irá surgir na interface de Organization Admin. É nessa aba que as configurações de batch ingestion são feitas.
2. Configuração External Ingestion Organization
Nota: A configuração via Organization foi desenvolvida e homologada para o modelo Smartlink de organização de buckets, pastas, arquivos e metadados. Implementações com estruturas distintas podem exigir adaptações. Para mais detalhes, entre em contato com o time técnico.
Esse modelo deve ser utilizado para conexão externa (bucket de outro projeto) quando, no mesmo projeto, temos dados de várias Tenants separados por buckets. Dentro de cada bucket, deve existir a configuração do metadado no arquivo determinando sua Staging Table de destino. A criação da conexão é feita em “Tenant Admin” -> “External Ingestion” -> “+Add configuration”:

Nesse cenário, o preenchimento correto das configurações da conexão é fundamental para envio correto dos dados a cada tenant e staging de destino.
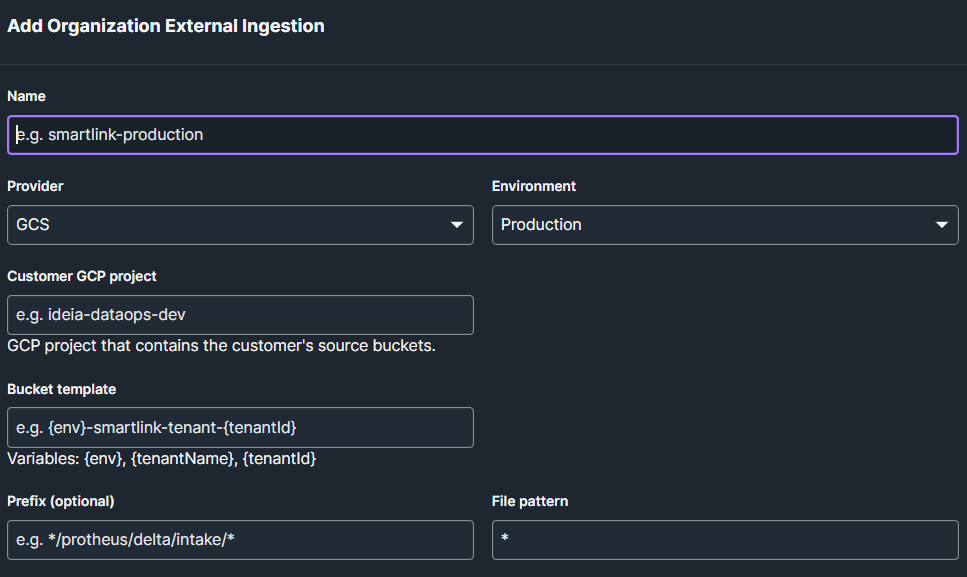
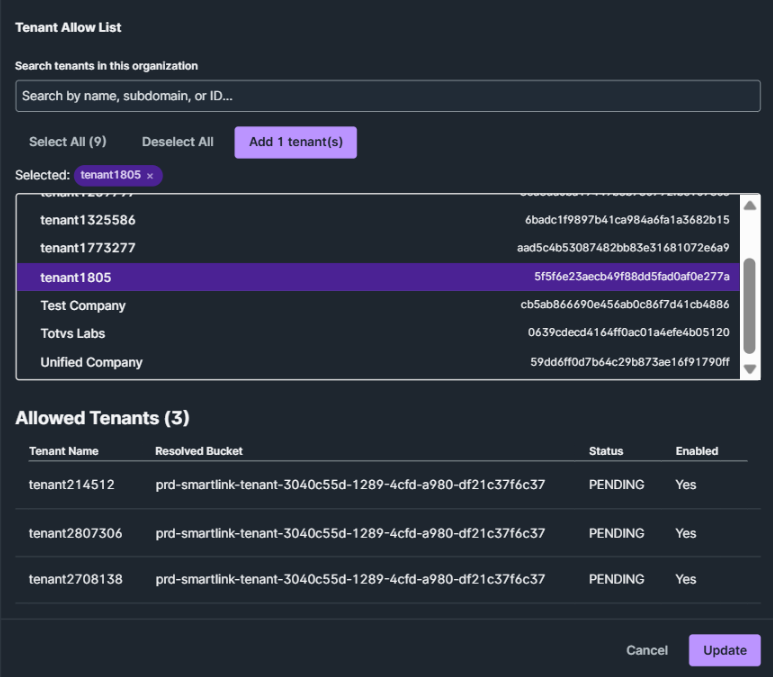
O campo “Environment” pode entrar como variável no nome do bucket caso isso seja determinante para distribuição dos dados nas tenants. A variável {tenantId} também pode fazer parte desse conjunto e dessa forma através do nome do bucket a conexão vai direcionar os dados para tenant correta. Após salvar a conexão, você consegue adicionar quais tenants estão envolvidos nesse processo selecionando a(s) tenant(s) em questão e clicando em Add x tenant(s). Assim você consegue verificar se a composição do nome do bucket ficou correta:
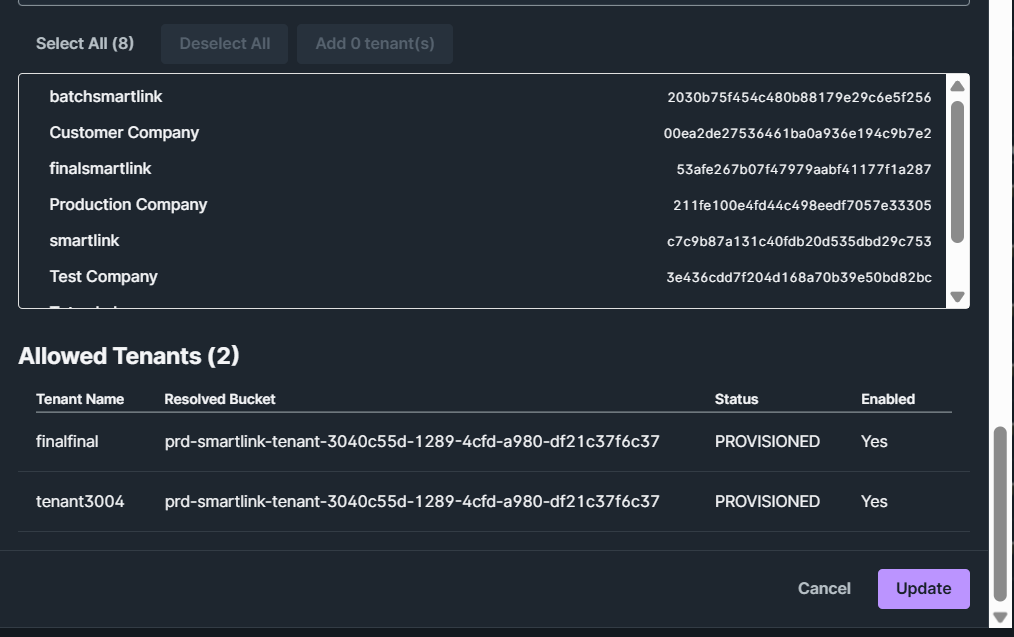
É dessa forma que é definido qual tenant receberá os dados de qual bucket. A configuração de connector e staging table é feita a partir dos metadados dos arquivos do bucket. Basta fazer as referências necessárias no preenchimento da configuração:
Assim, a configuração de Org terá:
- Mapeamento de bucket name para direcionamento de dados em diferentes tenants
- Mapeamento de connector e staging para direcionar, dentro de cada tenant, ao connector e staging corretos.
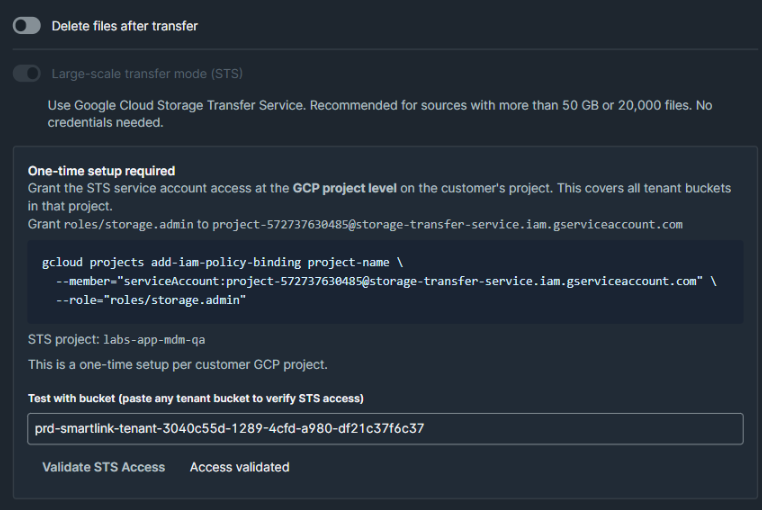
Ponto de atenção: No caso de configuração via Organization, o acesso liberado via STS precisa ser no projeto GCP de origem. Como serão coletados dados de vários buckets (de acordo com {env} e {tenantId}), não é possível conceder o acesso apenas a um bucket. A etapa que gera o comando a ser executado já contempla esse cenário abrangente:
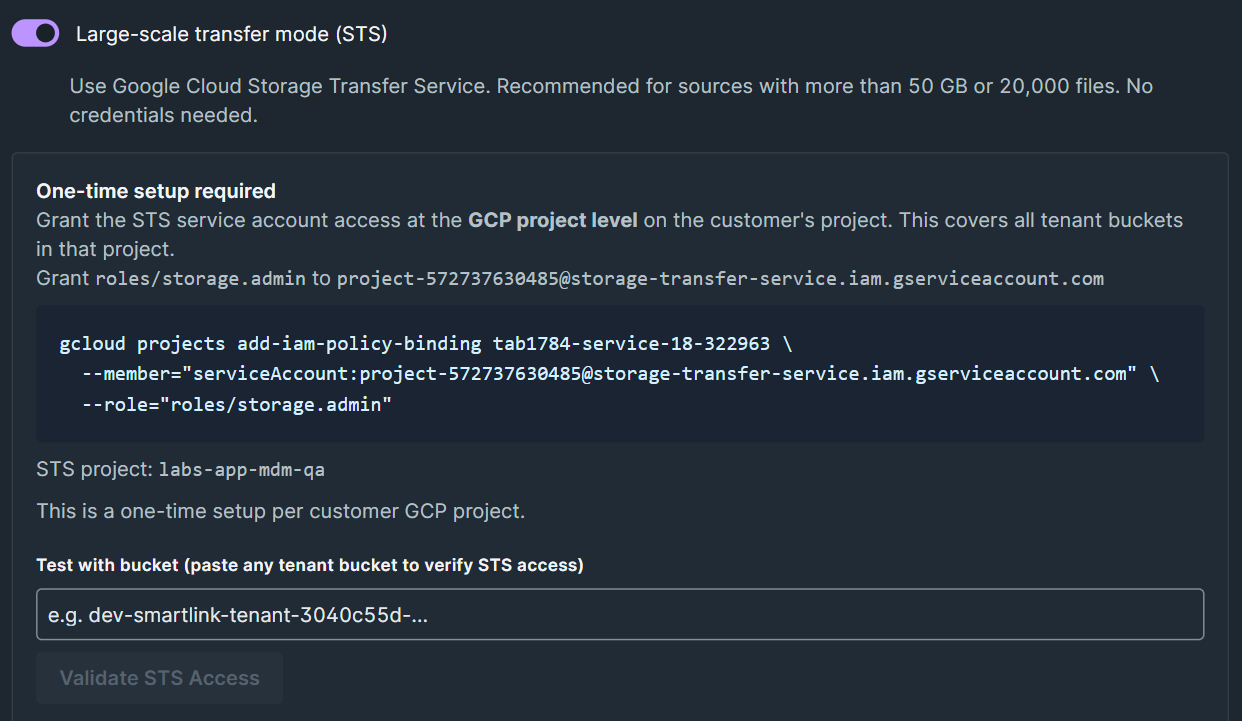
Após o cliente executar o comando, você consegue testar a conexão com um path de bucket como exemplo:

Ao executar o processamento da conexão, uma task na Organization é criada e nela são referenciadas as tasks “filhas”, em cada tenant que foi selecionada.
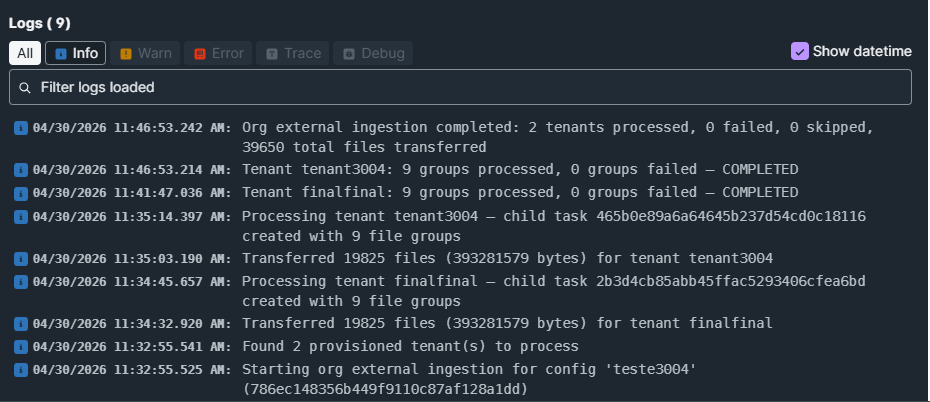
Assim é possível verificar diretamente em cada tenant a task de processamento completas e logs.
3. Estrutura de diretórios e landing zones
A organização dos arquivos no bucket segue uma lógica de separação por recebimento de dados e processamento. Assim que uma transfer é feita em uma tenant, o sistema cria no bucket do Google Cloud Platform (GCP) da tenant a estrutura de pastas raiz para carregamento dos dados. Basta abrir a interface GCP da tenant em questão no ícone abaixo e buscar por "Buckets" ou "Cloud Storage":
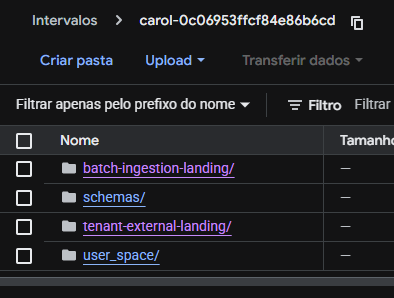
Na primeira etapa, de transferência dos dados ao bucket da tenant, os arquivos ficam na pasta tenant-external-landing/ e seguem exatamente a estrutura do bucket origem. Desse bucket os arquivos são processados e enviados para Staging Table de destino.
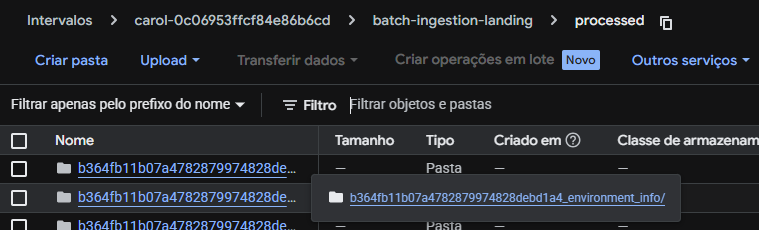
Os dados já processados ficam na pasta batch-ingestion-landing/, dentro da pasta "processed", com a seguinte estrutura: connectorid_stagingname armazenando todos os dados que foram processados para cada tenant. Caso algum arquivo não tenha sido processado por algum erro, ele ficará dentro de batch-ingestion-landing/failed.
4. Monitoramento e logs
O controle é feito através da área Activity Management na Carol.
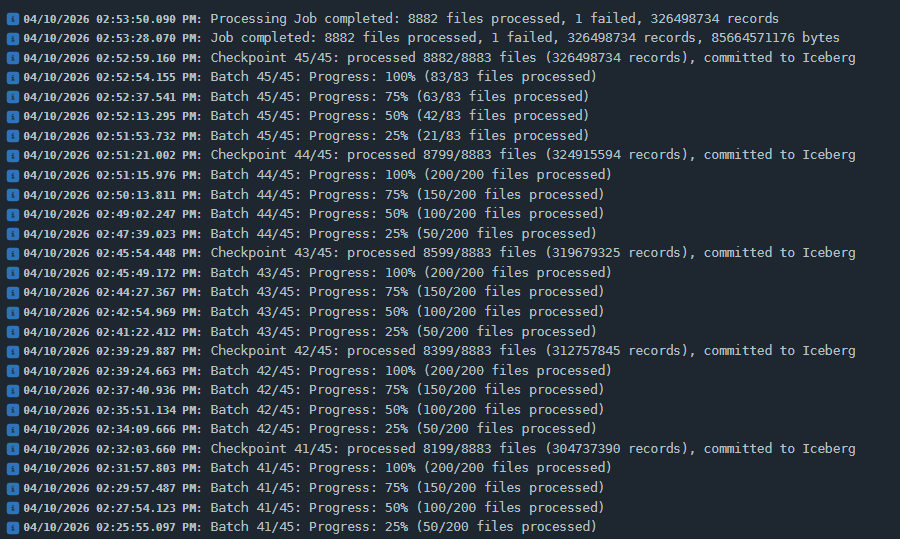
- Detalhamento de logs: É possível acompanhar em qual batch (pacote) a tarefa se encontra, uma vez que o sistema divide grandes volumes de dados em pacotes menores.
- Métricas de progresso: Os logs exibem a quantidade de arquivos processados e a porcentagem de conclusão de cada pacote.
- Controle de duplicidade: Se a tarefa for iniciada (por agendamento ou manualmente) e o sistema detectar que não existem arquivos novos no bucket desde a última transferência, a task é registada, mas o processamento não é executado para evitar duplicidade de dados.
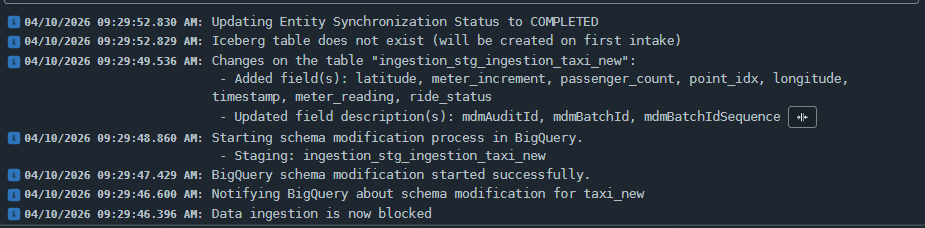
- Task de mudança de esquema: Através dos logs, é possível monitorar a tarefa específica do notify schema change (que acontece quando a execução do batch é feita em uma staging com schema flexível) que roda simultaneamente à execução do batch para validar e detalhar quais novos campos foram adicionados à tabela.
5. Configuração padrão modelo Smartlink
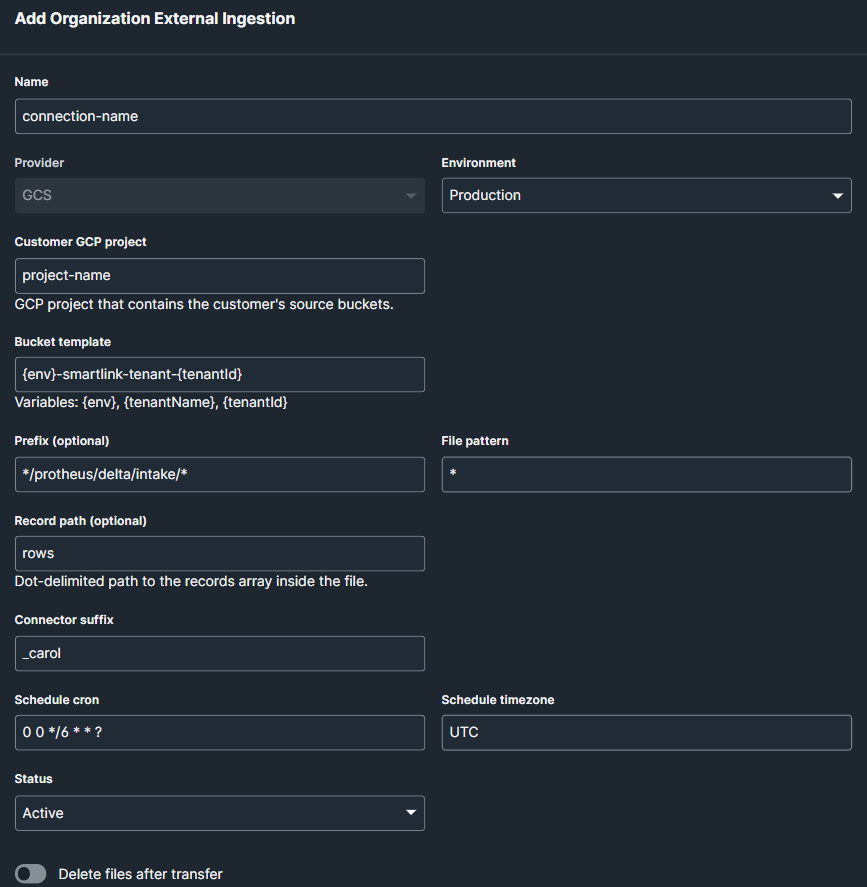
5.1 Configurações gerais da conexão
| Campo | Descrição |
|---|---|
| Name | Nome da conexão |
| Provider | GCS |
| Environment | Selecionar entre ambiente "Development" ou "Production" |
| Customer GCP project | Nome do projeto GCP que contém os buckets origem |
| Bucket template | {env}-smartlink-tenant-{tenantId} |
| Prefix | */protheus/delta/intake/* |
| File pattern | * |
| Record path | rows |
| Connector suffix | _carol |
| Schedule cron | Agendamento da execução |
| Status | Escolher entre conexão "Active" ou "Paused" |
5.2 Large-scale transfer mode (STS)
- Test with bucket: Colar qualquer nome de bucket como exemplo para validar o acesso via STS.
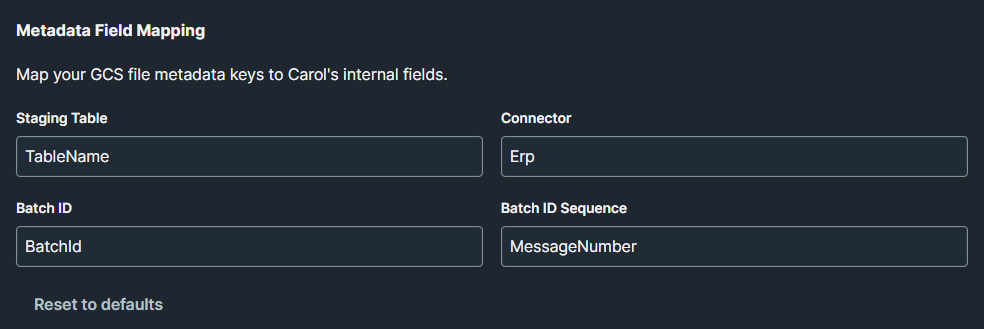
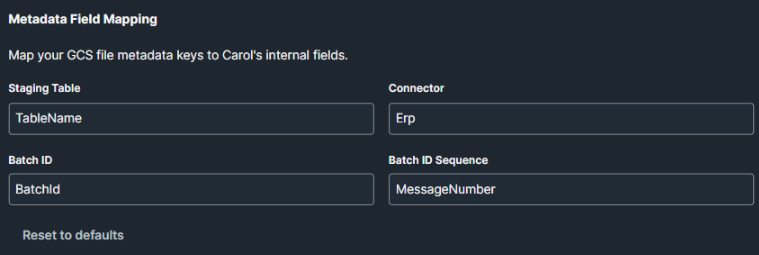
5.3 Metadata Field Mapping
Nesse passo deve-se mapear quais campos dos metadados dos arquivos do bucket vão direcionar para quais staging tables e connectors. O campo de Batch ID é obrigatório para garantir a rastreabilidade dos dados, e o campo de Batch ID Sequence é recomendado para facilitar o monitoramento do progresso da ingestão.
| Campo | Valor |
|---|---|
| Staging Table | TableName - Irá direcionar para a tabela de staging correspondente |
| Connector | Erp - Irá direcionar para o conector correspondente |
| Batch ID | BatchId - Irá garantir a rastreabilidade dos dados |
| Batch ID Sequence | MessageNumber - Irá facilitar o monitoramento do progresso da ingestão |
5.4 Tenant Allow List
Nesse passo deve-se selecionar quais tenants estão autorizadas a participar do processo de ingestão via batch. A partir da seleção, o sistema já exibe o nome do bucket formatado com as variáveis para validação.