Carol File Loader
Este aplicativo para carregamento de dados estruturados na plataforma Carol é uma ferramenta que permite aos usuários o download e carga de dados nos formatos CSV, XLSX, JSON e API (em breve), utilizando os protocolos HTTP, HTTPS e FTP (em breve). Além disso, o aplicativo suporta os padrões de autenticação Basic, Bearer e OAuth2, o que garante a segurança e privacidade dos dados utilizados. A ferramenta suporta a configuração de diversas fontes de dados e a carga agendada ou manual de maneira escalável.
Siga os links abaixo para instruções detalhadas sobre o uso do app:
Instalação
Para instalar o app é necessário que o mesmo esteja disponível para a organização a que pertence à Tenant.
→ Instalando o Carol App nas Tenants
Configuração
Pipeline
Utilizando a configuração CONFIG_JSON, a aplicação suporta a definição de múltiplos pipelines de carga de dados.

[
"pipeline_name": {
"format": enum (Format),
"url": string,
"headers": {
string: string,
...
},
"auth": {
object (Auth)
},
"carol": {
object (Carol)
},
"csv": {
object (Csv)
},
"json": {
object (Json)
},
"parquet": {
object (Parquet)
}
},
{
object (Pipeline)
},
...
]
| Campo | Descrição |
|---|---|
| pipeline_name | stringUm nome definido pelo usuário para o pipeline. Os nomes dos pipelines devem ser únicos para esta configuração. |
| format | enum FormatDescreve o formato dos dados sendo carregados. |
| url | stringURL do arquivo ou endpoint onde residem os dados que serão carregados. |
| headers | map (key: string, value: string)Cabeçalhos HTTP personalizados que serão enviados na requisição da URL. Exemplos: "Authorization": "cf365fe19f224be09499af3f65aedebb" "X-Api-Key": "449703493e2f41318585856d8c1a52ff" |
| auth | object AuthConfigurações específicas da autenticação utilizada na requisição da URL. |
| carol | object CarolConfigurações específicas do conector Carol. |
| csv | object CsvConfigurações específicas para dados no formato CSV. |
| xlsx | object XlsxConfigurações específicas para dados no formato XLSX. |
| json | object JsonConfigurações específicas para dados no formato JSON. |
| parquet | object ParquetConfigurações específicas para dados utilizando PARQUET. |
[
{
"pipeline_name_1": {
"url": "https://raw.githubusercontent.com/jpatokal/openflights/master/data/airports.dat",
"format": "csv",
"carol": {
...
},
"csv": {
...
}
}
},
{
"pipeline_name_2": {
"url": "https://data.wa.gov/api/views/f6w7-q2d2/rows.json?accessType=DOWNLOAD",
"headers": {
"Content-Type": "application/json",
"X-Custom-Header": "foobar"
},
"format": "json",
"carol": {
...
},
"json": {
...
}
}
},
{
"pipeline_name_3": {
"url": "https://drive.google.com/uc?export=download&id=1XUBPHPuqV9JqzVDiFeuxXDVs1234",
"format": "xlsx",
"carol": {
...
},
"xlsx": {
...
}
}
},
{
"pipeline_name_4": {
"url": "gs://bucket-name-gcp/airports.parquet",
"format": "parquet",
"auth": {
"type": "gcp",
"config": {
...
}
},
"carol": {
...
},
"parquet": {
...
}
}
}
]
Format
Formatos suportados pela aplicação.
| Valor | Descrição |
|---|---|
| csv | Arquivo texto em formato estruturado de tabela, com colunas separadas por separador, normalmente , ou ;. |
| xlsx | Arquivo no formato Microsoft Excel Open XML Spreadsheet, armazena os dados em estrutura tabular, organizados em planilhas. |
| json | Arquivo texto de padrão aberto, armazena dados em pares atributo-valor e arrays. |
| parquet | Parquet é um formato de arquivo em coluna com otimizações para acelerar as consultas. |
Auth
{
"type": enum (AuthType),
"config": {
"username": string,
"password": string,
"token_url": string,
"client_id": string,
"client_secret": string,
"refresh_token": string,
"redirect_uri": string,
"service_account_key": string
}
}
| Campo | Descrição |
|---|---|
| type | enum AuthTypeDescreve o tipo de autenticação utilizado no pipeline. |
| username | stringIdentificação do usuário utilizado na autenticação. Somente Basic. |
| password | stringSenha utilizada na autenticação. Somente Basic. |
| token_url | stringURL do serviço de autorização utilizado para geração de token de acesso. Bearer e OAuth2. Ver |
| cliente_id | stringIdentificador público para o aplicativo no fluxo de autenticação OAuth2. Bearer e OAuth2. Ver |
| cliente_secret | stringSegredo compartilhado entre o aplicativo e Authorization Server durante o fluxo de autenticação OAuth2. Bearer e OAuth2. Ver |
| refresh_token | stringInicialmente recebido juntamente com o token de acesso durante o fluxo de autenticação OAuth2, permite a obtenção não interativa de um novo token de acesso após sua expiração. Somente OAuth2. Ver |
| redirect_uri | stringURL cadastrada no aplicativo OAuth2 como retorno após autenticação. Somente OAuth2. Ver |
| service_account_key | stringRepresentação Base64 do conteúdo do JSON de chave para a conta de serviço utilizada na autenticação com Google Cloud. Somente GCP. |
"auth": {
"type": "oauth2",
"config": {
"token_url": "https://oauth2.googleapis.com/token",
"client_id": "1234931896063-664elpmh56lnjp1egp897l8cgf5r5r2l.apps.googleusercontent.com",
"client_secret": "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",
"refresh_token": "1//04e-1hR3F96BmCgYIARAAGAQSNwF-L9Ir2HYVflNTNx6kVIm8cjGkRnnPY4F7ix8PQbN0AuQPjtC35RDVmnEQHYoySyRrfaL1234",
"redirect_uri": "https://totvslabs.carol.ai/toolbox/apps/dev/carolfileloader/1.0.11/index.html"
}
}
"auth": {
"type": "gcp",
"config": {
"service_account_key": "ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3VudCIsCiAgInByb2plY3RfaWQiOiAicHJvamVjdC1uYW1lIiwKICAicHJpdmF0ZV9rZXlfaWQiOiAiNWI5MjI0Y2Q2YTdhY2YzIiwKICAicHJpdmF0ZV9rZXkiOiAiLS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tXG5cbi0tLS0tRU5EIFBSSVZBVEUgS0VZLS0tLS1cbiIsCiAgImNsaWVudF9lbWFpbCI6ICJzZXJ2aWNlLWFjY291bnRAaWFtLmdzZXJ2aWNlYWNjb3VudC5jb20iLAogICJjbGllbnRfaWQiOiAiMTE2MjMyNTA1MzIxIiwKICAiYXV0aF91cmkiOiAiaHR0cHM6Ly9hY2NvdW50cy5nb29nbGUuY29tL28vb2F1dGgyL2F1dGgiLAogICJ0b2tlbl91cmkiOiAiaHR0cHM6Ly9vYXV0aDIuZ29vZ2xlYXBpcy5jb20vdG9rZW4iLAogICJhdXRoX3Byb3ZpZGVyX3g1MDlfY2VydF91cmwiOiAiaHR0cHM6Ly93d3cuZ29vZ2xlYXBpcy5jb20vb2F1dGgyL3YxL2NlcnRzIiwKICAiY2xpZW50X3g1MDlfY2VydF91cmwiOiAiaHR0cHM6Ly93d3cuZ29vZ2xlYXBpcy5jb20vcm9ib3QvdjEvbWV0YWRhdGEveDUwOS9zZXJ2aWNlLWFjY291bnQlNDBpYW0uZ3NlcnZpY2VhY2NvdW50LmNvbSIKfQo="
}
}
AuthType
Tipos de autenticação suportados pela aplicação.
| Valor | Descrição |
|---|---|
| basic | Informações de autenticação (usuário e senha) são codificadas como Base64 no cabeçalho Authorization. |
| bearer | Credenciais de autenticação (ID e Secret) são utilizadas para obtenção de token de acesso em um Authorization Server. A requisição ao recurso definido em URL utiliza o token recebido no cabeçalho Authorization. |
| oauth2 | Credenciais de autenticação (ID e Secret) são utilizadas em conjunto com o refresh_token para obtenção de token de acesso em um Authorization Server. Atualmente somente o fluxo de authenticação de aplicativo Web é suportado. A requisição ao recurso definido em URL utiliza o token recebido no cabeçalho Authorization |
| gcp | Utilizando a chave de uma conta de serviço para Google Cloud. |
Carol
{
"connector": string,
"staging": string,
"crosswalk": [
string,
...
],
"flexible": boolean
}
| Campo | Descrição |
|---|---|
| connector | stringNome do conector que possui a tabela de destino para a carga de dados. |
| staging | stringNome da tabela de staging onde os dados serão armazenados na plataforma. |
| crosswalk | string[]Colunas que serão usadas como chave primária da tabela. |
| flexible | booleanIndica se colunas adicionais serão ignoradas ou não. |
"carol": {
"connector": "openflights",
"staging": "sample",
"crosswalk": ["id", "iata"],
"flexible": true
}
Csv
{
"delimiter": string,
"header": boolean,
"columns": [
string,
...
],
"ignore_schema": true
}
| Campo | Descrição |
|---|---|
| delimiter | stringDelimitador de colunas usado no arquivo CSV. |
| header | booleanIndica se o arquivo CSV contém uma linha com os cabeçalhos ou não. |
| columns | string[]Define o nome das colunas do arquivo CSV que não possui cabeçalhos. |
| ignore_schema | booleanDesabilita a inferência de tipos a partir do schema original considerando todos as colunas como string. Valor padrão: false. |
"csv": {
"delimiter": ",",
"header": false,
"columns": [
"id",
"name",
"city",
"country",
"iata",
"icao",
"latitude",
"longitude",
"altitude",
"timezone",
"dst",
"tz",
"type",
"source"
],
"ignore_schema": true
}
Xlsx
Atualmente há duas formas de definir o JSON de configuração da importação de arquivos XLSX.
A V2 permite selecionar colunas específicas do arquivo XLSX e renomear essas colunas para serem importadas na Plataforma Carol. Dessa forma é possível lidar com colunas com nomes com caracteres especiais e espaços sem necessariamente alterar o arquivo XLSX, bastando alterar o nome dessa coluna para um nome de coluna suportado pela plataforma, isto é, um nome sem espaços, acentos ou outros caracteres especiais.
Representação JSON V2
"xlsx": {
"version": "V2",
"sheet": "depara_centro_custo",
"hasHeader": true,
"columns": {
"Código CC": "codigo_cc",
"Código Descrição": "codigo_descrição",
"processo": "processo",
"Macro_Processo": "macro"
}
}
| Campo | Descrição |
|---|---|
| sheet | stringNome da planilha que contém os dados a serem utilizados. |
| hasHeader | booleanIndica se o arquivo XLSX contém uma linha com os cabeçalhos ou não. |
| columns | object[string, string]A chave será o nome da coluna no arquivo XLSX e o valor será o novo nome da coluna na plataforma Carol. |
| version | stringDefine a versão da configuração. Quando não informado ou com valor diferente de V2, o comportamento padrão será utilizado, onde apenas os nomes das colunas serão passados como array. |
A V1 não possui o nível de controle necessário para permitir renomear as colunas, na verdade nessa versão é apenas informado uma lista de colunas, essa lista de colunas representa os nomes de colunas que serão criadas na staging table que receberão os dados do arquivo XLSX.
Por exemplo caso seja definido o JSON
{
"sheet": "Planilha 2",
"header": true,
"columns": [
"nome",
"idade",
"area_de_interesse"
],
"version": "V1"
}
Serão importadas as três primeiras colunas da "Planilha 2" e serão criadas colunas com o nomes de colunas listadas no atributo columns.
Caso a versão não seja fornecida ou seja diferente de V2, o comportamento da V1 será utilizado por padrão.
Representação JSON V1
{
"sheet": string,
"header": boolean,
"columns": [
string,
...
],
"version": string
}
| Campo | Descrição |
|---|---|
| sheet | stringNome da planilha que contém os dados a serem utilizados. |
| header | booleanIndica se o arquivo XLSX contém uma linha com os cabeçalhos ou não. |
| columns | string[]Define os nomes das colunas do arquivo XLSX que não possuem cabeçalhos. Em versões anteriores à V2, define as colunas a serem carregadas. |
| version | stringDefine a versão da configuração. Quando não informado ou com valor diferente de V2, o comportamento da V1 será utilizado, onde apenas os nomes das colunas serão passados como array. |
"xlsx": {
"sheet": "Plan1",
"header": true
}
Json
{
"root": string,
"properties": [
string,
...
]
}
| Campo | Descrição |
|---|---|
| root | stringNotação JSON que representa o array de dados a serem carregados. Exemplos: "root": "" "root": "hits" "root": "meta.view.columns" |
| properties | string[]Lista de campos em notação JSON que devem ser consideradas durante a carga de dados. Este campo deve ser suprimido para que todos os dados sejam utilizados. |
"json": {
"root": "meta.view.columns",
"properties": [
"id",
"name",
"dataTypeName",
"fieldName",
"position",
"renderTypeName",
"format",
"format.align"
]
}
Parquet
{
"columns": [
string,
...
],
"ignore_schema": true
}
| Campo | Descrição |
|---|---|
| columns | string[]Seleciona o nome das colunas do arquivo PARQUET que devem ser carregados, podendo ser omitido para carregar todas as colunas. |
| ignore_schema | booleanDesabilita a inferência de tipos a partir do schema original considerando todos as colunas como string. Valor padrão: false. |
"parquet": {
"ignore_schema": true
}
Exemplo de Arquivo JSON para Google Sheets
Para facilitar a implementação em projetos, abaixo é disponibilizado um exemplo de arquivo JSON, que importa uma planilha do Google Sheets. Esse exemplo pode ser utilizado em conjunto com a documentação afim de ser modificado e alterado.
[
{
"import-my-xlsx-to-carol": {
"url": "https://docs.google.com/spreadsheets/d/MY-SHEET-ID/export?format=xlsx",
"format": "xlsx",
"auth": {
"type": "oauth2",
"config": {
"token_url": "https://oauth2.googleapis.com/token",
"client_id": "xxxxxxxxxxxx.apps.googleusercontent.com",
"client_secret": "xxxxxxxxxxxx",
"refresh_token": "xxxxxxxxxxxx",
"redirect_uri": "https://my-organization.carol.ai/my-tenant/apps/carolfileloader/my-carol-file-loader-version/redirect.html"
}
},
"carol": {
"connector": "my-carol-connector",
"staging": "my-staging-table",
"crosswalk": ["PK"],
"flexible": true
},
"xlsx": {
"sheet": "my-sheet",
"header": true,
"columns": [
"column-1", "column-2", "column-3"
]
}
}
}
]
Este arquivo irá extrair a planilha de ID MY-SHEET-ID, no formato xlsx (ou Google Planilhas), utilizando autenticação oauth2, no tenant my-tenant, na org my-organization. O arquivo será inserido na plataforma Carol no connector my-carol-connector, na staging table my-staging-table, terá como crosswalk (primary key) o camo PK e a fonte de dados utilizada dentro da planilha será a aba my-sheet, extraindo os campos "column-1", "column-2", "column-3".
Geração de ClientID
Após realizar a intalação do app Carol File Loader e fazer sua configuração, você deverá criar um clientid, para isso você deve:
-
Clicar no link Web App do app instalado conforme na imagem abaixo:

-
Selecionar Google como opção de provedor
-
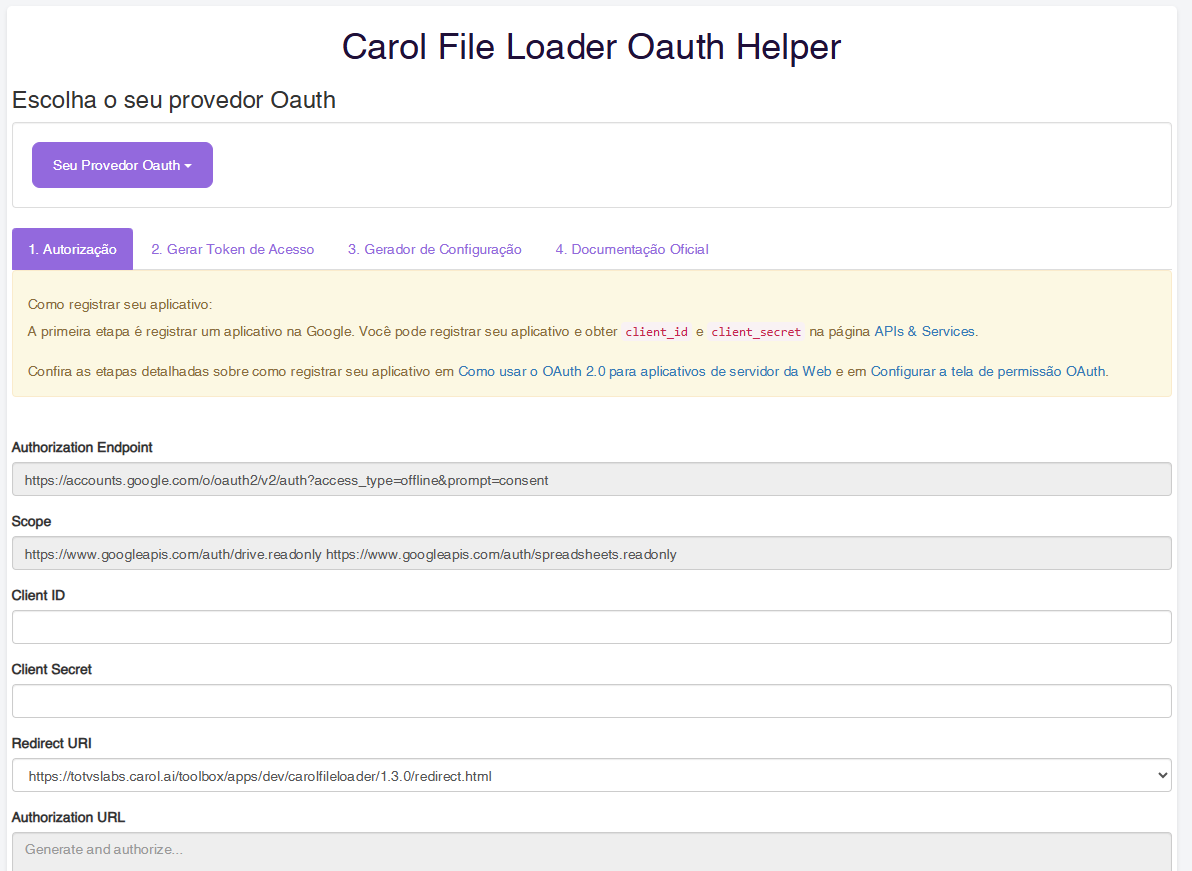
Clique no link do texto destacado de amarelo que descreve o Passo 1: existe um link no texto API's e Services (https://console.cloud.google.com/apis/dashboard) :
-
A partir daqui, siga as intruções de habilitação de api mencionadas no LINK
Agendamento
Para realizar o agendamentos de pipelines após a a carga de dados feita pelo file loader é necessario adicionar a linha abaixo ao json de configuração, isso irá acionar as pipelines pipelines do app desejado.
"NOME DO APP QUE POSSUI A PIPEPLINE": ["PIPELINE1", "PIPELINE2"]
}
Exemplo:
...
},
"process_pipelines": {
"carolfileloader": ["customer", "records"]
}