Carol In Memory
O Carol In Memory é uma aplicação de extração e disponibilização de dados da plataforma Carol, utilizando BigQuery e Cloud Storage e Cache de dados em memória. O projeto é encapsulado como um Carol App, permitindo agendamento de execuções e facilitando a distribuição para clientes da plataforma TOTVS Carol. Existem dois tipos de deployment:
- Carol In Memory para extração de dados para o GCS.
- Carol In Memory como serviço de cacheamentoo em memória.
- Carol In Memory integrado ao pyCarol para obter dados.
Fluxo 1 - Carol In Memory para extração de dados para o GCS.
O fluxo para extração de dados para o GCS serve majoritáriamente para disponibilização de arquivos em .parquet para uso em outros sistemas. Para fazer proveito desse fluxo, basta utilizar o json como exemplo abaixo, no campo Entities.

{
"project": "common",
"entities": [
{
"name": "customers",
"query": "SELECT * FROM `carol-xxx.xxx.customers",
"operation": "FULL_LOAD",
"partition_field": "_ingestionDatetime",
},
{
"name": "sales",
"query": "SELECT * FROM `carol-xxx.xxx.sales",
"operation": "INCREMENTAL",
"partition_field": "_ingestionDatetime",
},
{
"name": "orders",
"query": "SELECT * FROM `carol-xxx.xxx.orders",
"operation": "DELETE",
},
]
}
Parâmetros de Configuração
-
Name (STRING): Define o nome da entidade e o padrão de nome em que os parquets serão extraídos. -
Query (STRING): Define a sentença SQL que será executada e seu resultado será extraído. -
Partition Field (STRING): Define se a extração deve ser particionada, ou seja, dividir os arquivos parquets em partições lógicas de acordo com um campo de data. A partição sempre é na granularidade DATE. -
Slack Webhook URL (STRING): Webhook para notificação de falhas ou erros de execução via Slack. Exemplo:https://hooks.slack.com/services/T00000000/B00000000/XXXXXXXXXXXXXXXXXXXXXXXX -
Operation (STRING): Define a estratégia de carga:FULL_LOAD: Executa uma carga completa, removendo todo o histórico de dados e carregando novamente.INCREMENTAL: Executa a carga completa, porém não removendo todo o histórico de dados. A lógica incremental deve ser implementada na query no parâmetroentities.DELETE: Executa apenas a limpeza de dados da entidade com dado nome.
-
Use Flight Server (BOOLEAN): Define se será utilizado o Flight Server embutido do Carol App para conexão com ferramentas como o Looker Studio:true: ativa o servidor para exposição dos dados.false: padrão, não utiliza o Flight Server.
Observação: O recurso Use Flight Server ainda está em desenvolvimento!
Fluxo 2 - Carol In Memory como serviço de cacheamentoo em memória.
O fluxo como serviço de cacheamentoo em memória funciona via recurso Carol App Online. Ele provisiona uma instância online, com capacidade de memória e poder de processamento definido. Esse processo disponibiliza uma série de endpoints para extração de dados do BigQuery (sem utilização de slots) e cacheamento em memória para utilização rápida via SQL.
Após clicar em "Run", o processo será iniciado e estará disponível para experimentação em https://{tenantName}-carolinmemory.apps.carol.ai/docs. Dentro a URL, haverá a lista de endpoints abaixo. Todas as requisições precisam ser acompanhadas de Oauth Token da plataforma ou Connector Id + Token.
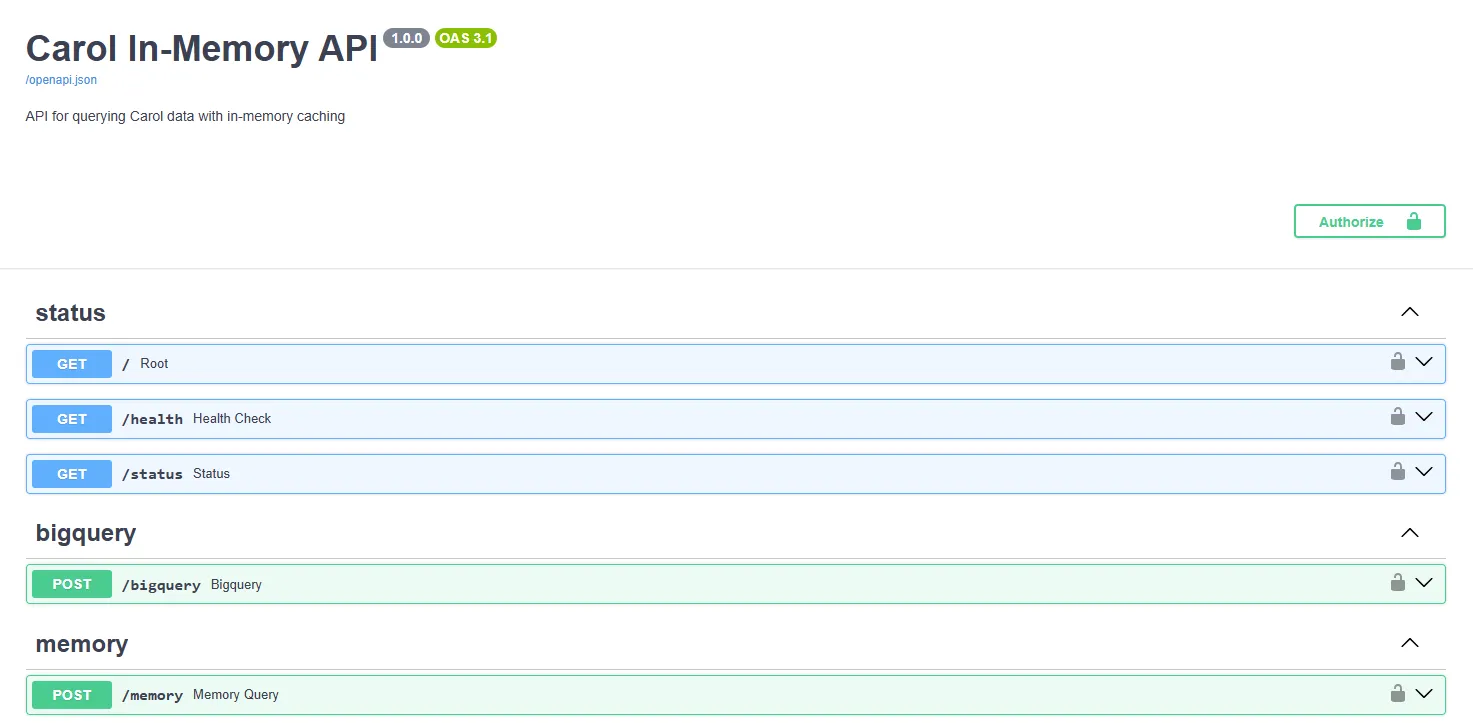
Root
Endpoint direcionado para /health. Utilizado para verificar a saúde do serviço.
curl -X 'GET' \
'https://{tenantName}-carolinmemory.apps.carol.ai/' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN'
{
"status": "ok",
"service": "carol-in-memory",
"timestamp": "2026-01-16T17:29:58.507813"
}
Health
Utilizado para verificar a saúde do serviço.
curl -X 'GET' \
'https://{tenantName}-carolinmemory.apps.carol.ai/health' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN'
{
"status": "ok",
"service": "carol-in-memory",
"timestamp": "2026-01-16T17:29:58.507813"
}
Status
Utilizado para obter mais detalhes sobre o serviço. Possível verificar quantas tabelas estão cacheadas, quais são, se há algum erro nas requisições, etc.
curl -X 'GET' \
'https://{tenantName}-carolinmemory.apps.carol.ai/status' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN'
{
"success": true,
"timing": null,
"timestamp": "2026-01-16T17:35:46.159149",
"memory_mode": true,
"database_path": null,
"tables": [
"ingestion_computers", "ingestion_users", "ingestion_sales"
],
"table_count": 3,
"error": null
}
Bigquery
Utilizado para extrair dados do BigQuery Storage. Apenas disponível em tabelas físicas (não é possível utilizar diretamente em views) e necessário para cachear os dados em memória. Nesse passo, estamos extraíndo os dados do BigQuery para uso posterior na chamada /memory, que pode utilizar diretamente SQL para analisar, deduplicar e consolidar dados.
curl -X 'POST' \
'https://{tenantName}-carolinmemory.apps.carol.ai/bigquery' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN' \
-H 'Content-Type: application/json' \
-d '{
"table": "ingestion_computers",
"columns": [
"policyid", "errorinfo", "duplicate"
],
"filter": "_ingestionDatetime >= DATETIME_SUB(CURRENT_DATETIME(), INTERVAL 7 DAY)",
"cache_to_memory": true
}'
{
"success": true,
"timing": {
"bq_query_seconds": 6.0703696249984205,
"duckdb_query_seconds": null,
"total_seconds": null
},
"timestamp": "2026-01-16T17:34:03.660000",
"table": "ingestion_computers",
"rows": 120120,
"cached": true,
"data": null,
"error": null
}
Parâmetros:
table (STRING): nome da tabela do bigquery que deve ser extraída (ingestion_customers, ingestion_computers).columns (LIST[STRING]): lista de strings contendo as colunas da tabela a serem extraídas.filter (STRING): filtro lógico a ser aplicado na consulta. O recomendado é utilizar filtros de particionamento para melhorar a performance.cache_to_memory (BOOLEAN): booleano que indica se o App deve enviar o retorno do BigQuery ao armazenamento em memória. Casotrue, não exibe diretamente o resultado. Casofalseexibe o resultado diretamente no retorno.
Memory
Utilizado para realizar queries em SQL nativo em tabelas cacheadas via endpoint /bigquery anteriormente. Esse endpoint aceita SQL diretamente e terá como referência os nomes das tabelas inseridas em table do endpoint /bigquery. É possível utilizar JOINS, QUALIFY e diversas outras sentenças SQL de acordo com o dialeto DuckDB.
curl -X 'POST' \
'https://{tenantName}-carolinmemory.apps.carol.ai/memory' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN' \
-H 'Content-Type: application/json' \
-d '{
"query": "SELECT * FROM ingestion_computers QUALIFY ROW_NUMBER() OVER ( PARTITION BY policyid ) = 1;"
}'
{
"success": true,
"timing": {
"bq_query_seconds": null,
"duckdb_query_seconds": 0.005848619999596849,
"total_seconds": null
},
"timestamp": "2026-01-16T17:41:05.503539",
"data": [
{
"duplicate": false,
"errorinfo": null,
"policyid": "ABC"
},
{
"duplicate": false,
"errorinfo": null,
"policyid": "DEF"
},
{
"duplicate": false,
"errorinfo": null,
"policyid": "XPTO"
},
{
"duplicate": false,
"errorinfo": null,
"policyid": "123"
}
],
"rows": 4,
"error": null
}
Add
Adiciona no cacheamento de memória um JSON (dataframe) como tabela, que ficará disponível para consultas SQL. Útil para tabelas fixas ou conjuntos de dados em dataframes.
curl -X 'POST' \
'https://{tenantName}-carolinmemory.apps.carol.ai/add' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN' \
-H 'Content-Type: application/json' \
-d '{
"table_name": "my_enum_table",
"data": [
{"id": [1, 2], "name": ["Alice", "Bob"]}
]
}'
{
"success": true,
"timing": null,
"timestamp": "2026-01-16T17:47:08.482886",
"table": "my_enum_table",
"rows": 1,
"message": "Data cached successfully to table 'my_enum_table'",
"error": null
}
Append
Executa o mesmo método de /bigquery porém ao invés de substituir a tabela a cada execução, faz o append de uma tabela existente.
curl -X 'POST' \
'https://{tenantName}-carolinmemory.apps.carol.ai/append' \
-H 'accept: application/json' \
-H 'Authorization: Bearer TOKEN' \
-H 'Content-Type: application/json' \
-d '{
"table": "ingestion_computers",
"columns": [
"policyid", "errorinfo", "duplicate"
],
"filter": "_ingestionDatetime >= DATETIME_SUB(CURRENT_DATETIME(), INTERVAL 1 DAY)",
"cache_to_memory": true
}'
{
"success": true,
"timing": {
"bq_query_seconds": 6.0703696249984205,
"duckdb_query_seconds": null,
"total_seconds": null
},
"timestamp": "2026-01-16T17:34:03.660000",
"table": "ingestion_computers",
"rows": 120,
"cached": true,
"data": null,
"error": null
}
Execução remota via API e acionamento sob demanda
É possível realizar uma execução remota do Processo Batch do Carol App, podendo dinâmicamente apontar tabelas ou queries a serem exportadas. Esse procedimento é útil quando queremos sincronizar parte das tabelas de um ambiente.
Para isso, é necessário utilizar a API da plataforma Carol abaixo, com método POST.
curl -X 'POST' \
'https://api.carol.ai/api/v3/tasks/new' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer TOKEN' \
-d '{[...]}'
O body a ser enviado é o abaixo, onde está sinalizado o que deve ser alterado para cada execução. Os Ids informados na requisição são obtíveis por meio da interface da plataforma Carol ou pelas API disponibilizadas.
{
"mdmData": {
"mdmResourcesCleanUp": false,
"mdmAiAlgorithmName": "inmemoryexport",
"mdmAiProcessName": "Carol_In_Memory_Export",
"mdmAppSettingsOverride": {{JSON DE CONFIGURAÇÃO}},
"mdmAiProcessId": "XXX", <-- Inserir o AI Process Id real da tenant que irá processar a requisição.
"mdmTenantId": "XXX", <-- Inserir Tenant Id real da tenant que irá processar a requisição.
"mdmName": "carolinmemory",
"mdmAiProcessType": "BATCH",
"mdmTenantAppId": "XXX" <-- Inserir o App Id real da tenant que irá processar a requisição.
},
"mdmEntityType": "mdmTask",
"mdmTaskLevel": "mdmTenant",
"mdmTaskType": "AI_PROCESS",
"mdmTenantId": "XXX" <-- Inserir Tenant Id real da tenant que irá processar a requisição.
}
Fluxo 3 - Carol In Memory integrado ao pyCarol para obter dados.
É possível utilizar o pyCarol, na versao 2.56.13, para ler dados do BigQuery integrando diretamente com o Storage do BigQuery sem utilizar SLots, o que em diversos casos significa ler dados mais rapidamente e certamente ler dados com um custo muito mais baixo por nao depender de slots.
O procedimento para ler dados do BigQuery integrado ao In-Memory (pyCarol) é feito da seguinte forma:
from dotenv import load_dotenv
from pycarol import BQStorage, Carol, Memory
load_dotenv()
carol = Carol()
bq_storage = BQStorage(carol)
memory = Memory()
table = bq_storage.query(
table_name="ingestion_stg_connectorname_tablename",
column_names=["column_a", "column_b"],
row_restriction="_ingestionDatetime > '2026-01-01'",
max_stream_count=50,
)
memory.add("ingestion_stg_connectorname_tablename", (table))
results_df = memory.query(
"""
SELECT
MAX(column_a)
FROM
ingestion_stg_connectorname_tablename
WHERE
column_b > 32
"""
)
print(results_df.head())
Dependências que você precisará referenciar para rodar o aplicativo acima:
pycarol==2.56.13
python-dotenv==1.1.0
duckdb==1.4.4
pyarrow