Data Validation
Este documento detalha o processo de configuração e uso do módulo de Validação de Dados (Data Validation), na plataforma Carol, que se integra ao DBT (Data Build Tool) para garantir a qualidade dos modelos de dados.
1. Modelo de solução
O modelo de implementação da solução é apresentado na imagem abaixo.
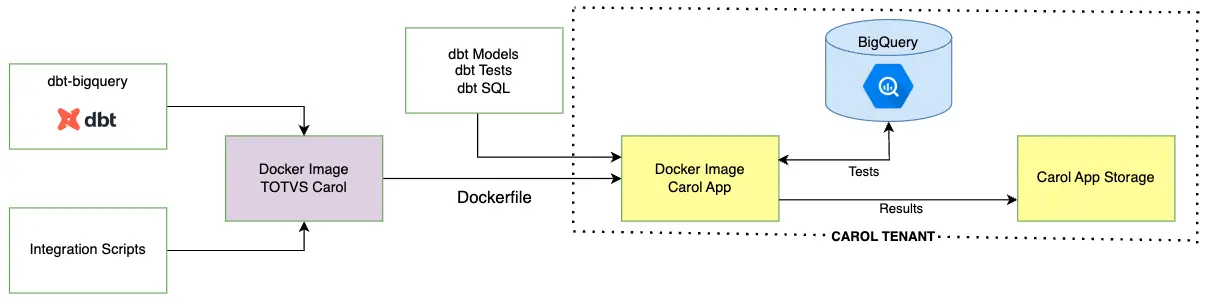 Imagem 1: Diagrama do modelo de solução do Data Validation
Imagem 1: Diagrama do modelo de solução do Data Validation
Esta imagem ilustra o fluxo de uma solução de validação de dados utilizando o DBT. A TOTVS fornece uma imagem Docker base que já contém as dependências necessárias para rodar o DBT dentro da plataforma Carol. Além disso, o usuário fornece os scripts de integração do DBT para a realização de testes de validação de dados.
O DBT é responsável por enviar à Carol os testes definidos pelos usuários, reportando se há erro ou não na validação. Após a execução das validações, os resultados são persistidos. Isso permite que os status de sucesso ou falha das validações sejam visualizados pelos usuários.
Este modelo é ideal para usuários que desejam adicionar uma camada de qualidade de dados ao projeto, pois permite que testes de validação sejam feitos de forma sistemática e automatizada. Isso traz maior confiança e resiliência dos processos de dados.
O modelo possui as seguintes configurações:
dbt-bigquery 1.7.2: suíte responsável pela integração com a Carol.dbt_utils 1.1.1: suíte com macros úteis, que incluem testes, para serem usadas em diferentes projetos.dbt_expectations 0.9.0: suíte focada em testes de dados.
A utilização deste recurso requer que o usuário conheça padrões, linguagem, estrutura de pastas e formas de implementação do DBT. Para mais detalhes sobre como utilizar o DBT, consulte sua documentação.
O DBT executa as validações de dados utilizando SQL dentro do dataset BigQuery da tenant. Portanto, é necessário estar ciente de que todas as validações criadas geram jobs que consomem slots do BigQuery. Dessa forma, seguem abaixo algumas dicas para construção e utilização de testes dentro da plataforma Carol.
- Valide apenas dados e regras essenciais para o negócio.
- Utilize apenas os testes necessários para validação dos dados.
- Todos os jobs de validação de dados são enviados com prioridade BATCH. Isso gera uma menor concorrência com jobs de SQL Process da plataforma.
2. Configuração
A presente seção detalha o passo-a-passo de configuração deste modelo. É preciso que o código-fonte esteja configurado num repositório do GitHub, pois será dele que a Carol consultará os arquivos na hora de montar a imagem do Docker. Este repositório pode ser um novo ou a partir de um já existente que contenha códigos de outras funcionalidades da tenant. Segue a definição da estrutura necessária de arquivos para este módulo. Cada um deles é explicado com detalhes adiante.
/ (Pasta Raiz do Repositório)
├── manifest.json # Configuração
└── data-validation/ # Diretório para scripts de validação
├── Dockerfile # Contendo a configuração do contêiner
└── models/ # Diretório para os modelos de dados
└── sources.yml # Arquivo com configurações dos testes
└── tests/ # (Opcional) para testes customizados
└── generic/ # Testes genéricos e auxiliares
└── *.sql # Arquivos SQL para testes customizados
2.1 manifest.json
O arquivo manifest.json é o responsável por configurar o AI Process dentro do Carol App. É por meio deste AI Process que o Data Validation funcionará. A seguir tem-se um exemplo de configuração do arquivo manifest.json.
Caso o seu Carol App já possua outros AI Process, basta adicionar o exemplo abaixo a um Carol App já existente.
{
"batch": {
"processes": [{
"name": "Data_Validation",
"algorithmName": "datavalidation",
"algorithmDescription": {
"en-US": "Your Description.",
"pt-BR": "Sua Descricao"
},
"algorithmTitle": {
"en-US": "Data Validation",
"pt-BR": "Data Validation"
},
"instanceProperties": {
"profile": "",
"properties": {
"dockerName": "datavalidation",
"instanceType": "c1.nano"
},
"preemptible": false,
"environments": {
"PREFECT_LOGGING_HANDLERS_CONSOLE_FORMATTER": "json"
}
}
}]
},
"docker": [
{
"dockerName": "datavalidation",
"dockerTag": "0.0.1",
"gitBranch": "main",
"gitPath": "/data-validation",
"instanceType": "c1.nano",
"gitDockerfileName": "Dockerfile",
"gitRepoUrl": "https://url.com/seurepositorio"
}]
}
Segue o detalhamento das opções presentes no manifest.json (as opções em * não requerem alteração por parte do usuário, salvo exceções em casos mais avançados):
- batch.processes: seção que define as características do processo que será executado na plataforma.
- name: o nome identificador do processo dentro da Carol.
- algorithmName: o nome técnico do algoritmo. É usado internamente pela plataforma para referenciar este conjunto de instruções.
- algorithmDescription: contém a descrição do que o algoritmo faz, dividida por idiomas (en-US para inglês e pt-BR para português).
- algorithmTitle: o título amigável que aparecerá na interface da Carol para os usuários.
- instanceProperties: define as propriedades da infraestrutura onde o processo rodará:
- profile: geralmente usado para definir perfis de execução específicos (neste caso, está vazio, usando o padrão).
- properties:
- dockerName: associa este processo a uma definição de Docker específica que deve coincidir com o dockerName mais à frente neste mesmo manifesto.
- instanceType*: o tamanho da máquina/recurso computacional. Ver mais sobre tamanho das máquinas aqui.
- preemptible*: define se o processo pode rodar em instâncias "preemptivas" (mais baratas, mas que podem ser interrompidas pelo provedor de nuvem). O valor
falsesignifica que ele exige uma instância dedicada. - environments*: variáveis de ambiente configuradas para a execução.
- docker: esta seção detalha a origem do código e como a imagem Docker será construída.
- dockerName: o nome identificador da imagem Docker. Deve ser o mesmo nome colocado em
batch.instanceProperties.properties.dockerNamevisto anteriormente. - dockerTag: a versão da imagem para ajudar no controle de versionamento.
- gitBranch: a branch do repositório Git de onde estará este código.
- gitPath*: o caminho da pasta dentro do repositório onde se encontra o código do algoritmo.
- instanceType*: o tamanho da máquina/recurso computacional. Ver mais sobre tamanho das máquinas aqui. Deve ser o mesmo nome colocado em
batch.instanceProperties.properties.instanceTypevisto anteriormente. - gitDockerfileName*: o nome do arquivo Dockerfile que contém as instruções de montagem da imagem. O padrão é Dockerfile.
- gitRepoUrl: a URL do repositório Git onde este código fonte está hospedado.
- dockerName: o nome identificador da imagem Docker. Deve ser o mesmo nome colocado em
2.2 Dockerfile
A configuração do Dockerfile é simples, pois usa uma imagem personalizada pela plataforma Carol. Segue um exemplo de configuração do arquivo.
FROM gcr.io/labs-ai-apps-production/caroldatavalidation/datavalidation:1.0.0
# Pasta contendo o arquivo sources.yml com os testes de validação de dados
COPY ./models /usr/dbt/models
# Opcional: pasta contendo testes customizados
COPY ./tests /usr/dbt/tests
O exemplo acima pode ser customizado com outras ações caso seja necessário. Uma customização comum é a adição de novas dependências do DBT ou a atualização das dependências já existentes. Para isto, basta adicionar o arquivo de dependências em data-validation/packages.yml. Segue um exemplo de como configurar este arquivo.
A configuração do packages.yml personalizado substitui o arquivo presente na imagem do Docker. Portanto, é necessário incluir os pacotes do dbt_utils e dbt_expectations ainda que não sejam feitas alterações neles.
# Exemplo de packages.yml
packages:
- package: DBT-labs/dbt_utils
version: 1.1.1
- package: calogica/dbt_expectations
version: 0.9.0
- package: meupacote
version: x.x.x
Uma vez configurado o arquivo packages.yml, é necessário incluir o comando abaixo no Dockerfile após os comandos já citados anteriormente.
COPY ./packages.yml /usr/dbt
RUN dbt deps >> deps.txt
2.3 sources.yml
É no arquivo sources.yml que são declarados e organizados os Data Models da Carol que o usuário deseja testar. Segue um exemplo de como configurá-lo.
# Exemplo de sources.yml
version: 2
sources:
- name: "{{ target.dataset }}"
database: "{{ target.project }}"
schema: "{{ target.dataset }}"
tables:
- name: tabela1
# Exemplo de teste na tabela
tests:
- dbt_utils.expression_is_true:
arguments:
expression: "coluna1 + coluna2 = coluna3"
columns:
- name: coluna1
# Exemplo de teste em coluna
tests:
- unique
- name: coluna2
tests:
- not_null
- name: tabela2
columns:
- name: coluna1
tests:
- not_null
Como explicado na seção 1, este módulo já conta com os testes dos pacotes dbt_utils e dbt_expectations. Para conhecer melhor cada um dos testes disponíveis e como usá-los, consulte a documentação do dbt_utils e do dbt_expectations, respectivamente.
2.4 Testes genéricos
O DBT oferece a possibilidade de construir testes customizados caso o usuário tenha a necessidade de cobrir casos em que os pacotes vistos na seção 2.3 não atendem. Os testes genéricos devem estar em data-validation/tests/generic.
Antes de escrever testes, é importante se atentar para as seguintes regras:
- O usuário deve criar um arquivo de extensão sql.
- O nome do arquivo sql deve ser o mesmo do nome do teste.
Para construir um teste genérico, o usuário deve escrever uma query cujo resultado retorne nenhuma linha caso esteja correto. A seguir são demonstrado alguns exemplos de como fazer testes personalizados e como colocá-los no sources.yml representado na seção 2.3.
-- check_lower_case.sql
-- teste para checar se todas as linhas de uma coluna está em caixa baixa.
{% test check_lower_case(model, column_name) %}
select true
from
{{ model }}
where lower({{ column_name }}) != {{ column_name }}
{% endtest %}
# Representação do teste acima em sources.yml
# ... (Restante do código)
tables:
- name: tabela1
columns:
- name: coluna1
tests:
- check_lower_case
-- check_row_count.sql
-- teste para checar a quantidade de linhas de uma tabela
{% test check_row_count(model, expected_count) %}
select count(1)
from
{{ model }}
having count(1) != {{ expected_count }}
{% endtest %}
# Representação do teste acima em sources.yml
# ... (Restante do código)
tables:
- name: tabela1
tests:
- check_row_count:
expected_count: 2000
Para mais detalhes de como construir testes personalizados no DBT, consulte a documentação oficial.
Os testes genéricos em SQL aceitam o Jinja para referenciar dinamicamente tabelas do dataset e também para implementar funções avançadas. Para mais detalhes do uso do Jinja, consulte esta documentação.
Sempre otimize as consultas de forma a consumir a menor quantidade de dados possível. Não é necessário retornar o campo ou uma transformação, apenas o retorno de uma linha simples já é suficiente para que o DBT detecte se o teste passou ou não. Para validar quantos recursos seu teste está utilizando, é possível consultar o Plano de Execução.
2.5 GitHub
Todas as configurações feitas nas etapas anteriores devem ser salvas num repositório do GitHub. Para isto, faça commit do código num repositório à sua escolha, podendo ser público ou privado.
Para repositórios privados, é necessário que o usuário crie um token de acesso para o repositório. Este token será necessário nas etapas posteriores para construir o módulo dentro do Carol App. Para saber como criar um token no GitHub, consulte esta documentação.
3. Instalando o Data Validation no Carol App
Nesta seção, é detalhado como instalar o modelo configurado no Carol App.
3.1 Crie um Carol App
Esta etapa é opcional caso você já tenha um Carol App que deseja utilizar o Data Validation. No entanto, recomenda-se que tenha um Carol App dedicado a estas validações. Siga os seguintes passos:
-
Clique em
Carol Apps. -
Clique em
Create New App. -
Preencha os campos:
3.1. Label: nome do App que ficará visível para o usuário.
3.2. Name (Opcional): nome único do app. Opcional, pois já é preenchido automaticamente.
3.3. Version: a versão inicial do App. Deve usar o padrão Semantic Version. Para mais detalhes, consulte esta documentação.
3.4. Description (Opcional): uma breve descrição do objetivo do Carol App.
3.5. Unified Tenant (Opcional): caso queira vincular este app a uma tenant unificada.
-
Clique em
Create App.
3.2 Upload do manifest.json
Para fazer o upload do manifest.json, é preciso que ele esteja devidamente configurado. Para configurá-lo, consulte a seção 2.1. Para fazer o upload do arquivo, siga as seguintes etapas:
- Clique no seu Carol App.
- Clique em
Files. - Clique em
Upload file. - Escolha o manifest.json local e clique em
Abrir.
Caso o JSON esteja configurado corretamente, você deve ver o manifest.json na lista de arquivos como mostrado na imagem abaixo.

Imagem 2: evidência do arquivo manifest.json
3.3 Build do App
O módulo de Data Validation está pronto para ser construído no Carol App. Para isto basta:
- Clique no seu Carol App.
- Clique em
Build, no canto superior direito. - Selecione sua definição de Docker no canto esquerdo. Ela possui o mesmo nome definido em
docker.dockerNamenomanifest.json - Em
GitHub Tokencoloque o token gerado na etapa 2.5. - Em
Git Branch Namecoloque o nome da branch onde o código-fonte das suas configurações Data Validation está (geralmente está em main). - Clique em
Next. - Selecione a
Taga ser usada pela imagem do Docker (recomenda-se usar a tag do manifesto). - Confira se o tipo da instância da imagem do Docker está correspondente com a configurada no manifesto.
- Estando tudo certo, clique em
Build Image.
Este processo leva alguns minutos para concluir. Para certificar-se de que a imagem foi construída corretamente, clique em Process. Você deverá ser capaz de ver algo como mostrado na imagem a seguir.
 Imagem 3: exemplo de um processo batch para o Data Validation.
Imagem 3: exemplo de um processo batch para o Data Validation.
3.4 Executando a validação de dados
Para validar os dados de acordo com o que foi configurado na seção 2, basta seguir as seguintes etapas:
- Clique no seu Carol App.
- Clique em
Process. - Identifique o processo de validação de dados e clique em
Run Now.
3.5. Consultando os logs de execução
É possível ver o log de execução dos testes clicando na flag que aparece em Last Run (Queued, Running, Complete, etc.). Ao clicar, abrirá uma tela chamada Activity Details onde é possível ver com maiores detalhes a execução do processo conforme mostrado na imagem abaixo.
 Imagem 4: exemplos de logs do Data Validation.
Imagem 4: exemplos de logs do Data Validation.
Caso seja necessário, um relatório completo é gerado contendo o log completo da execução do DBT no contêiner. Este log é armazenado dentro do storage do Carol App da tenant que executou a tarefa de validação de dados. Ele pode ser acessado seguindo os seguintes passos:
- Clique no seu Carol App.
- Clique na aba
Storage. - Localize a pasta
data-validation/e clique nela. - Clique em um dos logs disponíveis para vê-lo na íntegra. Consulte a imagem abaixo para ter alguns exemplos de logs.
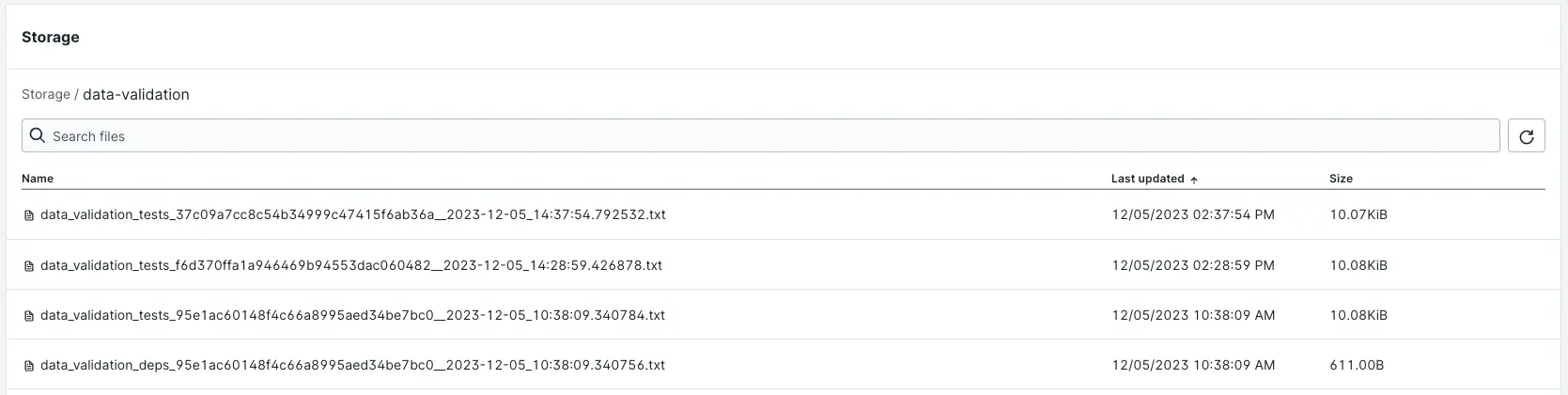 Imagem 5: exemplo de logs armazenados no storage.
Imagem 5: exemplo de logs armazenados no storage.
Tanto a aba Storage quanto a Logs do Carol App de Data Validation só são habilitados após a primeira execução de validação de testes.
Os relatórios têm um tempo de retenção padrão de sete dias corridos e são excluídos na próxima execução do processo de validação de dados.
3.6 Agendando a execução
Os testes de validação de dados podem e devem ser agendados para serem executados automaticamente conforme as necessidades do usuário. Para isso, basta seguir os seguintes passos:
- Clique no seu Carol App.
- Clique em
Process. - Identifique o processo de validação de dados.
- Clique em
+ Add a Schedule. - Configure de acordo com a sua necessidade.
É possível configurar o agendamento de forma avançada clicando em Manual e ajustando o campo Cron expression. Também é possível definir múltiplos crons para um mesmo AI Process. Para entender como usar expressões cron, consulte esta documentação.
3.7 (Opcional) Enviando os resultados para um WebHook
O resumo dos resultados da validação de dados podem ser enviados para WebHooks que se comuniquem com outras plataformas para gerar alertas.
Para configurar um WebHook no seu Carol App clique em Settings, depois Add Setting e preencha os campos conforme mostra a image abaixo.

Imagem 6: tela de configuração de um setting da Carol.
Depois de salvar, clique em Test Value, que está com o valor (empty) e substitua o valor pela URL do WebHook. O resultado deve ficar semelhante ao da imagem abaixo.
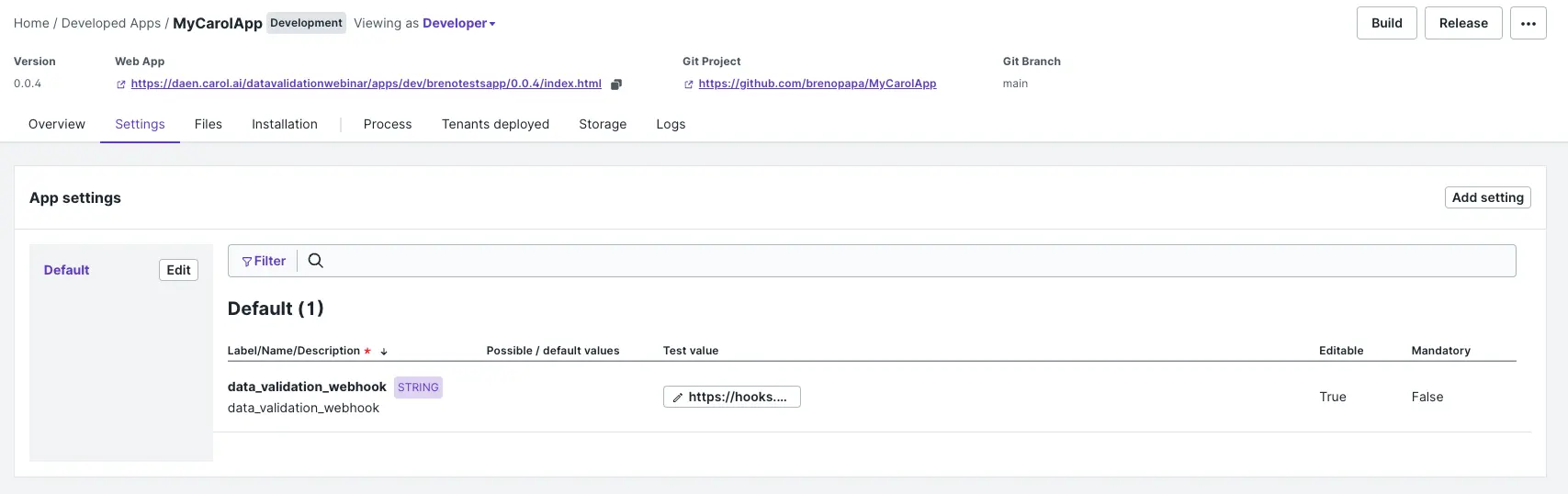 Imagem 7: exemplo de setting configurado para um WebHook.
Imagem 7: exemplo de setting configurado para um WebHook.
Os WebHooks homologados atualmente são Slack e Google Chat. Outros WebHooks podem ser inseridos no Carol App Setting, mas podem não enviar a mensagem corretamente.
Data Validation com o WebHook habilitado emite logs adicionais referentes ao status de envio da mensagem para o hook configurado. Caso o hook dê erro no envio da mensagem, a validação de dados não é interrompida. Apenas uma mensagem de Warning é mostrada no log.